 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALIVE: Animate Your World with Lifelike Audio-Video Generation
Feb 09, 2026Video generation is rapidly evolving towards unified audio-video generation. In this paper, we present ALIVE, a generation model that adapts a pretrained Text-to-Video (T2V) model to Sora-style audio-video generation and animation. In particular, the model unlocks the Text-to-Video&Audio (T2VA) and Reference-to-Video&Audio (animation) capabilities compared to the T2V foundation models. To support the audio-visual synchronization and reference animation, we augment the popular MMDiT architecture with a joint audio-video branch which includes TA-CrossAttn for temporally-aligned cross-modal fusion and UniTemp-RoPE for precise audio-visual alignment. Meanwhile, a comprehensive data pipeline consisting of audio-video captioning, quality control, etc., is carefully designed to collect high-quality finetuning data. Additionally, we introduce a new benchmark to perform a comprehensive model test and comparison. After continue pretraining and finetuning on million-level high-quality data, ALIVE demonstrates outstanding performance, consistently outperforming open-source models and matching or surpassing state-of-the-art commercial solutions. With detailed recipes and benchmarks, we hope ALIVE helps the community develop audio-video generation models more efficiently. Official page: https://github.com/FoundationVision/Alive.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
HumanDiT: Pose-Guided Diffusion Transformer for Long-form Human Motion Video Generation
Feb 10, 2025



Human motion video generation has advanced significantly, while existing methods still struggle with accurately rendering detailed body parts like hands and faces, especially in long sequences and intricate motions. Current approaches also rely on fixed resolution and struggle to maintain visual consistency. To address these limitations, we propose HumanDiT, a pose-guided Diffusion Transformer (DiT)-based framework trained on a large and wild dataset containing 14,000 hours of high-quality video to produce high-fidelity videos with fine-grained body rendering. Specifically, (i) HumanDiT, built on DiT, supports numerous video resolutions and variable sequence lengths, facilitating learning for long-sequence video generation; (ii) we introduce a prefix-latent reference strategy to maintain personalized characteristics across extended sequences. Furthermore, during inference, HumanDiT leverages Keypoint-DiT to generate subsequent pose sequences, facilitating video continuation from static images or existing videos. It also utilizes a Pose Adapter to enable pose transfer with given sequences. Extensive experiments demonstrate its superior performance in generating long-form, pose-accurate videos across diverse scenarios.
Hyper-SD: Trajectory Segmented Consistency Model for Efficient Image Synthesis
Apr 21, 2024



Recently, a series of diffusion-aware distillation algorithms have emerged to alleviate the computational overhead associated with the multi-step inference process of Diffusion Models (DMs). Current distillation techniques often dichotomize into two distinct aspects: i) ODE Trajectory Preservation; and ii) ODE Trajectory Reformulation. However, these approaches suffer from severe performance degradation or domain shifts. To address these limitations, we propose Hyper-SD, a novel framework that synergistically amalgamates the advantages of ODE Trajectory Preservation and Reformulation, while maintaining near-lossless performance during step compression. Firstly, we introduce Trajectory Segmented Consistency Distillation to progressively perform consistent distillation within pre-defined time-step segments, which facilitates the preservation of the original ODE trajectory from a higher-order perspective. Secondly, we incorporate human feedback learning to boost the performance of the model in a low-step regime and mitigate the performance loss incurred by the distillation process. Thirdly, we integrate score distillation to further improve the low-step generation capability of the model and offer the first attempt to leverage a unified LoRA to support the inference process at all steps. Extensive experiments and user studies demonstrate that Hyper-SD achieves SOTA performance from 1 to 8 inference steps for both SDXL and SD1.5. For example, Hyper-SDXL surpasses SDXL-Lightning by +0.68 in CLIP Score and +0.51 in Aes Score in the 1-step inference.
UniFL: Improve Stable Diffusion via Unified Feedback Learning
Apr 08, 2024



Diffusion models have revolutionized the field of image generation, leading to the proliferation of high-quality models and diverse downstream applications. However, despite these significant advancements, the current competitive solutions still suffer from several limitations, including inferior visual quality, a lack of aesthetic appeal, and inefficient inference, without a comprehensive solution in sight. To address these challenges, we present UniFL, a unified framework that leverages feedback learning to enhance diffusion models comprehensively. UniFL stands out as a universal, effective, and generalizable solution applicable to various diffusion models, such as SD1.5 and SDXL. Notably, UniFL incorporates three key components: perceptual feedback learning, which enhances visual quality; decoupled feedback learning, which improves aesthetic appeal; and adversarial feedback learning, which optimizes inference speed. In-depth experiments and extensive user studies validate the superior performance of our proposed method in enhancing both the quality of generated models and their acceleration. For instance, UniFL surpasses ImageReward by 17% user preference in terms of generation quality and outperforms LCM and SDXL Turbo by 57% and 20% in 4-step inference. Moreover, we have verified the efficacy of our approach in downstream tasks, including Lora, ControlNet, and AnimateDiff.
ByteEdit: Boost, Comply and Accelerate Generative Image Editing
Apr 07, 2024



Recent advancements in diffusion-based generative image editing have sparked a profound revolution, reshaping the landscape of image outpainting and inpainting tasks. Despite these strides, the field grapples with inherent challenges, including: i) inferior quality; ii) poor consistency; iii) insufficient instrcution adherence; iv) suboptimal generation efficiency. To address these obstacles, we present ByteEdit, an innovative feedback learning framework meticulously designed to Boost, Comply, and Accelerate Generative Image Editing tasks. ByteEdit seamlessly integrates image reward models dedicated to enhancing aesthetics and image-text alignment, while also introducing a dense, pixel-level reward model tailored to foster coherence in the output. Furthermore, we propose a pioneering adversarial and progressive feedback learning strategy to expedite the model's inference speed. Through extensive large-scale user evaluations, we demonstrate that ByteEdit surpasses leading generative image editing products, including Adobe, Canva, and MeiTu, in both generation quality and consistency. ByteEdit-Outpainting exhibits a remarkable enhancement of 388% and 135% in quality and consistency, respectively, when compared to the baseline model. Experiments also verfied that our acceleration models maintains excellent performance results in terms of quality and consistency.
ResAdapter: Domain Consistent Resolution Adapter for Diffusion Models
Mar 04, 2024



Recent advancement in text-to-image models (e.g., Stable Diffusion) and corresponding personalized technologies (e.g., DreamBooth and LoRA) enables individuals to generate high-quality and imaginative images. However, they often suffer from limitations when generating images with resolutions outside of their trained domain. To overcome this limitation, we present the Resolution Adapter (ResAdapter), a domain-consistent adapter designed for diffusion models to generate images with unrestricted resolutions and aspect ratios. Unlike other multi-resolution generation methods that process images of static resolution with complex post-process operations, ResAdapter directly generates images with the dynamical resolution. Especially, after learning a deep understanding of pure resolution priors, ResAdapter trained on the general dataset, generates resolution-free images with personalized diffusion models while preserving their original style domain. Comprehensive experiments demonstrate that ResAdapter with only 0.5M can process images with flexible resolutions for arbitrary diffusion models. More extended experiments demonstrate that ResAdapter is compatible with other modules (e.g., ControlNet, IP-Adapter and LCM-LoRA) for image generation across a broad range of resolutions, and can be integrated into other multi-resolution model (e.g., ElasticDiffusion) for efficiently generating higher-resolution images. Project link is https://res-adapter.github.io
Modeling Balanced Explicit and Implicit Relations with Contrastive Learning for Knowledge Concept Recommendation in MOOCs
Feb 13, 2024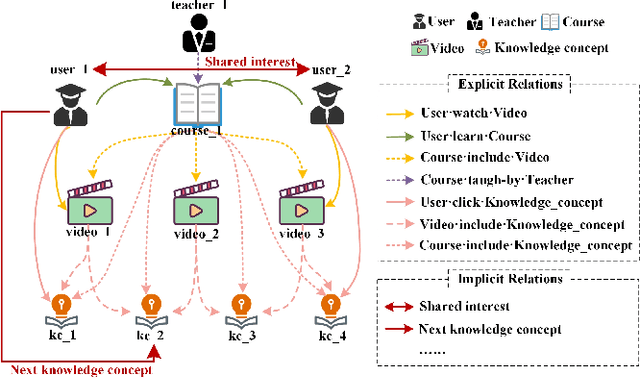
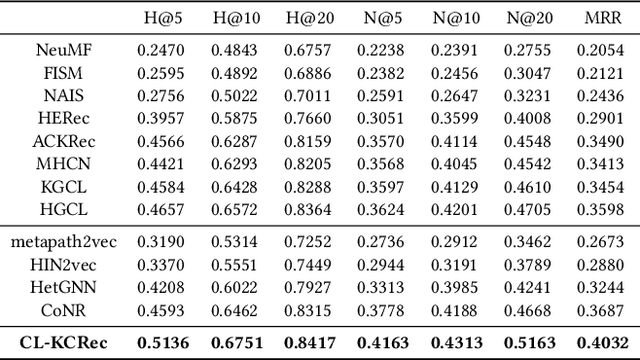
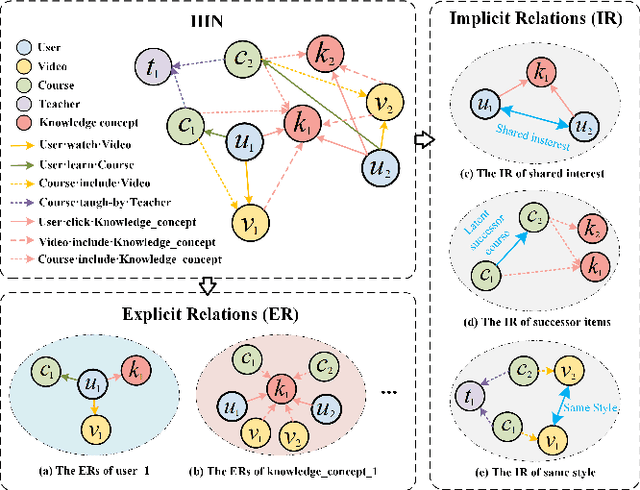
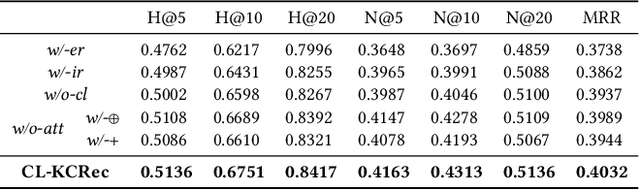
The knowledge concept recommendation in Massive Open Online Courses (MOOCs) is a significant issue that has garnered widespread attention. Existing methods primarily rely on the explicit relations between users and knowledge concepts on the MOOC platforms for recommendation. However, there are numerous implicit relations (e.g., shared interests or same knowledge levels between users) generated within the users' learning activities on the MOOC platforms. Existing methods fail to consider these implicit relations, and these relations themselves are difficult to learn and represent, causing poor performance in knowledge concept recommendation and an inability to meet users' personalized needs. To address this issue, we propose a novel framework based on contrastive learning, which can represent and balance the explicit and implicit relations for knowledge concept recommendation in MOOCs (CL-KCRec). Specifically, we first construct a MOOCs heterogeneous information network (HIN) by modeling the data from the MOOC platforms. Then, we utilize a relation-updated graph convolutional network and stacked multi-channel graph neural network to represent the explicit and implicit relations in the HIN, respectively. Considering that the quantity of explicit relations is relatively fewer compared to implicit relations in MOOCs, we propose a contrastive learning with prototypical graph to enhance the representations of both relations to capture their fruitful inherent relational knowledge, which can guide the propagation of students' preferences within the HIN. Based on these enhanced representations, to ensure the balanced contribution of both towards the final recommendation, we propose a dual-head attention mechanism for balanced fusion. Experimental results demonstrate that CL-KCRec outperforms several state-of-the-art baselines on real-world datasets in terms of HR, NDCG and MRR.
Sign Language Production with Latent Motion Transformer
Dec 20, 2023



Sign Language Production (SLP) is the tough task of turning sign language into sign videos. The main goal of SLP is to create these videos using a sign gloss. In this research, we've developed a new method to make high-quality sign videos without using human poses as a middle step. Our model works in two main parts: first, it learns from a generator and the video's hidden features, and next, it uses another model to understand the order of these hidden features. To make this method even better for sign videos, we make several significant improvements. (i) In the first stage, we take an improved 3D VQ-GAN to learn downsampled latent representations. (ii) In the second stage, we introduce sequence-to-sequence attention to better leverage conditional information. (iii) The separated two-stage training discards the realistic visual semantic of the latent codes in the second stage. To endow the latent sequences semantic information, we extend the token-level autoregressive latent codes learning with perceptual loss and reconstruction loss for the prior model with visual perception. Compared with previous state-of-the-art approaches, our model performs consistently better on two word-level sign language datasets, i.e., WLASL and NMFs-CSL.
Control-A-Video: Controllable Text-to-Video Generation with Diffusion Models
May 23, 2023This paper presents a controllable text-to-video (T2V) diffusion model, named Video-ControlNet, that generates videos conditioned on a sequence of control signals, such as edge or depth maps. Video-ControlNet is built on a pre-trained conditional text-to-image (T2I) diffusion model by incorporating a spatial-temporal self-attention mechanism and trainable temporal layers for efficient cross-frame modeling. A first-frame conditioning strategy is proposed to facilitate the model to generate videos transferred from the image domain as well as arbitrary-length videos in an auto-regressive manner. Moreover, Video-ControlNet employs a novel residual-based noise initialization strategy to introduce motion prior from an input video, producing more coherent videos. With the proposed architecture and strategies, Video-ControlNet can achieve resource-efficient convergence and generate superior quality and consistent videos with fine-grained control. Extensive experiments demonstrate its success in various video generative tasks such as video editing and video style transfer, outperforming previous methods in terms of consistency and quality. Project Page: https://controlavideo.github.io/