 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleSSP: Sampling StartPoint Enhancement for Training-free Diffusion-based Method for Style Transfer
Jan 20, 2025Training-free diffusion-based methods have achieved remarkable success in style transfer, eliminating the need for extensive training or fine-tuning. However, due to the lack of targeted training for style information extraction and constraints on the content image layout, training-free methods often suffer from layout changes of original content and content leakage from style images. Through a series of experiments, we discovered that an effective startpoint in the sampling stage significantly enhances the style transfer process. Based on this discovery, we propose StyleSSP, which focuses on obtaining a better startpoint to address layout changes of original content and content leakage from style image. StyleSSP comprises two key components: (1) Frequency Manipulation: To improve content preservation, we reduce the low-frequency components of the DDIM latent, allowing the sampling stage to pay more attention to the layout of content images; and (2) Negative Guidance via Inversion: To mitigate the content leakage from style image, we employ negative guidance in the inversion stage to ensure that the startpoint of the sampling stage is distanced from the content of style image. Experiments show that StyleSSP surpasses previous training-free style transfer baselines, particularly in preserving original content and minimizing the content leakage from style image.
CTRQNets & LQNets: Continuous Time Recurrent and Liquid Quantum Neural Networks
Aug 28, 2024Neural networks have continued to gain prevalence in the modern era for their ability to model complex data through pattern recognition and behavior remodeling. However, the static construction of traditional neural networks inhibits dynamic intelligence. This makes them inflexible to temporal changes in data and unfit to capture complex dependencies. With the advent of quantum technology, there has been significant progress in creating quantum algorithms. In recent years, researchers have developed quantum neural networks that leverage the capabilities of qubits to outperform classical networks. However, their current formulation exhibits a static construction limiting the system's dynamic intelligence. To address these weaknesses, we develop a Liquid Quantum Neural Network (LQNet) and a Continuous Time Recurrent Quantum Neural Network (CTRQNet). Both models demonstrate a significant improvement in accuracy compared to existing quantum neural networks (QNNs), achieving accuracy increases as high as 40\% on CIFAR 10 through binary classification. We propose LQNets and CTRQNets might shine a light on quantum machine learning's black box.
Forecasting Post-Wildfire Vegetation Recovery in California using a Convolutional Long Short-Term Memory Tensor Regression Network
Nov 04, 2023The study of post-wildfire plant regrowth is essential for developing successful ecosystem recovery strategies. Prior research mainly examines key ecological and biogeographical factors influencing post-fire succession. This research proposes a novel approach for predicting and analyzing post-fire plant recovery. We develop a Convolutional Long Short-Term Memory Tensor Regression (ConvLSTMTR) network that predicts future Normalized Difference Vegetation Index (NDVI) based on short-term plant growth data after fire containment. The model is trained and tested on 104 major California wildfires occurring between 2013 and 2020, each with burn areas exceeding 3000 acres. The integration of ConvLSTM with tensor regression enables the calculation of an overall logistic growth rate k using predicted NDVI. Overall, our k-value predictions demonstrate impressive performance, with 50% of predictions exhibiting an absolute error of 0.12 or less, and 75% having an error of 0.24 or less. Finally, we employ Uniform Manifold Approximation and Projection (UMAP) and KNN clustering to identify recovery trends, offering insights into regions with varying rates of recovery. This study pioneers the combined use of tensor regression and ConvLSTM, and introduces the application of UMAP for clustering similar wildfires. This advances predictive ecological modeling and could inform future post-fire vegetation management strategies.
Heterogeneous Generative Knowledge Distillation with Masked Image Modeling
Sep 18, 2023



Small CNN-based models usually require transferring knowledge from a large model before they are deployed in computationally resource-limited edge devices. Masked image modeling (MIM) methods achieve great success in various visual tasks but remain largely unexplored in knowledge distillation for heterogeneous deep models. The reason is mainly due to the significant discrepancy between the Transformer-based large model and the CNN-based small network. In this paper, we develop the first Heterogeneous Generative Knowledge Distillation (H-GKD) based on MIM, which can efficiently transfer knowledge from large Transformer models to small CNN-based models in a generative self-supervised fashion. Our method builds a bridge between Transformer-based models and CNNs by training a UNet-style student with sparse convolution, which can effectively mimic the visual representation inferred by a teacher over masked modeling. Our method is a simple yet effective learning paradigm to learn the visual representation and distribution of data from heterogeneous teacher models, which can be pre-trained using advanced generative methods. Extensive experiments show that it adapts well to various models and sizes, consistently achieving state-of-the-art performance in image classification, object detection, and semantic segmentation tasks. For example, in the Imagenet 1K dataset, H-GKD improves the accuracy of Resnet50 (sparse) from 76.98% to 80.01%.
Language-aware Multiple Datasets Detection Pretraining for DETRs
Apr 07, 2023



Pretraining on large-scale datasets can boost the performance of object detectors while the annotated datasets for object detection are hard to scale up due to the high labor cost. What we possess are numerous isolated filed-specific datasets, thus, it is appealing to jointly pretrain models across aggregation of datasets to enhance data volume and diversity. In this paper, we propose a strong framework for utilizing Multiple datasets to pretrain DETR-like detectors, termed METR, without the need for manual label spaces integration. It converts the typical multi-classification in object detection into binary classification by introducing a pre-trained language model. Specifically, we design a category extraction module for extracting potential categories involved in an image and assign these categories into different queries by language embeddings. Each query is only responsible for predicting a class-specific object. Besides, to adapt our novel detection paradigm, we propose a group bipartite matching strategy that limits the ground truths to match queries assigned to the same category. Extensive experiments demonstrate that METR achieves extraordinary results on either multi-task joint training or the pretrain & finetune paradigm. Notably, our pre-trained models have high flexible transferability and increase the performance upon various DETR-like detectors on COCO val2017 benchmark. Codes will be available after this paper is published.
CAE v2: Context Autoencoder with CLIP Target
Nov 17, 2022



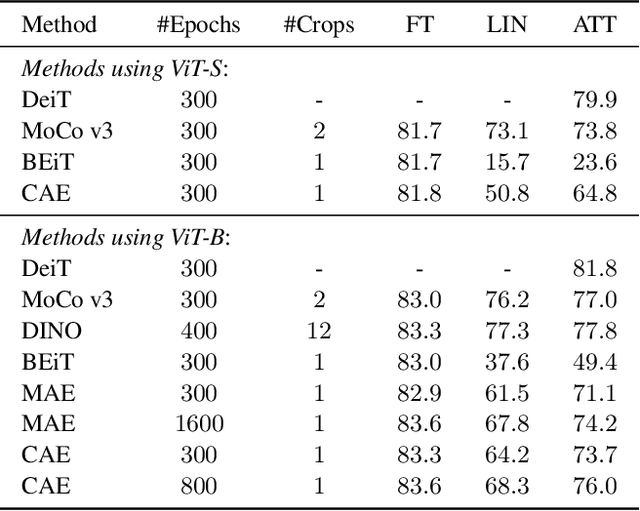
Masked image modeling (MIM) learns visual representation by masking and reconstructing image patches. Applying the reconstruction supervision on the CLIP representation has been proven effective for MIM. However, it is still under-explored how CLIP supervision in MIM influences performance. To investigate strategies for refining the CLIP-targeted MIM, we study two critical elements in MIM, i.e., the supervision position and the mask ratio, and reveal two interesting perspectives, relying on our developed simple pipeline, context autodecoder with CLIP target (CAE v2). Firstly, we observe that the supervision on visible patches achieves remarkable performance, even better than that on masked patches, where the latter is the standard format in the existing MIM methods. Secondly, the optimal mask ratio positively correlates to the model size. That is to say, the smaller the model, the lower the mask ratio needs to be. Driven by these two discoveries, our simple and concise approach CAE v2 achieves superior performance on a series of downstream tasks. For example, a vanilla ViT-Large model achieves 81.7% and 86.7% top-1 accuracy on linear probing and fine-tuning on ImageNet-1K, and 55.9% mIoU on semantic segmentation on ADE20K with the pre-training for 300 epochs. We hope our findings can be helpful guidelines for the pre-training in the MIM area, especially for the small-scale models.
Group DETR v2: Strong Object Detector with Encoder-Decoder Pretraining
Nov 07, 2022

We present a strong object detector with encoder-decoder pretraining and finetuning. Our method, called Group DETR v2, is built upon a vision transformer encoder ViT-Huge~\cite{dosovitskiy2020image}, a DETR variant DINO~\cite{zhang2022dino}, and an efficient DETR training method Group DETR~\cite{chen2022group}. The training process consists of self-supervised pretraining and finetuning a ViT-Huge encoder on ImageNet-1K, pretraining the detector on Object365, and finally finetuning it on COCO. Group DETR v2 achieves $\textbf{64.5}$ mAP on COCO test-dev, and establishes a new SoTA on the COCO leaderboard https://paperswithcode.com/sota/object-detection-on-coco
Context Autoencoder for Self-Supervised Representation Learning
Feb 07, 2022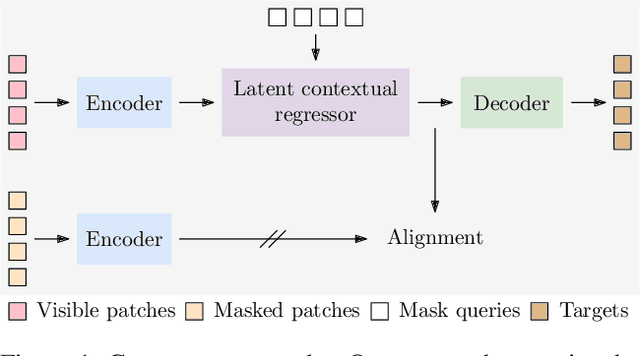


We present a novel masked image modeling (MIM) approach, context autoencoder (CAE), for self-supervised learning. We randomly partition the image into two sets: visible patches and masked patches. The CAE architecture consists of: (i) an encoder that takes visible patches as input and outputs their latent representations, (ii) a latent context regressor that predicts the masked patch representations from the visible patch representations that are not updated in this regressor, (iii) a decoder that takes the estimated masked patch representations as input and makes predictions for the masked patches, and (iv) an alignment module that aligns the masked patch representation estimation with the masked patch representations computed from the encoder. In comparison to previous MIM methods that couple the encoding and decoding roles, e.g., using a single module in BEiT, our approach attempts to~\emph{separate the encoding role (content understanding) from the decoding role (making predictions for masked patches)} using different modules, improving the content understanding capability. In addition, our approach makes predictions from the visible patches to the masked patches in \emph{the latent representation space} that is expected to take on semantics. In addition, we present the explanations about why contrastive pretraining and supervised pretraining perform similarly and why MIM potentially performs better. We demonstrate the effectiveness of our CAE through superior transfer performance in downstream tasks: semantic segmentation, and object detection and instance segmentation.
Oriented Object Detection with Transformer
Jun 06, 2021
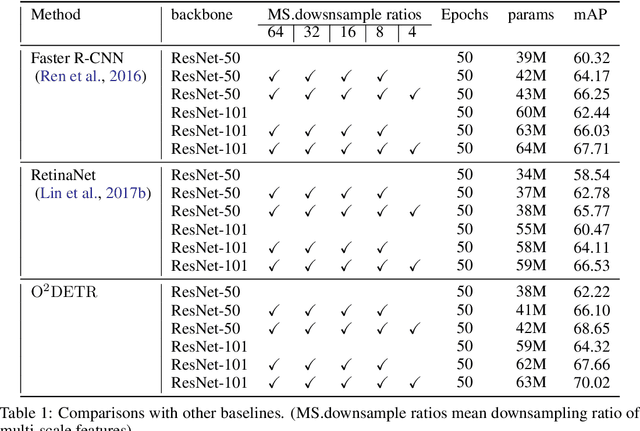
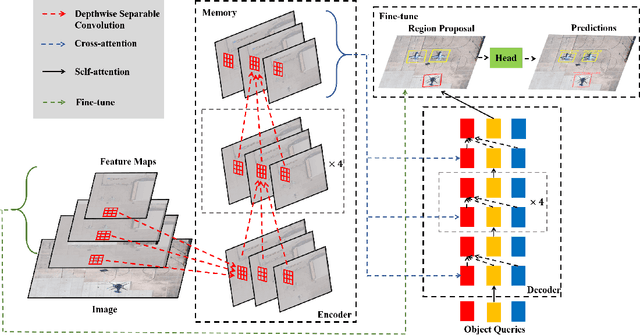
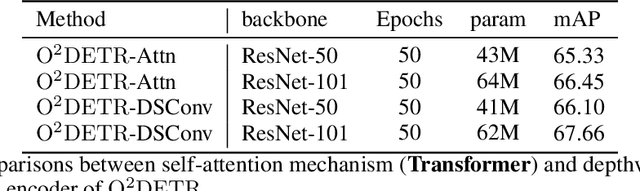
Object detection with Transformers (DETR) has achieved a competitive performance over traditional detectors, such as Faster R-CNN. However, the potential of DETR remains largely unexplored for the more challenging task of arbitrary-oriented object detection problem. We provide the first attempt and implement Oriented Object DEtection with TRansformer ($\bf O^2DETR$) based on an end-to-end network. The contributions of $\rm O^2DETR$ include: 1) we provide a new insight into oriented object detection, by applying Transformer to directly and efficiently localize objects without a tedious process of rotated anchors as in conventional detectors; 2) we design a simple but highly efficient encoder for Transformer by replacing the attention mechanism with depthwise separable convolution, which can significantly reduce the memory and computational cost of using multi-scale features in the original Transformer; 3) our $\rm O^2DETR$ can be another new benchmark in the field of oriented object detection, which achieves up to 3.85 mAP improvement over Faster R-CNN and RetinaNet. We simply fine-tune the head mounted on $\rm O^2DETR$ in a cascaded architecture and achieve a competitive performance over SOTA in the DOTA dataset.
Probabilistic Ranking-Aware Ensembles for Enhanced Object Detections
May 07, 2021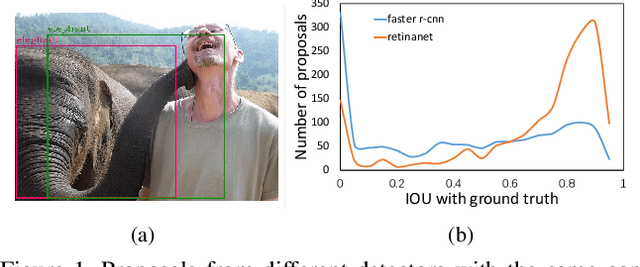

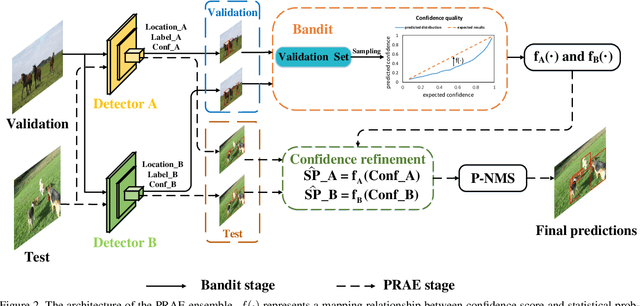

Model ensembles are becoming one of the most effective approaches for improving object detection performance already optimized for a single detector. Conventional methods directly fuse bounding boxes but typically fail to consider proposal qualities when combining detectors. This leads to a new problem of confidence discrepancy for the detector ensembles. The confidence has little effect on single detectors but significantly affects detector ensembles. To address this issue, we propose a novel ensemble called the Probabilistic Ranking Aware Ensemble (PRAE) that refines the confidence of bounding boxes from detectors. By simultaneously considering the category and the location on the same validation set, we obtain a more reliable confidence based on statistical probability. We can then rank the detected bounding boxes for assembly. We also introduce a bandit approach to address the confidence imbalance problem caused by the need to deal with different numbers of boxes at different confidence levels. We use our PRAE-based non-maximum suppression (P-NMS) to replace the conventional NMS method in ensemble learning. Experiments on the PASCAL VOC and COCO2017 datasets demonstrate that our PRAE method consistently outperforms state-of-the-art methods by significant margins.