 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniGRPO: Unified Policy Optimization for Reasoning-Driven Visual Generation
Mar 24, 2026Unified models capable of interleaved generation have emerged as a promising paradigm, with the community increasingly converging on autoregressive modeling for text and flow matching for image generation. To advance this direction, we propose a unified reinforcement learning framework tailored for interleaved generation. We validate our approach on its fundamental unit: a single round of reasoning-driven image generation, where the model first expands the user prompt through reasoning, followed by image synthesis. Formulating this multimodal generation process as a Markov Decision Process with sparse terminal rewards, we introduce UniGRPO to jointly optimize text and image generation policies using GRPO. Adopting a minimalist methodology to avoid over-design, we leverage established training recipes for both modalities by seamlessly integrating standard GRPO for reasoning and FlowGRPO for visual synthesis. To ensure scalability to multi-round interleaved generation, we introduce two critical modifications to the original FlowGRPO: (1) eliminating classifier-free guidance to maintain linear, unbranched rollouts, which is essential for scaling to complex scenarios involving multi-turn interactions and multi-condition generation (e.g., editing); and (2) replacing the standard latent KL penalty with an MSE penalty directly on the velocity fields, providing a more robust and direct regularization signal to mitigate reward hacking effectively. Our experiments demonstrate that this unified training recipe significantly enhances image generation quality through reasoning, providing a robust and scalable baseline for the future post-training of fully interleaved models.
OneReward: Unified Mask-Guided Image Generation via Multi-Task Human Preference Learning
Aug 28, 2025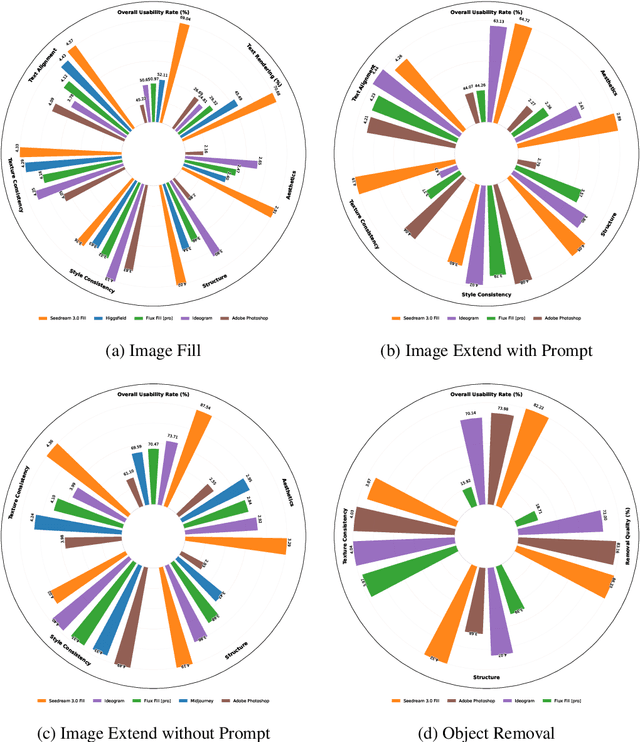

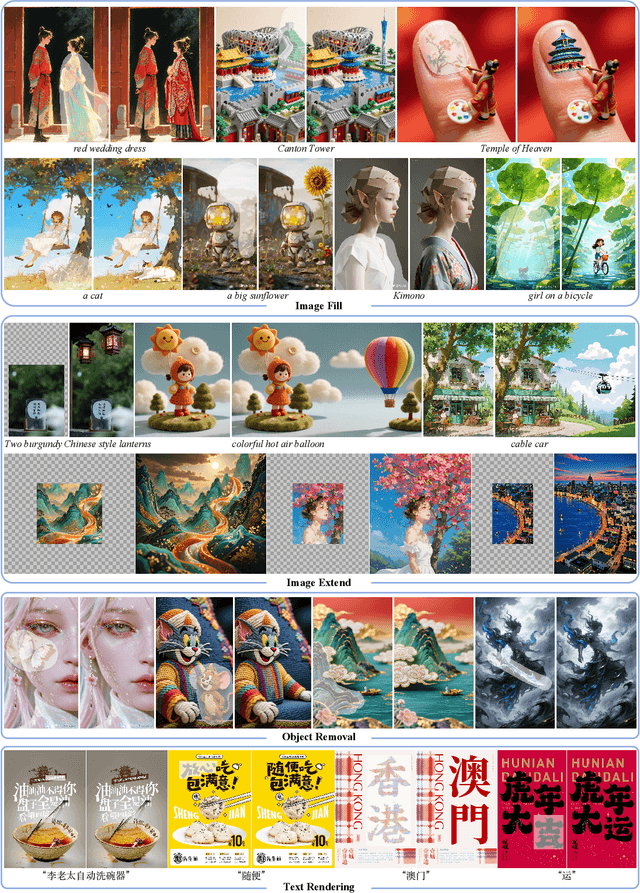
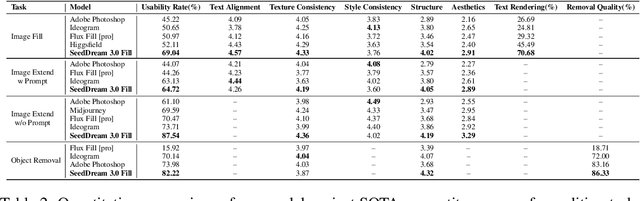
In this paper, we introduce OneReward, a unified reinforcement learning framework that enhances the model's generative capabilities across multiple tasks under different evaluation criteria using only \textit{One Reward} model. By employing a single vision-language model (VLM) as the generative reward model, which can distinguish the winner and loser for a given task and a given evaluation criterion, it can be effectively applied to multi-task generation models, particularly in contexts with varied data and diverse task objectives. We utilize OneReward for mask-guided image generation, which can be further divided into several sub-tasks such as image fill, image extend, object removal, and text rendering, involving a binary mask as the edit area. Although these domain-specific tasks share same conditioning paradigm, they differ significantly in underlying data distributions and evaluation metrics. Existing methods often rely on task-specific supervised fine-tuning (SFT), which limits generalization and training efficiency. Building on OneReward, we develop Seedream 3.0 Fill, a mask-guided generation model trained via multi-task reinforcement learning directly on a pre-trained base model, eliminating the need for task-specific SFT. Experimental results demonstrate that our unified edit model consistently outperforms both commercial and open-source competitors, such as Ideogram, Adobe Photoshop, and FLUX Fill [Pro], across multiple evaluation dimensions. Code and model are available at: https://one-reward.github.io
ByteEdit: Boost, Comply and Accelerate Generative Image Editing
Apr 07, 2024



Recent advancements in diffusion-based generative image editing have sparked a profound revolution, reshaping the landscape of image outpainting and inpainting tasks. Despite these strides, the field grapples with inherent challenges, including: i) inferior quality; ii) poor consistency; iii) insufficient instrcution adherence; iv) suboptimal generation efficiency. To address these obstacles, we present ByteEdit, an innovative feedback learning framework meticulously designed to Boost, Comply, and Accelerate Generative Image Editing tasks. ByteEdit seamlessly integrates image reward models dedicated to enhancing aesthetics and image-text alignment, while also introducing a dense, pixel-level reward model tailored to foster coherence in the output. Furthermore, we propose a pioneering adversarial and progressive feedback learning strategy to expedite the model's inference speed. Through extensive large-scale user evaluations, we demonstrate that ByteEdit surpasses leading generative image editing products, including Adobe, Canva, and MeiTu, in both generation quality and consistency. ByteEdit-Outpainting exhibits a remarkable enhancement of 388% and 135% in quality and consistency, respectively, when compared to the baseline model. Experiments also verfied that our acceleration models maintains excellent performance results in terms of quality and consistency.
AlignDet: Aligning Pre-training and Fine-tuning in Object Detection
Jul 20, 2023The paradigm of large-scale pre-training followed by downstream fine-tuning has been widely employed in various object detection algorithms. In this paper, we reveal discrepancies in data, model, and task between the pre-training and fine-tuning procedure in existing practices, which implicitly limit the detector's performance, generalization ability, and convergence speed. To this end, we propose AlignDet, a unified pre-training framework that can be adapted to various existing detectors to alleviate the discrepancies. AlignDet decouples the pre-training process into two stages, i.e., image-domain and box-domain pre-training. The image-domain pre-training optimizes the detection backbone to capture holistic visual abstraction, and box-domain pre-training learns instance-level semantics and task-aware concepts to initialize the parts out of the backbone. By incorporating the self-supervised pre-trained backbones, we can pre-train all modules for various detectors in an unsupervised paradigm. As depicted in Figure 1, extensive experiments demonstrate that AlignDet can achieve significant improvements across diverse protocols, such as detection algorithm, model backbone, data setting, and training schedule. For example, AlignDet improves FCOS by 5.3 mAP, RetinaNet by 2.1 mAP, Faster R-CNN by 3.3 mAP, and DETR by 2.3 mAP under fewer epochs.