 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Solver Search for Fast Diffusion Sampling
May 27, 2025Diffusion models have demonstrated remarkable generation quality but at the cost of numerous function evaluations. Recently, advanced ODE-based solvers have been developed to mitigate the substantial computational demands of reverse-diffusion solving under limited sampling steps. However, these solvers, heavily inspired by Adams-like multistep methods, rely solely on t-related Lagrange interpolation. We show that t-related Lagrange interpolation is suboptimal for diffusion model and reveal a compact search space comprised of time steps and solver coefficients. Building on our analysis, we propose a novel differentiable solver search algorithm to identify more optimal solver. Equipped with the searched solver, rectified-flow models, e.g., SiT-XL/2 and FlowDCN-XL/2, achieve FID scores of 2.40 and 2.35, respectively, on ImageNet256 with only 10 steps. Meanwhile, DDPM model, DiT-XL/2, reaches a FID score of 2.33 with only 10 steps. Notably, our searched solver outperforms traditional solvers by a significant margin. Moreover, our searched solver demonstrates generality across various model architectures, resolutions, and model sizes.
FlowDCN: Exploring DCN-like Architectures for Fast Image Generation with Arbitrary Resolution
Oct 30, 2024


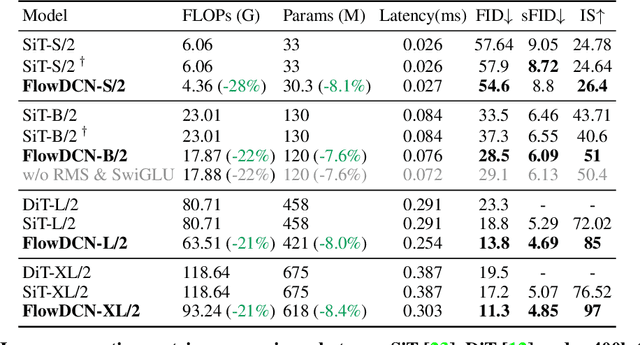
Arbitrary-resolution image generation still remains a challenging task in AIGC, as it requires handling varying resolutions and aspect ratios while maintaining high visual quality. Existing transformer-based diffusion methods suffer from quadratic computation cost and limited resolution extrapolation capabilities, making them less effective for this task. In this paper, we propose FlowDCN, a purely convolution-based generative model with linear time and memory complexity, that can efficiently generate high-quality images at arbitrary resolutions. Equipped with a new design of learnable group-wise deformable convolution block, our FlowDCN yields higher flexibility and capability to handle different resolutions with a single model. FlowDCN achieves the state-of-the-art 4.30 sFID on $256\times256$ ImageNet Benchmark and comparable resolution extrapolation results, surpassing transformer-based counterparts in terms of convergence speed (only $\frac{1}{5}$ images), visual quality, parameters ($8\%$ reduction) and FLOPs ($20\%$ reduction). We believe FlowDCN offers a promising solution to scalable and flexible image synthesis.
Group DETR v2: Strong Object Detector with Encoder-Decoder Pretraining
Nov 07, 2022

We present a strong object detector with encoder-decoder pretraining and finetuning. Our method, called Group DETR v2, is built upon a vision transformer encoder ViT-Huge~\cite{dosovitskiy2020image}, a DETR variant DINO~\cite{zhang2022dino}, and an efficient DETR training method Group DETR~\cite{chen2022group}. The training process consists of self-supervised pretraining and finetuning a ViT-Huge encoder on ImageNet-1K, pretraining the detector on Object365, and finally finetuning it on COCO. Group DETR v2 achieves $\textbf{64.5}$ mAP on COCO test-dev, and establishes a new SoTA on the COCO leaderboard https://paperswithcode.com/sota/object-detection-on-coco
ViTKD: Practical Guidelines for ViT feature knowledge distillation
Sep 06, 2022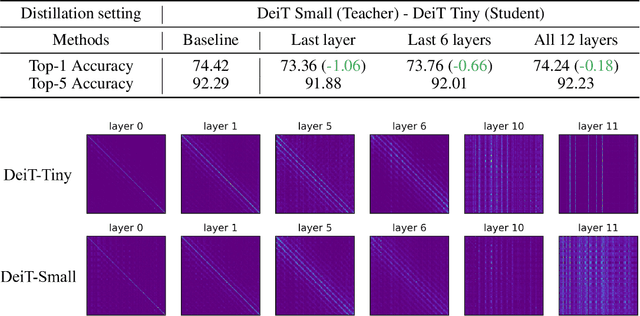
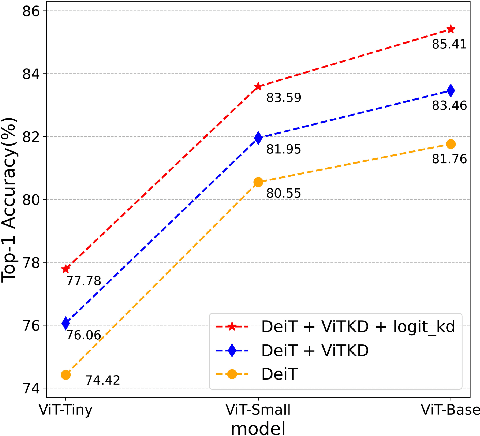
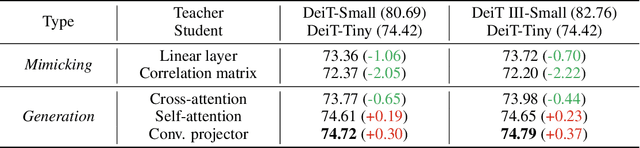

Knowledge Distillation (KD) for Convolutional Neural Network (CNN) is extensively studied as a way to boost the performance of a small model. Recently, Vision Transformer (ViT) has achieved great success on many computer vision tasks and KD for ViT is also desired. However, besides the output logit-based KD, other feature-based KD methods for CNNs cannot be directly applied to ViT due to the huge structure gap. In this paper, we explore the way of feature-based distillation for ViT. Based on the nature of feature maps in ViT, we design a series of controlled experiments and derive three practical guidelines for ViT's feature distillation. Some of our findings are even opposite to the practices in the CNN era. Based on the three guidelines, we propose our feature-based method ViTKD which brings consistent and considerable improvement to the student. On ImageNet-1k, we boost DeiT-Tiny from 74.42% to 76.06%, DeiT-Small from 80.55% to 81.95%, and DeiT-Base from 81.76% to 83.46%. Moreover, ViTKD and the logit-based KD method are complementary and can be applied together directly. This combination can further improve the performance of the student. Specifically, the student DeiT-Tiny, Small, and Base achieve 77.78%, 83.59%, and 85.41%, respectively. The code is available at https://github.com/yzd-v/cls_KD.
Vector Quantized Diffusion Model with CodeUnet for Text-to-Sign Pose Sequences Generation
Aug 19, 2022
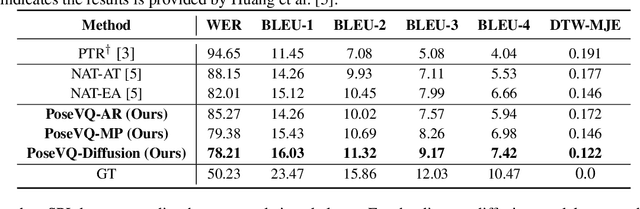
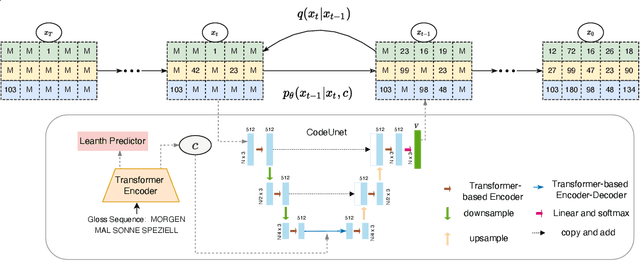

Sign Language Production (SLP) aims to translate spoken languages into sign sequences automatically. The core process of SLP is to transform sign gloss sequences into their corresponding sign pose sequences (G2P). Most existing G2P models usually perform this conditional long-range generation in an autoregressive manner, which inevitably leads to an accumulation of errors. To address this issue, we propose a vector quantized diffusion method for conditional pose sequences generation, called PoseVQ-Diffusion, which is an iterative non-autoregressive method. Specifically, we first introduce a vector quantized variational autoencoder (Pose-VQVAE) model to represent a pose sequence as a sequence of latent codes. Then we model the latent discrete space by an extension of the recently developed diffusion architecture. To better leverage the spatial-temporal information, we introduce a novel architecture, namely CodeUnet, to generate higher quality pose sequence in the discrete space. Moreover, taking advantage of the learned codes, we develop a novel sequential k-nearest-neighbours method to predict the variable lengths of pose sequences for corresponding gloss sequences. Consequently, compared with the autoregressive G2P models, our model has a faster sampling speed and produces significantly better results. Compared with previous non-autoregressive G2P methods, PoseVQ-Diffusion improves the predicted results with iterative refinements, thus achieving state-of-the-art results on the SLP evaluation benchmark.
ReconfigISP: Reconfigurable Camera Image Processing Pipeline
Sep 10, 2021

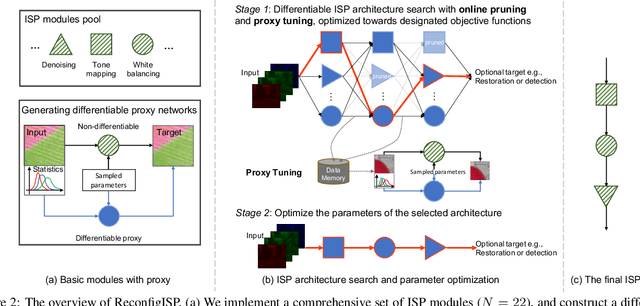
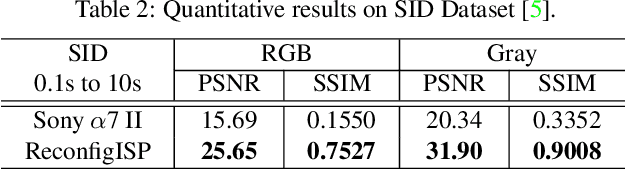
Image Signal Processor (ISP) is a crucial component in digital cameras that transforms sensor signals into images for us to perceive and understand. Existing ISP designs always adopt a fixed architecture, e.g., several sequential modules connected in a rigid order. Such a fixed ISP architecture may be suboptimal for real-world applications, where camera sensors, scenes and tasks are diverse. In this study, we propose a novel Reconfigurable ISP (ReconfigISP) whose architecture and parameters can be automatically tailored to specific data and tasks. In particular, we implement several ISP modules, and enable backpropagation for each module by training a differentiable proxy, hence allowing us to leverage the popular differentiable neural architecture search and effectively search for the optimal ISP architecture. A proxy tuning mechanism is adopted to maintain the accuracy of proxy networks in all cases. Extensive experiments conducted on image restoration and object detection, with different sensors, light conditions and efficiency constraints, validate the effectiveness of ReconfigISP. Only hundreds of parameters need tuning for every task.
MvSR-NAT: Multi-view Subset Regularization for Non-Autoregressive Machine Translation
Aug 19, 2021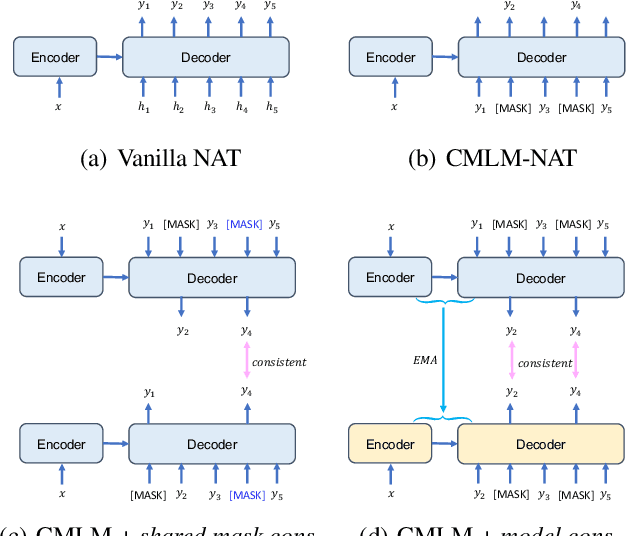

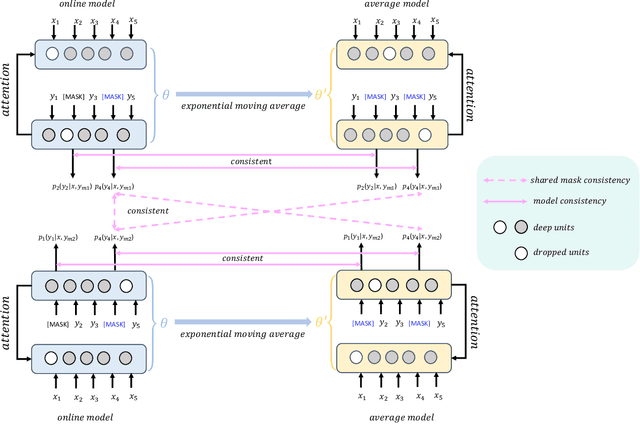
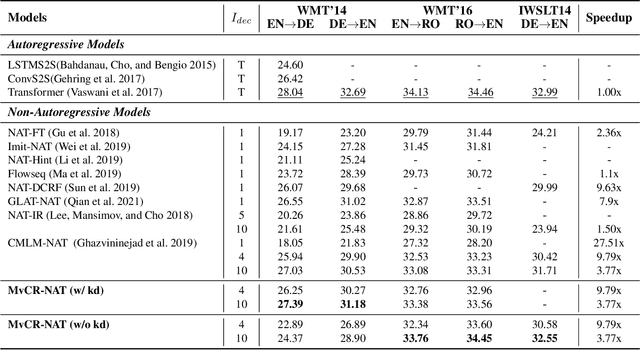
Conditional masked language models (CMLM) have shown impressive progress in non-autoregressive machine translation (NAT). They learn the conditional translation model by predicting the random masked subset in the target sentence. Based on the CMLM framework, we introduce Multi-view Subset Regularization (MvSR), a novel regularization method to improve the performance of the NAT model. Specifically, MvSR consists of two parts: (1) \textit{shared mask consistency}: we forward the same target with different mask strategies, and encourage the predictions of shared mask positions to be consistent with each other. (2) \textit{model consistency}, we maintain an exponential moving average of the model weights, and enforce the predictions to be consistent between the average model and the online model. Without changing the CMLM-based architecture, our approach achieves remarkable performance on three public benchmarks with 0.36-1.14 BLEU gains over previous NAT models. Moreover, compared with the stronger Transformer baseline, we reduce the gap to 0.01-0.44 BLEU scores on small datasets (WMT16 RO$\leftrightarrow$EN and IWSLT DE$\rightarrow$EN).