 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Collaborative Advantage of Low-level Information on Generalizable AI-Generated Image Detection
Apr 01, 2025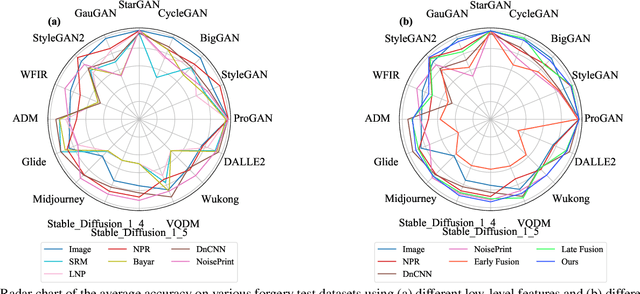
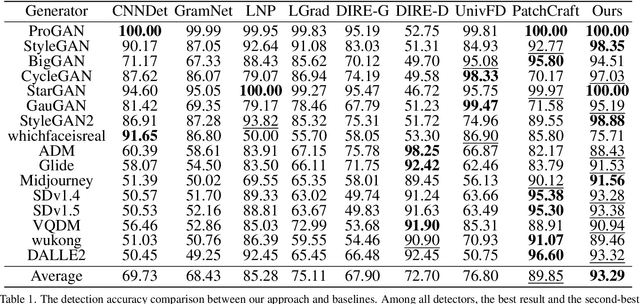
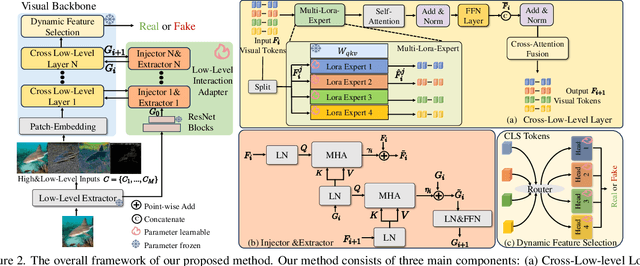
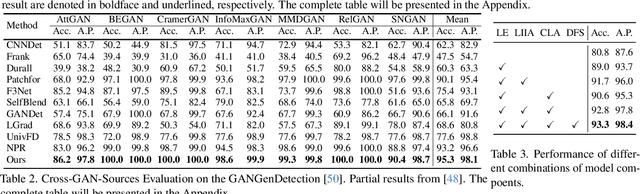
Existing state-of-the-art AI-Generated image detection methods mostly consider extracting low-level information from RGB images to help improve the generalization of AI-Generated image detection, such as noise patterns. However, these methods often consider only a single type of low-level information, which may lead to suboptimal generalization. Through empirical analysis, we have discovered a key insight: different low-level information often exhibits generalization capabilities for different types of forgeries. Furthermore, we found that simple fusion strategies are insufficient to leverage the detection advantages of each low-level and high-level information for various forgery types. Therefore, we propose the Adaptive Low-level Experts Injection (ALEI) framework. Our approach introduces Lora Experts, enabling the backbone network, which is trained with high-level semantic RGB images, to accept and learn knowledge from different low-level information. We utilize a cross-attention method to adaptively fuse these features at intermediate layers. To prevent the backbone network from losing the modeling capabilities of different low-level features during the later stages of modeling, we developed a Low-level Information Adapter that interacts with the features extracted by the backbone network. Finally, we propose Dynamic Feature Selection, which dynamically selects the most suitable features for detecting the current image to maximize generalization detection capability. Extensive experiments demonstrate that our method, finetuned on only four categories of mainstream ProGAN data, performs excellently and achieves state-of-the-art results on multiple datasets containing unseen GAN and Diffusion methods.
FocSAM: Delving Deeply into Focused Objects in Segmenting Anything
May 29, 2024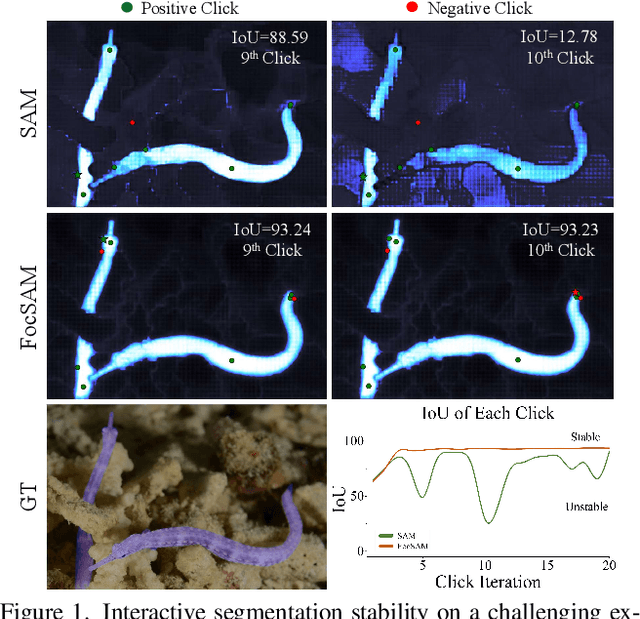
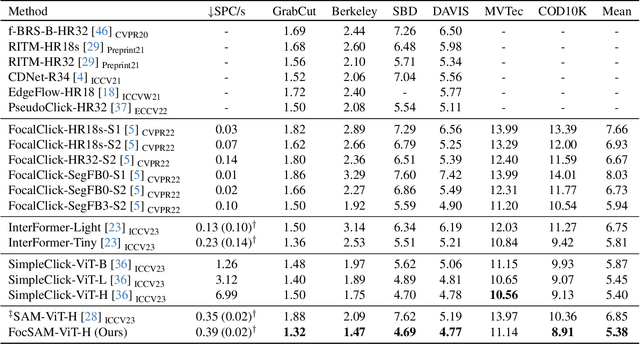
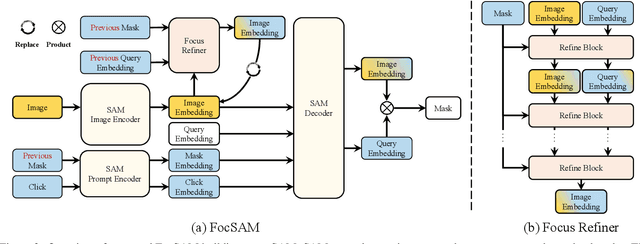

The Segment Anything Model (SAM) marks a notable milestone in segmentation models, highlighted by its robust zero-shot capabilities and ability to handle diverse prompts. SAM follows a pipeline that separates interactive segmentation into image preprocessing through a large encoder and interactive inference via a lightweight decoder, ensuring efficient real-time performance. However, SAM faces stability issues in challenging samples upon this pipeline. These issues arise from two main factors. Firstly, the image preprocessing disables SAM from dynamically using image-level zoom-in strategies to refocus on the target object during interaction. Secondly, the lightweight decoder struggles to sufficiently integrate interactive information with image embeddings. To address these two limitations, we propose FocSAM with a pipeline redesigned on two pivotal aspects. First, we propose Dynamic Window Multi-head Self-Attention (Dwin-MSA) to dynamically refocus SAM's image embeddings on the target object. Dwin-MSA localizes attention computations around the target object, enhancing object-related embeddings with minimal computational overhead. Second, we propose Pixel-wise Dynamic ReLU (P-DyReLU) to enable sufficient integration of interactive information from a few initial clicks that have significant impacts on the overall segmentation results. Experimentally, FocSAM augments SAM's interactive segmentation performance to match the existing state-of-the-art method in segmentation quality, requiring only about 5.6% of this method's inference time on CPUs.
DiffusionFace: Towards a Comprehensive Dataset for Diffusion-Based Face Forgery Analysis
Mar 27, 2024



The rapid progress in deep learning has given rise to hyper-realistic facial forgery methods, leading to concerns related to misinformation and security risks. Existing face forgery datasets have limitations in generating high-quality facial images and addressing the challenges posed by evolving generative techniques. To combat this, we present DiffusionFace, the first diffusion-based face forgery dataset, covering various forgery categories, including unconditional and Text Guide facial image generation, Img2Img, Inpaint, and Diffusion-based facial exchange algorithms. Our DiffusionFace dataset stands out with its extensive collection of 11 diffusion models and the high-quality of the generated images, providing essential metadata and a real-world internet-sourced forgery facial image dataset for evaluation. Additionally, we provide an in-depth analysis of the data and introduce practical evaluation protocols to rigorously assess discriminative models' effectiveness in detecting counterfeit facial images, aiming to enhance security in facial image authentication processes. The dataset is available for download at \url{https://github.com/Rapisurazurite/DiffFace}.
HODN: Disentangling Human-Object Feature for HOI Detection
Aug 20, 2023
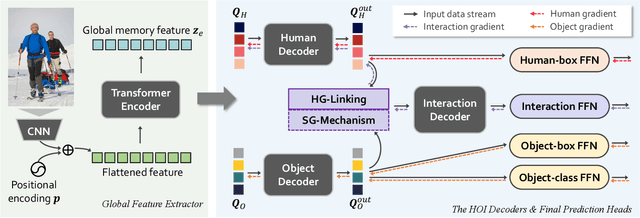
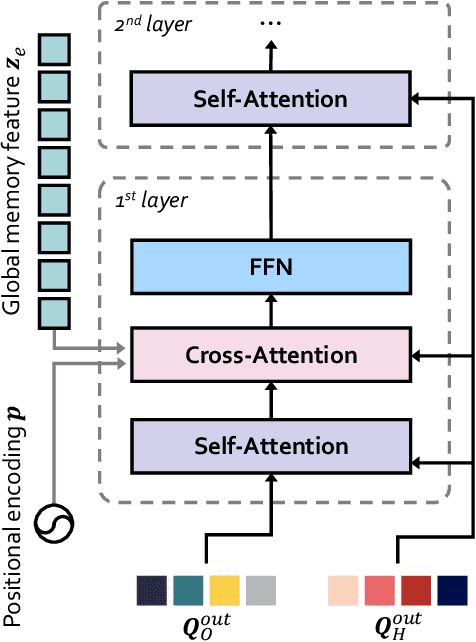
The task of Human-Object Interaction (HOI) detection is to detect humans and their interactions with surrounding objects, where transformer-based methods show dominant advances currently. However, these methods ignore the relationship among humans, objects, and interactions: 1) human features are more contributive than object ones to interaction prediction; 2) interactive information disturbs the detection of objects but helps human detection. In this paper, we propose a Human and Object Disentangling Network (HODN) to model the HOI relationships explicitly, where humans and objects are first detected by two disentangling decoders independently and then processed by an interaction decoder. Considering that human features are more contributive to interaction, we propose a Human-Guide Linking method to make sure the interaction decoder focuses on the human-centric regions with human features as the positional embeddings. To handle the opposite influences of interactions on humans and objects, we propose a Stop-Gradient Mechanism to stop interaction gradients from optimizing the object detection but to allow them to optimize the human detection. Our proposed method achieves competitive performance on both the V-COCO and the HICO-Det datasets. It can be combined with existing methods easily for state-of-the-art results.
Improving Human-Object Interaction Detection via Virtual Image Learning
Aug 04, 2023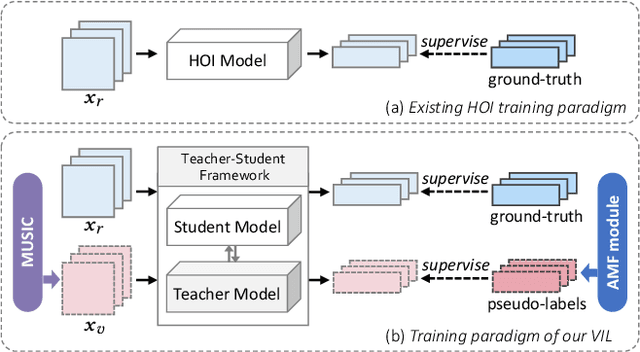
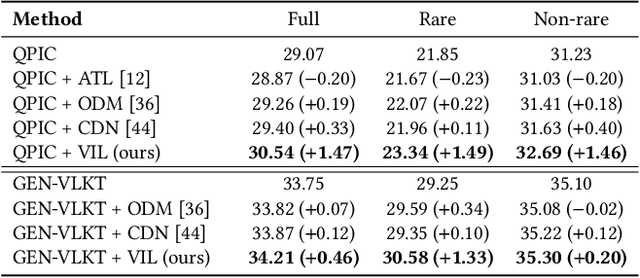
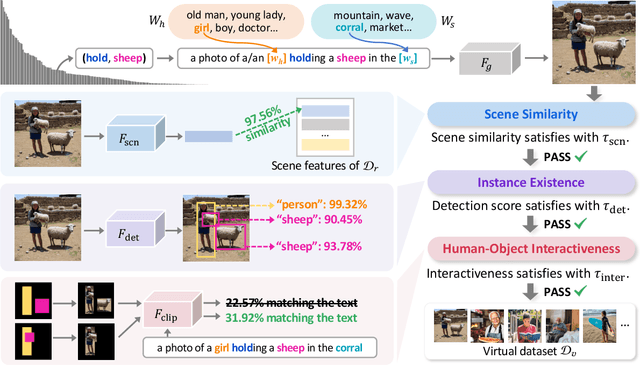
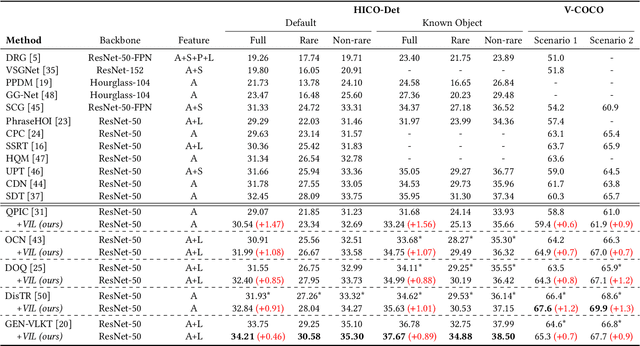
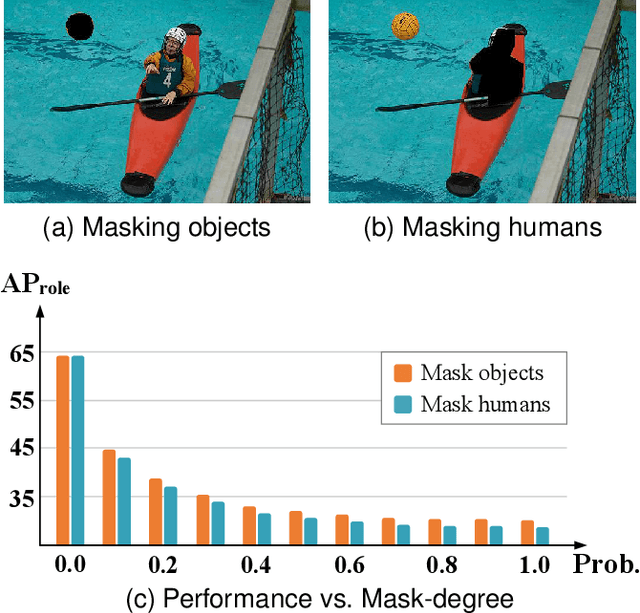
Human-Object Interaction (HOI) detection aims to understand the interactions between humans and objects, which plays a curtail role in high-level semantic understanding tasks. However, most works pursue designing better architectures to learn overall features more efficiently, while ignoring the long-tail nature of interaction-object pair categories. In this paper, we propose to alleviate the impact of such an unbalanced distribution via Virtual Image Leaning (VIL). Firstly, a novel label-to-image approach, Multiple Steps Image Creation (MUSIC), is proposed to create a high-quality dataset that has a consistent distribution with real images. In this stage, virtual images are generated based on prompts with specific characterizations and selected by multi-filtering processes. Secondly, we use both virtual and real images to train the model with the teacher-student framework. Considering the initial labels of some virtual images are inaccurate and inadequate, we devise an Adaptive Matching-and-Filtering (AMF) module to construct pseudo-labels. Our method is independent of the internal structure of HOI detectors, so it can be combined with off-the-shelf methods by training merely 10 additional epochs. With the assistance of our method, multiple methods obtain significant improvements, and new state-of-the-art results are achieved on two benchmarks.
CamoDiffusion: Camouflaged Object Detection via Conditional Diffusion Models
May 29, 2023



Camouflaged Object Detection (COD) is a challenging task in computer vision due to the high similarity between camouflaged objects and their surroundings. Existing COD methods primarily employ semantic segmentation, which suffers from overconfident incorrect predictions. In this paper, we propose a new paradigm that treats COD as a conditional mask-generation task leveraging diffusion models. Our method, dubbed CamoDiffusion, employs the denoising process of diffusion models to iteratively reduce the noise of the mask. Due to the stochastic sampling process of diffusion, our model is capable of sampling multiple possible predictions from the mask distribution, avoiding the problem of overconfident point estimation. Moreover, we develop specialized learning strategies that include an innovative ensemble approach for generating robust predictions and tailored forward diffusion methods for efficient training, specifically for the COD task. Extensive experiments on three COD datasets attest the superior performance of our model compared to existing state-of-the-art methods, particularly on the most challenging COD10K dataset, where our approach achieves 0.019 in terms of MAE.
Latent Feature Relation Consistency for Adversarial Robustness
Mar 29, 2023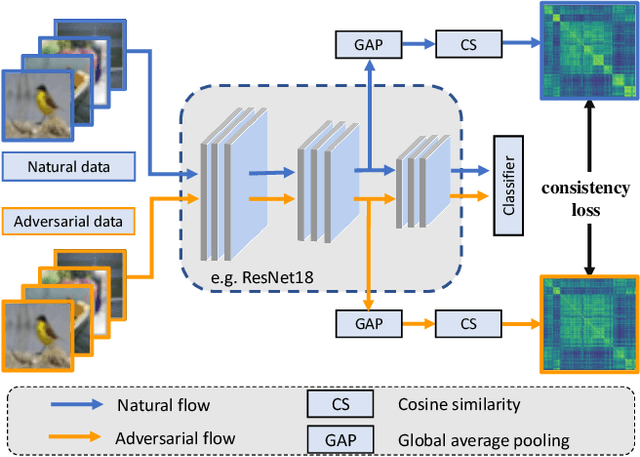
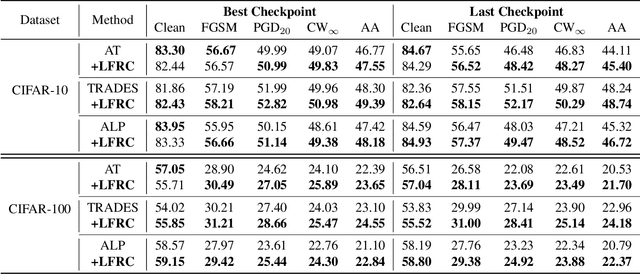
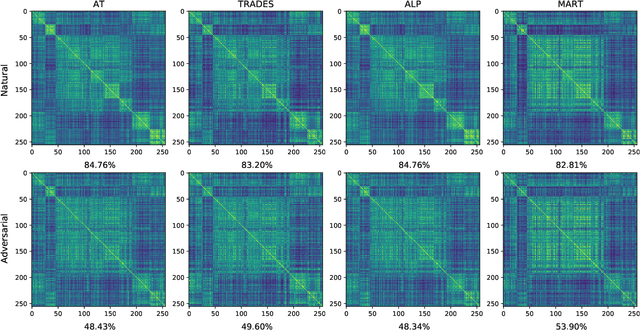
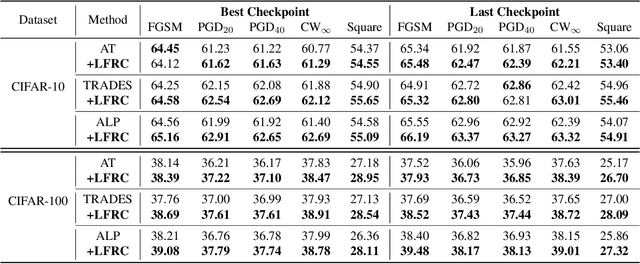
Deep neural networks have been applied in many computer vision tasks and achieved state-of-the-art performance. However, misclassification will occur when DNN predicts adversarial examples which add human-imperceptible adversarial noise to natural examples. This limits the application of DNN in security-critical fields. To alleviate this problem, we first conducted an empirical analysis of the latent features of both adversarial and natural examples and found the similarity matrix of natural examples is more compact than those of adversarial examples. Motivated by this observation, we propose \textbf{L}atent \textbf{F}eature \textbf{R}elation \textbf{C}onsistency (\textbf{LFRC}), which constrains the relation of adversarial examples in latent space to be consistent with the natural examples. Importantly, our LFRC is orthogonal to the previous method and can be easily combined with them to achieve further improvement. To demonstrate the effectiveness of LFRC, we conduct extensive experiments using different neural networks on benchmark datasets. For instance, LFRC can bring 0.78\% further improvement compared to AT, and 1.09\% improvement compared to TRADES, against AutoAttack on CIFAR10. Code is available at https://github.com/liuxingbin/LFRC.
CAT:Collaborative Adversarial Training
Mar 27, 2023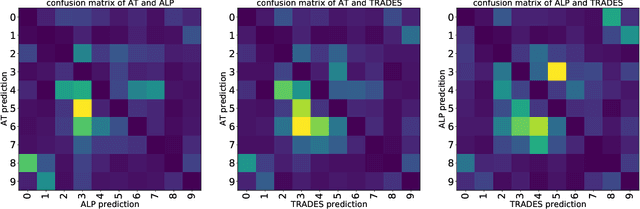
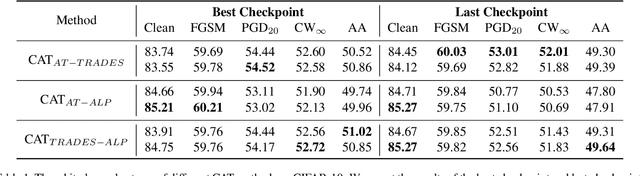
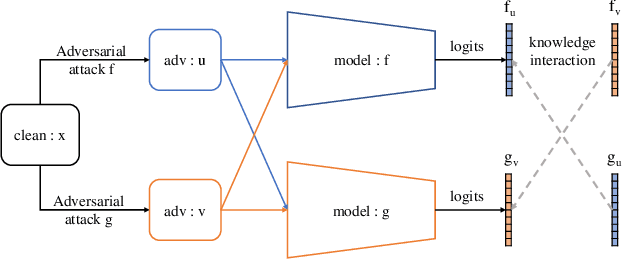
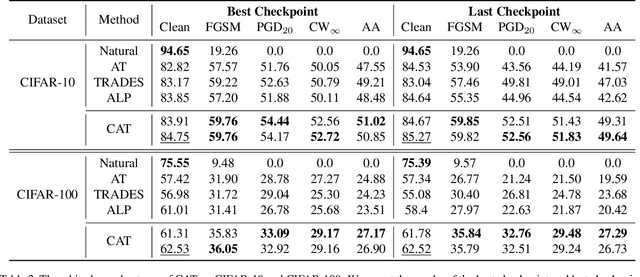
Adversarial training can improve the robustness of neural networks. Previous methods focus on a single adversarial training strategy and do not consider the model property trained by different strategies. By revisiting the previous methods, we find different adversarial training methods have distinct robustness for sample instances. For example, a sample instance can be correctly classified by a model trained using standard adversarial training (AT) but not by a model trained using TRADES, and vice versa. Based on this observation, we propose a collaborative adversarial training framework to improve the robustness of neural networks. Specifically, we use different adversarial training methods to train robust models and let models interact with their knowledge during the training process. Collaborative Adversarial Training (CAT) can improve both robustness and accuracy. Extensive experiments on various networks and datasets validate the effectiveness of our method. CAT achieves state-of-the-art adversarial robustness without using any additional data on CIFAR-10 under the Auto-Attack benchmark. Code is available at https://github.com/liuxingbin/CAT.
Exploring Invariant Representation for Visible-Infrared Person Re-Identification
Feb 02, 2023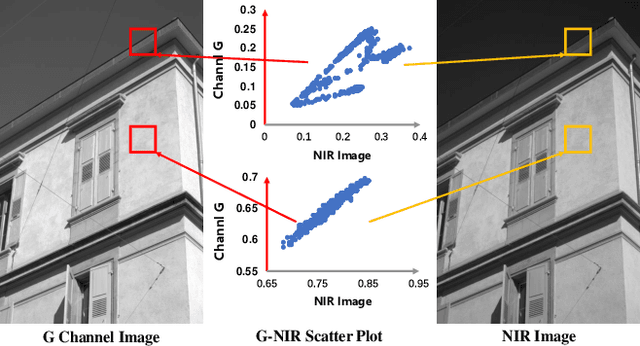

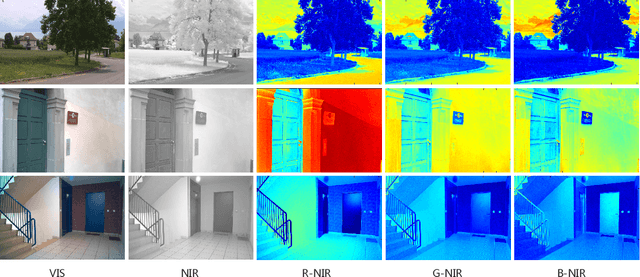

Cross-spectral person re-identification, which aims to associate identities to pedestrians across different spectra, faces a main challenge of the modality discrepancy. In this paper, we address the problem from both image-level and feature-level in an end-to-end hybrid learning framework named robust feature mining network (RFM). In particular, we observe that the reflective intensity of the same surface in photos shot in different wavelengths could be transformed using a linear model. Besides, we show the variable linear factor across the different surfaces is the main culprit which initiates the modality discrepancy. We integrate such a reflection observation into an image-level data augmentation by proposing the linear transformation generator (LTG). Moreover, at the feature level, we introduce a cross-center loss to explore a more compact intra-class distribution and modality-aware spatial attention to take advantage of textured regions more efficiently. Experiment results on two standard cross-spectral person re-identification datasets, i.e., RegDB and SYSU-MM01, have demonstrated state-of-the-art performance.
Exploring Target Representations for Masked Autoencoders
Sep 08, 2022
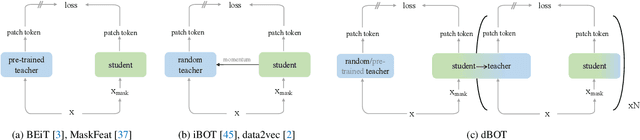
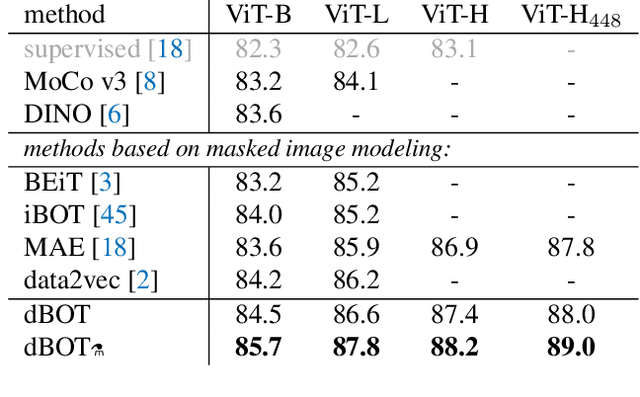
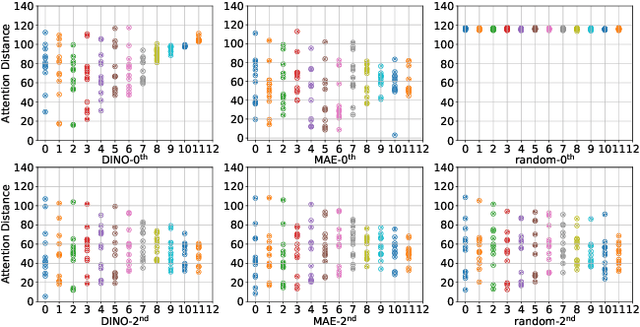
Masked autoencoders have become popular training paradigms for self-supervised visual representation learning. These models randomly mask a portion of the input and reconstruct the masked portion according to the target representations. In this paper, we first show that a careful choice of the target representation is unnecessary for learning good representations, since different targets tend to derive similarly behaved models. Driven by this observation, we propose a multi-stage masked distillation pipeline and use a randomly initialized model as the teacher, enabling us to effectively train high-capacity models without any efforts to carefully design target representations. Interestingly, we further explore using teachers of larger capacity, obtaining distilled students with remarkable transferring ability. On different tasks of classification, transfer learning, object detection, and semantic segmentation, the proposed method to perform masked knowledge distillation with bootstrapped teachers (dBOT) outperforms previous self-supervised methods by nontrivial margins. We hope our findings, as well as the proposed method, could motivate people to rethink the roles of target representations in pre-training masked autoencoders.