 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
Exploring Visual Pre-training for Robot Manipulation: Datasets, Models and Methods
Aug 07, 2023



Visual pre-training with large-scale real-world data has made great progress in recent years, showing great potential in robot learning with pixel observations. However, the recipes of visual pre-training for robot manipulation tasks are yet to be built. In this paper, we thoroughly investigate the effects of visual pre-training strategies on robot manipulation tasks from three fundamental perspectives: pre-training datasets, model architectures and training methods. Several significant experimental findings are provided that are beneficial for robot learning. Further, we propose a visual pre-training scheme for robot manipulation termed Vi-PRoM, which combines self-supervised learning and supervised learning. Concretely, the former employs contrastive learning to acquire underlying patterns from large-scale unlabeled data, while the latter aims learning visual semantics and temporal dynamics. Extensive experiments on robot manipulations in various simulation environments and the real robot demonstrate the superiority of the proposed scheme. Videos and more details can be found on \url{https://explore-pretrain-robot.github.io}.
Latent Feature Relation Consistency for Adversarial Robustness
Mar 29, 2023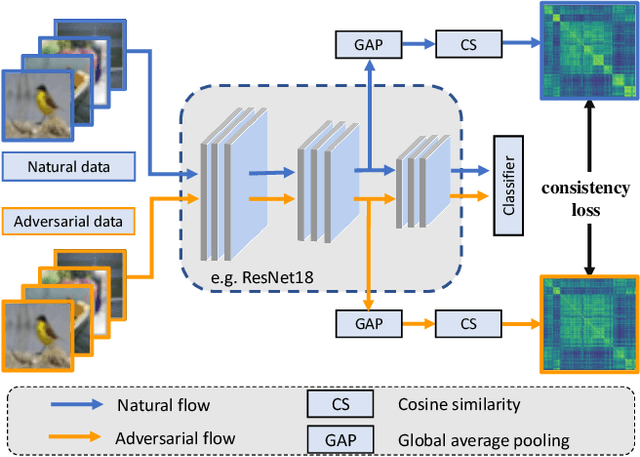
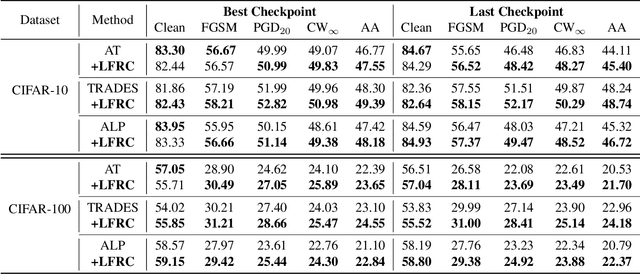
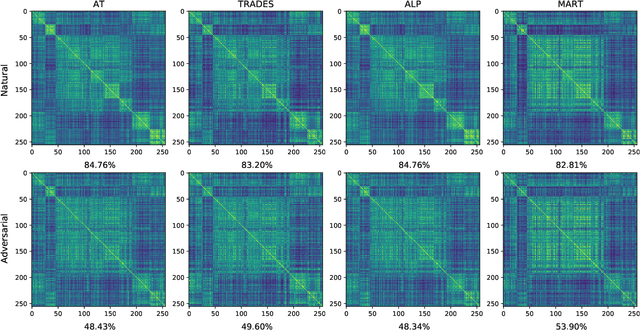
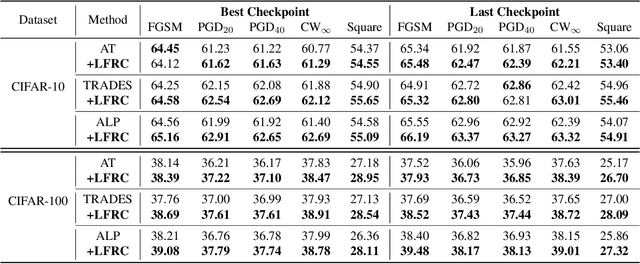
Deep neural networks have been applied in many computer vision tasks and achieved state-of-the-art performance. However, misclassification will occur when DNN predicts adversarial examples which add human-imperceptible adversarial noise to natural examples. This limits the application of DNN in security-critical fields. To alleviate this problem, we first conducted an empirical analysis of the latent features of both adversarial and natural examples and found the similarity matrix of natural examples is more compact than those of adversarial examples. Motivated by this observation, we propose \textbf{L}atent \textbf{F}eature \textbf{R}elation \textbf{C}onsistency (\textbf{LFRC}), which constrains the relation of adversarial examples in latent space to be consistent with the natural examples. Importantly, our LFRC is orthogonal to the previous method and can be easily combined with them to achieve further improvement. To demonstrate the effectiveness of LFRC, we conduct extensive experiments using different neural networks on benchmark datasets. For instance, LFRC can bring 0.78\% further improvement compared to AT, and 1.09\% improvement compared to TRADES, against AutoAttack on CIFAR10. Code is available at https://github.com/liuxingbin/LFRC.
CAT:Collaborative Adversarial Training
Mar 27, 2023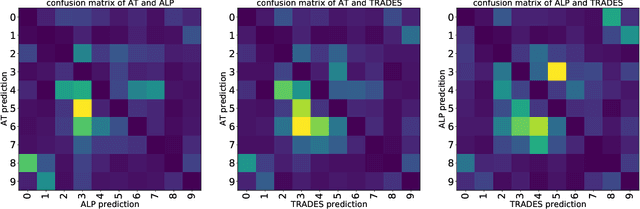
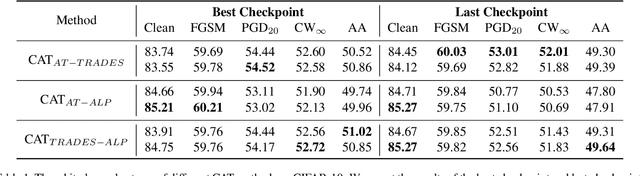
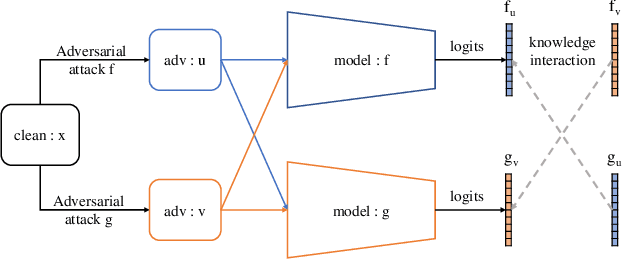
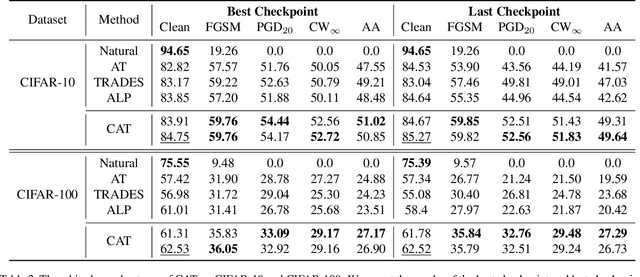
Adversarial training can improve the robustness of neural networks. Previous methods focus on a single adversarial training strategy and do not consider the model property trained by different strategies. By revisiting the previous methods, we find different adversarial training methods have distinct robustness for sample instances. For example, a sample instance can be correctly classified by a model trained using standard adversarial training (AT) but not by a model trained using TRADES, and vice versa. Based on this observation, we propose a collaborative adversarial training framework to improve the robustness of neural networks. Specifically, we use different adversarial training methods to train robust models and let models interact with their knowledge during the training process. Collaborative Adversarial Training (CAT) can improve both robustness and accuracy. Extensive experiments on various networks and datasets validate the effectiveness of our method. CAT achieves state-of-the-art adversarial robustness without using any additional data on CIFAR-10 under the Auto-Attack benchmark. Code is available at https://github.com/liuxingbin/CAT.
Exploring Target Representations for Masked Autoencoders
Sep 08, 2022
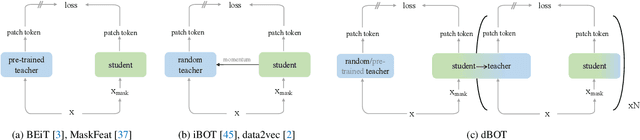
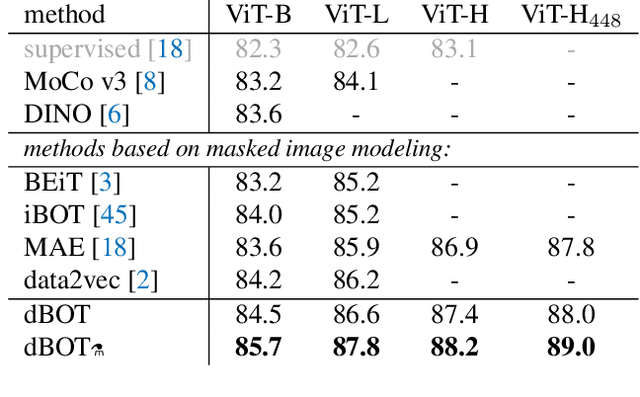
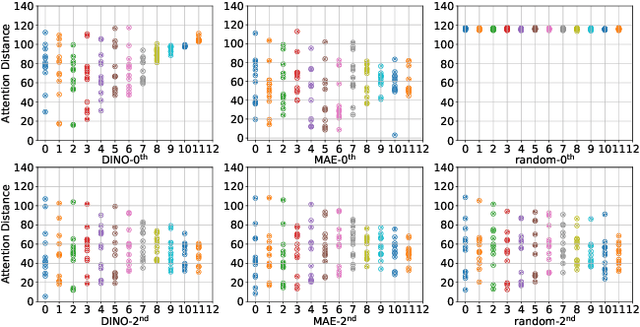
Masked autoencoders have become popular training paradigms for self-supervised visual representation learning. These models randomly mask a portion of the input and reconstruct the masked portion according to the target representations. In this paper, we first show that a careful choice of the target representation is unnecessary for learning good representations, since different targets tend to derive similarly behaved models. Driven by this observation, we propose a multi-stage masked distillation pipeline and use a randomly initialized model as the teacher, enabling us to effectively train high-capacity models without any efforts to carefully design target representations. Interestingly, we further explore using teachers of larger capacity, obtaining distilled students with remarkable transferring ability. On different tasks of classification, transfer learning, object detection, and semantic segmentation, the proposed method to perform masked knowledge distillation with bootstrapped teachers (dBOT) outperforms previous self-supervised methods by nontrivial margins. We hope our findings, as well as the proposed method, could motivate people to rethink the roles of target representations in pre-training masked autoencoders.