 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Denoising Diffusion Models for Aligning Text-to-Image Generation
Oct 06, 2025Diffusion models have achieved impressive results in generating high-quality images. Yet, they often struggle to faithfully align the generated images with the input prompts. This limitation arises from synchronous denoising, where all pixels simultaneously evolve from random noise to clear images. As a result, during generation, the prompt-related regions can only reference the unrelated regions at the same noise level, failing to obtain clear context and ultimately impairing text-to-image alignment. To address this issue, we propose asynchronous diffusion models -- a novel framework that allocates distinct timesteps to different pixels and reformulates the pixel-wise denoising process. By dynamically modulating the timestep schedules of individual pixels, prompt-related regions are denoised more gradually than unrelated regions, thereby allowing them to leverage clearer inter-pixel context. Consequently, these prompt-related regions achieve better alignment in the final images. Extensive experiments demonstrate that our asynchronous diffusion models can significantly improve text-to-image alignment across diverse prompts. The code repository for this work is available at https://github.com/hu-zijing/AsynDM.
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Dec 03, 2024



Recent advancements in video generation have significantly impacted daily life for both individuals and industries. However, the leading video generation models remain closed-source, resulting in a notable performance gap between industry capabilities and those available to the public. In this report, we introduce HunyuanVideo, an innovative open-source video foundation model that demonstrates performance in video generation comparable to, or even surpassing, that of leading closed-source models. HunyuanVideo encompasses a comprehensive framework that integrates several key elements, including data curation, advanced architectural design, progressive model scaling and training, and an efficient infrastructure tailored for large-scale model training and inference. As a result, we successfully trained a video generative model with over 13 billion parameters, making it the largest among all open-source models. We conducted extensive experiments and implemented a series of targeted designs to ensure high visual quality, motion dynamics, text-video alignment, and advanced filming techniques. According to evaluations by professionals, HunyuanVideo outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models. By releasing the code for the foundation model and its applications, we aim to bridge the gap between closed-source and open-source communities. This initiative will empower individuals within the community to experiment with their ideas, fostering a more dynamic and vibrant video generation ecosystem. The code is publicly available at https://github.com/Tencent/HunyuanVideo.
Follow-Your-Canvas: Higher-Resolution Video Outpainting with Extensive Content Generation
Sep 02, 2024This paper explores higher-resolution video outpainting with extensive content generation. We point out common issues faced by existing methods when attempting to largely outpaint videos: the generation of low-quality content and limitations imposed by GPU memory. To address these challenges, we propose a diffusion-based method called \textit{Follow-Your-Canvas}. It builds upon two core designs. First, instead of employing the common practice of "single-shot" outpainting, we distribute the task across spatial windows and seamlessly merge them. It allows us to outpaint videos of any size and resolution without being constrained by GPU memory. Second, the source video and its relative positional relation are injected into the generation process of each window. It makes the generated spatial layout within each window harmonize with the source video. Coupling with these two designs enables us to generate higher-resolution outpainting videos with rich content while keeping spatial and temporal consistency. Follow-Your-Canvas excels in large-scale video outpainting, e.g., from 512X512 to 1152X2048 (9X), while producing high-quality and aesthetically pleasing results. It achieves the best quantitative results across various resolution and scale setups. The code is released on https://github.com/mayuelala/FollowYourCanvas
Follow-Your-Emoji: Fine-Controllable and Expressive Freestyle Portrait Animation
Jun 04, 2024



We present Follow-Your-Emoji, a diffusion-based framework for portrait animation, which animates a reference portrait with target landmark sequences. The main challenge of portrait animation is to preserve the identity of the reference portrait and transfer the target expression to this portrait while maintaining temporal consistency and fidelity. To address these challenges, Follow-Your-Emoji equipped the powerful Stable Diffusion model with two well-designed technologies. Specifically, we first adopt a new explicit motion signal, namely expression-aware landmark, to guide the animation process. We discover this landmark can not only ensure the accurate motion alignment between the reference portrait and target motion during inference but also increase the ability to portray exaggerated expressions (i.e., large pupil movements) and avoid identity leakage. Then, we propose a facial fine-grained loss to improve the model's ability of subtle expression perception and reference portrait appearance reconstruction by using both expression and facial masks. Accordingly, our method demonstrates significant performance in controlling the expression of freestyle portraits, including real humans, cartoons, sculptures, and even animals. By leveraging a simple and effective progressive generation strategy, we extend our model to stable long-term animation, thus increasing its potential application value. To address the lack of a benchmark for this field, we introduce EmojiBench, a comprehensive benchmark comprising diverse portrait images, driving videos, and landmarks. We show extensive evaluations on EmojiBench to verify the superiority of Follow-Your-Emoji.
HAP: Structure-Aware Masked Image Modeling for Human-Centric Perception
Oct 31, 2023Model pre-training is essential in human-centric perception. In this paper, we first introduce masked image modeling (MIM) as a pre-training approach for this task. Upon revisiting the MIM training strategy, we reveal that human structure priors offer significant potential. Motivated by this insight, we further incorporate an intuitive human structure prior - human parts - into pre-training. Specifically, we employ this prior to guide the mask sampling process. Image patches, corresponding to human part regions, have high priority to be masked out. This encourages the model to concentrate more on body structure information during pre-training, yielding substantial benefits across a range of human-centric perception tasks. To further capture human characteristics, we propose a structure-invariant alignment loss that enforces different masked views, guided by the human part prior, to be closely aligned for the same image. We term the entire method as HAP. HAP simply uses a plain ViT as the encoder yet establishes new state-of-the-art performance on 11 human-centric benchmarks, and on-par result on one dataset. For example, HAP achieves 78.1% mAP on MSMT17 for person re-identification, 86.54% mA on PA-100K for pedestrian attribute recognition, 78.2% AP on MS COCO for 2D pose estimation, and 56.0 PA-MPJPE on 3DPW for 3D pose and shape estimation.
Bridging the Gap: Neural Collapse Inspired Prompt Tuning for Generalization under Class Imbalance
Jun 29, 2023Large-scale vision-language (V-L) models have demonstrated remarkable generalization capabilities for downstream tasks through prompt tuning. However, their performance suffers significantly in the presence of class imbalance, a common issue in real-world scenarios. In this paper, we investigate the effects of class imbalance on the generalization performance of V-L models and extend Neural Collapse phenomenon to these models, revealing the geometric reasons behind the impact of class imbalance on their generalization ability. To address this problem, we propose Neural Collapse based Prompt Tuning (NPT), a novel method that optimizes prompts so that both text and image features satisfy the same simplex ETF structure. NPT incorporates two regularization terms, geometric de-biasing and multi-modal isomorphism, to enhance the robustness of V-L models under class imbalance conditions while maintaining their generalization capabilities. Our comprehensive experiments show that NPT outperforms existing prompt learning techniques across 11 diverse image recognition datasets, achieving an absolute average gain of 2.63\% for novel classes and 2.47\% for harmonic mean when facing imbalanced data.
Quantitatively Measuring and Contrastively Exploring Heterogeneity for Domain Generalization
May 25, 2023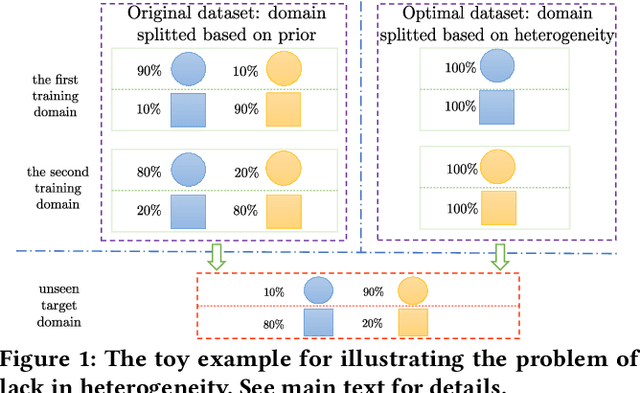

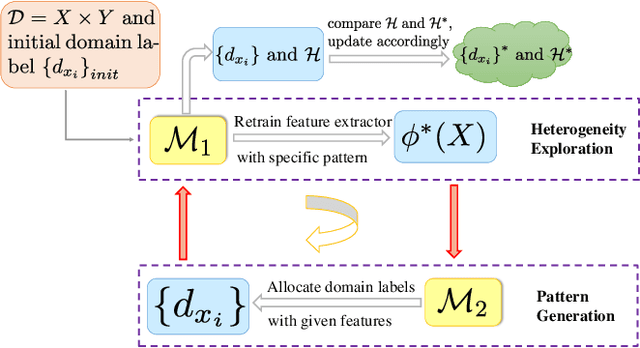

Domain generalization (DG) is a prevalent problem in real-world applications, which aims to train well-generalized models for unseen target domains by utilizing several source domains. Since domain labels, i.e., which domain each data point is sampled from, naturally exist, most DG algorithms treat them as a kind of supervision information to improve the generalization performance. However, the original domain labels may not be the optimal supervision signal due to the lack of domain heterogeneity, i.e., the diversity among domains. For example, a sample in one domain may be closer to another domain, its original label thus can be the noise to disturb the generalization learning. Although some methods try to solve it by re-dividing domains and applying the newly generated dividing pattern, the pattern they choose may not be the most heterogeneous due to the lack of the metric for heterogeneity. In this paper, we point out that domain heterogeneity mainly lies in variant features under the invariant learning framework. With contrastive learning, we propose a learning potential-guided metric for domain heterogeneity by promoting learning variant features. Then we notice the differences between seeking variance-based heterogeneity and training invariance-based generalizable model. We thus propose a novel method called Heterogeneity-based Two-stage Contrastive Learning (HTCL) for the DG task. In the first stage, we generate the most heterogeneous dividing pattern with our contrastive metric. In the second stage, we employ an invariance-aimed contrastive learning by re-building pairs with the stable relation hinted by domains and classes, which better utilizes generated domain labels for generalization learning. Extensive experiments show HTCL better digs heterogeneity and yields great generalization performance.
Universal Domain Adaptation via Compressive Attention Matching
Apr 24, 2023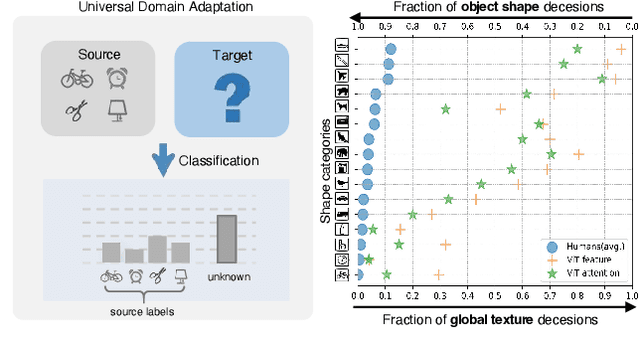
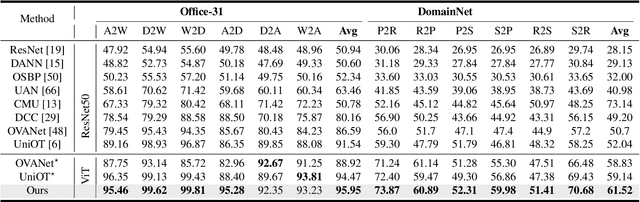

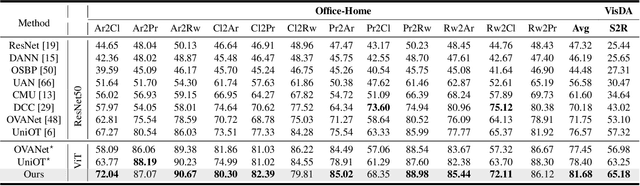
Universal domain adaptation (UniDA) aims to transfer knowledge from the source domain to the target domain without any prior knowledge about the label set. The challenge lies in how to determine whether the target samples belong to common categories. The mainstream methods make judgments based on the sample features, which overemphasizes global information while ignoring the most crucial local objects in the image, resulting in limited accuracy. To address this issue, we propose a Universal Attention Matching (UniAM) framework by exploiting the self-attention mechanism in vision transformer to capture the crucial object information. The proposed framework introduces a novel Compressive Attention Matching (CAM) approach to explore the core information by compressively representing attentions. Furthermore, CAM incorporates a residual-based measurement to determine the sample commonness. By utilizing the measurement, UniAM achieves domain-wise and category-wise Common Feature Alignment (CFA) and Target Class Separation (TCS). Notably, UniAM is the first method utilizing the attention in vision transformer directly to perform classification tasks. Extensive experiments show that UniAM outperforms the current state-of-the-art methods on various benchmark datasets.
Task-Oriented Multi-Modal Mutual Leaning for Vision-Language Models
Mar 30, 2023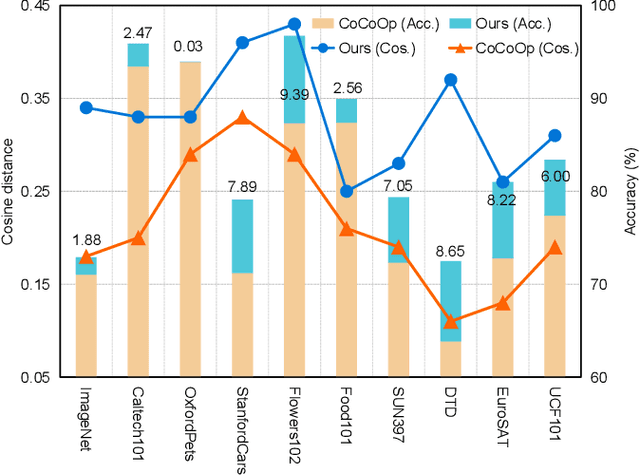
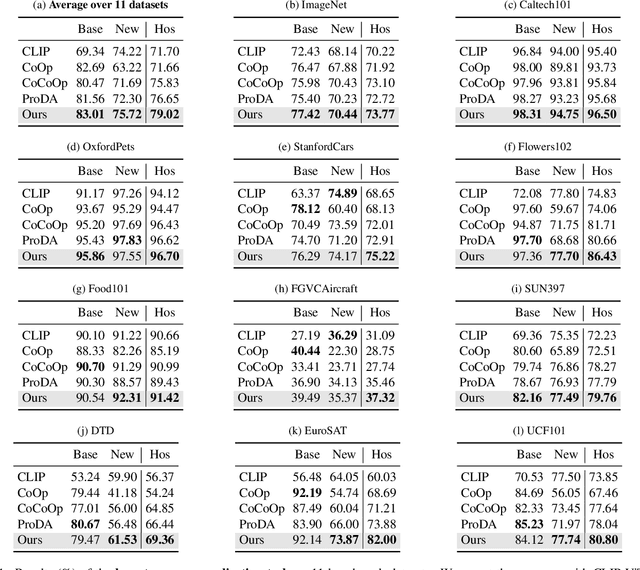
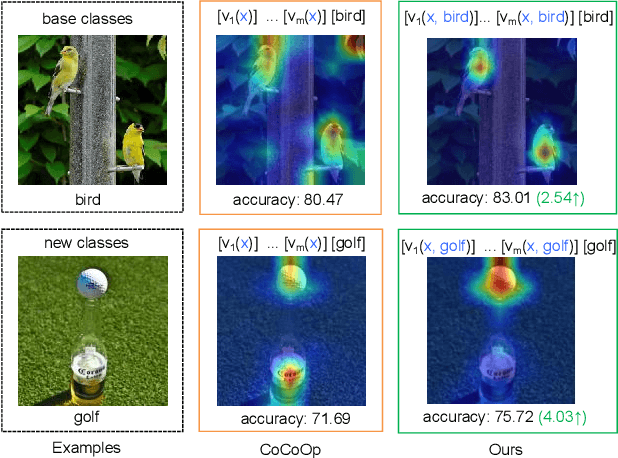
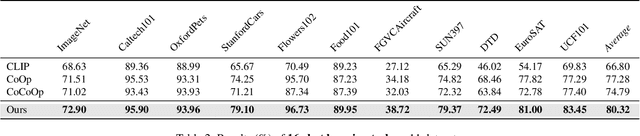
Prompt learning has become one of the most efficient paradigms for adapting large pre-trained vision-language models to downstream tasks. Current state-of-the-art methods, like CoOp and ProDA, tend to adopt soft prompts to learn an appropriate prompt for each specific task. Recent CoCoOp further boosts the base-to-new generalization performance via an image-conditional prompt. However, it directly fuses identical image semantics to prompts of different labels and significantly weakens the discrimination among different classes as shown in our experiments. Motivated by this observation, we first propose a class-aware text prompt (CTP) to enrich generated prompts with label-related image information. Unlike CoCoOp, CTP can effectively involve image semantics and avoid introducing extra ambiguities into different prompts. On the other hand, instead of reserving the complete image representations, we propose text-guided feature tuning (TFT) to make the image branch attend to class-related representation. A contrastive loss is employed to align such augmented text and image representations on downstream tasks. In this way, the image-to-text CTP and text-to-image TFT can be mutually promoted to enhance the adaptation of VLMs for downstream tasks. Extensive experiments demonstrate that our method outperforms the existing methods by a significant margin. Especially, compared to CoCoOp, we achieve an average improvement of 4.03% on new classes and 3.19% on harmonic-mean over eleven classification benchmarks.
CAE v2: Context Autoencoder with CLIP Target
Nov 17, 2022



Masked image modeling (MIM) learns visual representation by masking and reconstructing image patches. Applying the reconstruction supervision on the CLIP representation has been proven effective for MIM. However, it is still under-explored how CLIP supervision in MIM influences performance. To investigate strategies for refining the CLIP-targeted MIM, we study two critical elements in MIM, i.e., the supervision position and the mask ratio, and reveal two interesting perspectives, relying on our developed simple pipeline, context autodecoder with CLIP target (CAE v2). Firstly, we observe that the supervision on visible patches achieves remarkable performance, even better than that on masked patches, where the latter is the standard format in the existing MIM methods. Secondly, the optimal mask ratio positively correlates to the model size. That is to say, the smaller the model, the lower the mask ratio needs to be. Driven by these two discoveries, our simple and concise approach CAE v2 achieves superior performance on a series of downstream tasks. For example, a vanilla ViT-Large model achieves 81.7% and 86.7% top-1 accuracy on linear probing and fine-tuning on ImageNet-1K, and 55.9% mIoU on semantic segmentation on ADE20K with the pre-training for 300 epochs. We hope our findings can be helpful guidelines for the pre-training in the MIM area, especially for the small-scale models.