 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeaweed-7B: Cost-Effective Training of Video Generation Foundation Model
Apr 11, 2025
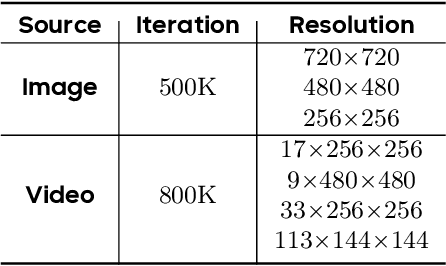
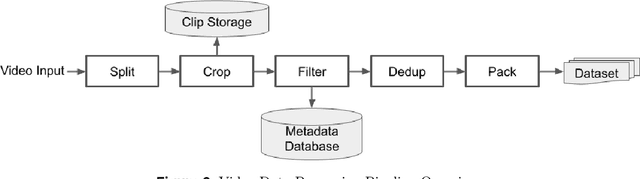

This technical report presents a cost-efficient strategy for training a video generation foundation model. We present a mid-sized research model with approximately 7 billion parameters (7B) called Seaweed-7B trained from scratch using 665,000 H100 GPU hours. Despite being trained with moderate computational resources, Seaweed-7B demonstrates highly competitive performance compared to contemporary video generation models of much larger size. Design choices are especially crucial in a resource-constrained setting. This technical report highlights the key design decisions that enhance the performance of the medium-sized diffusion model. Empirically, we make two observations: (1) Seaweed-7B achieves performance comparable to, or even surpasses, larger models trained on substantially greater GPU resources, and (2) our model, which exhibits strong generalization ability, can be effectively adapted across a wide range of downstream applications either by lightweight fine-tuning or continue training. See the project page at https://seaweed.video/
TraDiffusion: Trajectory-Based Training-Free Image Generation
Aug 19, 2024



In this work, we propose a training-free, trajectory-based controllable T2I approach, termed TraDiffusion. This novel method allows users to effortlessly guide image generation via mouse trajectories. To achieve precise control, we design a distance awareness energy function to effectively guide latent variables, ensuring that the focus of generation is within the areas defined by the trajectory. The energy function encompasses a control function to draw the generation closer to the specified trajectory and a movement function to diminish activity in areas distant from the trajectory. Through extensive experiments and qualitative assessments on the COCO dataset, the results reveal that TraDiffusion facilitates simpler, more natural image control. Moreover, it showcases the ability to manipulate salient regions, attributes, and relationships within the generated images, alongside visual input based on arbitrary or enhanced trajectories.
StealthDiffusion: Towards Evading Diffusion Forensic Detection through Diffusion Model
Aug 11, 2024The rapid progress in generative models has given rise to the critical task of AI-Generated Content Stealth (AIGC-S), which aims to create AI-generated images that can evade both forensic detectors and human inspection. This task is crucial for understanding the vulnerabilities of existing detection methods and developing more robust techniques. However, current adversarial attacks often introduce visible noise, have poor transferability, and fail to address spectral differences between AI-generated and genuine images. To address this, we propose StealthDiffusion, a framework based on stable diffusion that modifies AI-generated images into high-quality, imperceptible adversarial examples capable of evading state-of-the-art forensic detectors. StealthDiffusion comprises two main components: Latent Adversarial Optimization, which generates adversarial perturbations in the latent space of stable diffusion, and Control-VAE, a module that reduces spectral differences between the generated adversarial images and genuine images without affecting the original diffusion model's generation process. Extensive experiments show that StealthDiffusion is effective in both white-box and black-box settings, transforming AI-generated images into high-quality adversarial forgeries with frequency spectra similar to genuine images. These forgeries are classified as genuine by advanced forensic classifiers and are difficult for humans to distinguish.
ControlNet++: Improving Conditional Controls with Efficient Consistency Feedback
Apr 11, 2024
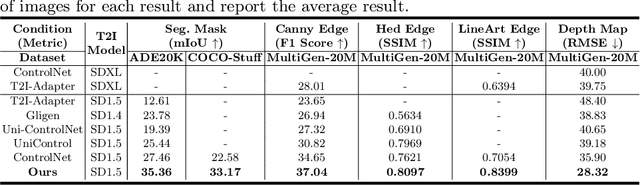
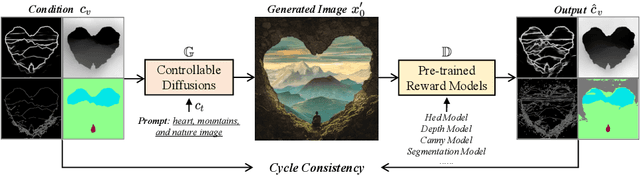
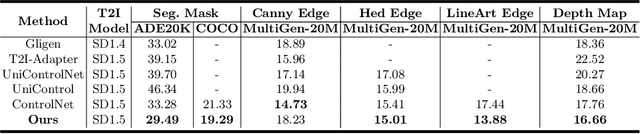
To enhance the controllability of text-to-image diffusion models, existing efforts like ControlNet incorporated image-based conditional controls. In this paper, we reveal that existing methods still face significant challenges in generating images that align with the image conditional controls. To this end, we propose ControlNet++, a novel approach that improves controllable generation by explicitly optimizing pixel-level cycle consistency between generated images and conditional controls. Specifically, for an input conditional control, we use a pre-trained discriminative reward model to extract the corresponding condition of the generated images, and then optimize the consistency loss between the input conditional control and extracted condition. A straightforward implementation would be generating images from random noises and then calculating the consistency loss, but such an approach requires storing gradients for multiple sampling timesteps, leading to considerable time and memory costs. To address this, we introduce an efficient reward strategy that deliberately disturbs the input images by adding noise, and then uses the single-step denoised images for reward fine-tuning. This avoids the extensive costs associated with image sampling, allowing for more efficient reward fine-tuning. Extensive experiments show that ControlNet++ significantly improves controllability under various conditional controls. For example, it achieves improvements over ControlNet by 7.9% mIoU, 13.4% SSIM, and 7.6% RMSE, respectively, for segmentation mask, line-art edge, and depth conditions.
UniFL: Improve Stable Diffusion via Unified Feedback Learning
Apr 08, 2024



Diffusion models have revolutionized the field of image generation, leading to the proliferation of high-quality models and diverse downstream applications. However, despite these significant advancements, the current competitive solutions still suffer from several limitations, including inferior visual quality, a lack of aesthetic appeal, and inefficient inference, without a comprehensive solution in sight. To address these challenges, we present UniFL, a unified framework that leverages feedback learning to enhance diffusion models comprehensively. UniFL stands out as a universal, effective, and generalizable solution applicable to various diffusion models, such as SD1.5 and SDXL. Notably, UniFL incorporates three key components: perceptual feedback learning, which enhances visual quality; decoupled feedback learning, which improves aesthetic appeal; and adversarial feedback learning, which optimizes inference speed. In-depth experiments and extensive user studies validate the superior performance of our proposed method in enhancing both the quality of generated models and their acceleration. For instance, UniFL surpasses ImageReward by 17% user preference in terms of generation quality and outperforms LCM and SDXL Turbo by 57% and 20% in 4-step inference. Moreover, we have verified the efficacy of our approach in downstream tasks, including Lora, ControlNet, and AnimateDiff.
ByteEdit: Boost, Comply and Accelerate Generative Image Editing
Apr 07, 2024



Recent advancements in diffusion-based generative image editing have sparked a profound revolution, reshaping the landscape of image outpainting and inpainting tasks. Despite these strides, the field grapples with inherent challenges, including: i) inferior quality; ii) poor consistency; iii) insufficient instrcution adherence; iv) suboptimal generation efficiency. To address these obstacles, we present ByteEdit, an innovative feedback learning framework meticulously designed to Boost, Comply, and Accelerate Generative Image Editing tasks. ByteEdit seamlessly integrates image reward models dedicated to enhancing aesthetics and image-text alignment, while also introducing a dense, pixel-level reward model tailored to foster coherence in the output. Furthermore, we propose a pioneering adversarial and progressive feedback learning strategy to expedite the model's inference speed. Through extensive large-scale user evaluations, we demonstrate that ByteEdit surpasses leading generative image editing products, including Adobe, Canva, and MeiTu, in both generation quality and consistency. ByteEdit-Outpainting exhibits a remarkable enhancement of 388% and 135% in quality and consistency, respectively, when compared to the baseline model. Experiments also verfied that our acceleration models maintains excellent performance results in terms of quality and consistency.
DLIP: Distilling Language-Image Pre-training
Aug 24, 2023



Vision-Language Pre-training (VLP) shows remarkable progress with the assistance of extremely heavy parameters, which challenges deployment in real applications. Knowledge distillation is well recognized as the essential procedure in model compression. However, existing knowledge distillation techniques lack an in-depth investigation and analysis of VLP, and practical guidelines for VLP-oriented distillation are still not yet explored. In this paper, we present DLIP, a simple yet efficient Distilling Language-Image Pre-training framework, through which we investigate how to distill a light VLP model. Specifically, we dissect the model distillation from multiple dimensions, such as the architecture characteristics of different modules and the information transfer of different modalities. We conduct comprehensive experiments and provide insights on distilling a light but performant VLP model. Experimental results reveal that DLIP can achieve a state-of-the-art accuracy/efficiency trade-off across diverse cross-modal tasks, e.g., image-text retrieval, image captioning and visual question answering. For example, DLIP compresses BLIP by 1.9x, from 213M to 108M parameters, while achieving comparable or better performance. Furthermore, DLIP succeeds in retaining more than 95% of the performance with 22.4% parameters and 24.8% FLOPs compared to the teacher model and accelerates inference speed by 2.7x.
Latent Feature Relation Consistency for Adversarial Robustness
Mar 29, 2023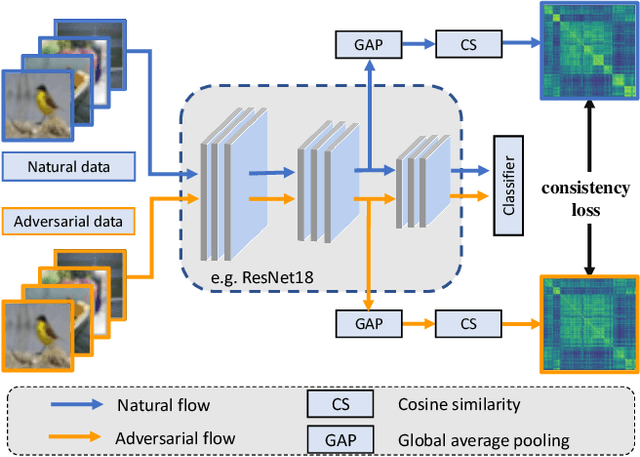
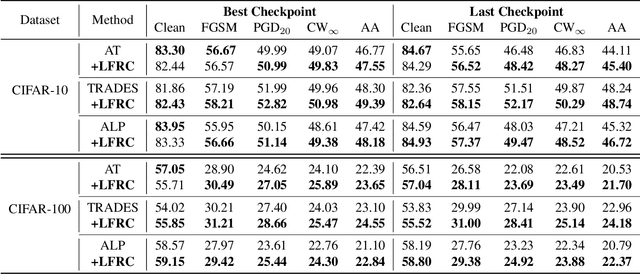
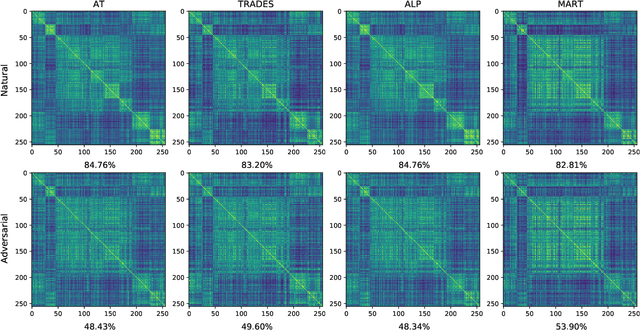
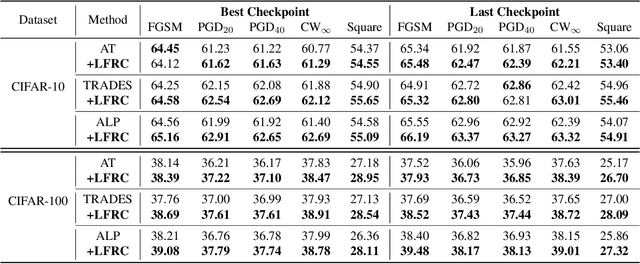
Deep neural networks have been applied in many computer vision tasks and achieved state-of-the-art performance. However, misclassification will occur when DNN predicts adversarial examples which add human-imperceptible adversarial noise to natural examples. This limits the application of DNN in security-critical fields. To alleviate this problem, we first conducted an empirical analysis of the latent features of both adversarial and natural examples and found the similarity matrix of natural examples is more compact than those of adversarial examples. Motivated by this observation, we propose \textbf{L}atent \textbf{F}eature \textbf{R}elation \textbf{C}onsistency (\textbf{LFRC}), which constrains the relation of adversarial examples in latent space to be consistent with the natural examples. Importantly, our LFRC is orthogonal to the previous method and can be easily combined with them to achieve further improvement. To demonstrate the effectiveness of LFRC, we conduct extensive experiments using different neural networks on benchmark datasets. For instance, LFRC can bring 0.78\% further improvement compared to AT, and 1.09\% improvement compared to TRADES, against AutoAttack on CIFAR10. Code is available at https://github.com/liuxingbin/LFRC.
CAT:Collaborative Adversarial Training
Mar 27, 2023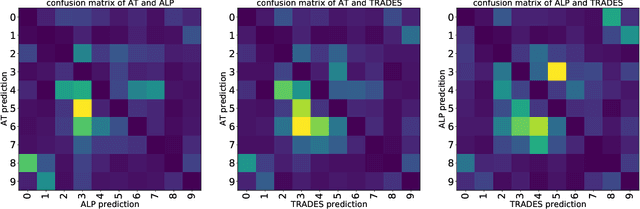
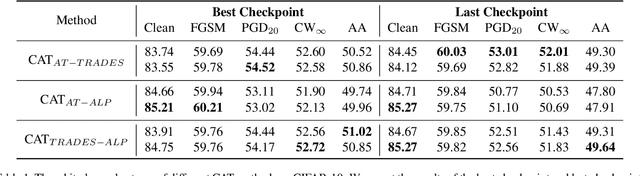
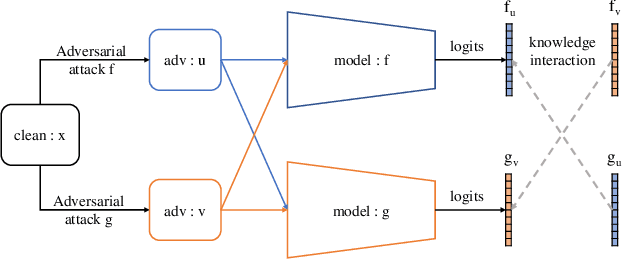
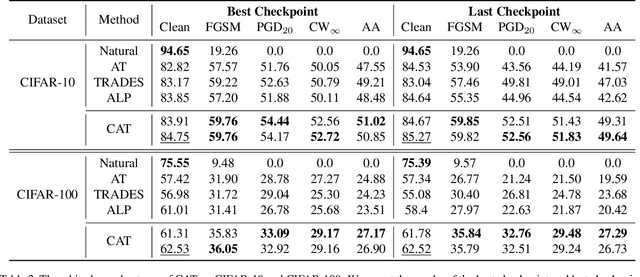
Adversarial training can improve the robustness of neural networks. Previous methods focus on a single adversarial training strategy and do not consider the model property trained by different strategies. By revisiting the previous methods, we find different adversarial training methods have distinct robustness for sample instances. For example, a sample instance can be correctly classified by a model trained using standard adversarial training (AT) but not by a model trained using TRADES, and vice versa. Based on this observation, we propose a collaborative adversarial training framework to improve the robustness of neural networks. Specifically, we use different adversarial training methods to train robust models and let models interact with their knowledge during the training process. Collaborative Adversarial Training (CAT) can improve both robustness and accuracy. Extensive experiments on various networks and datasets validate the effectiveness of our method. CAT achieves state-of-the-art adversarial robustness without using any additional data on CIFAR-10 under the Auto-Attack benchmark. Code is available at https://github.com/liuxingbin/CAT.