 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan-Game: Industrial-grade Intelligent Game Creation Model
May 20, 2025Intelligent game creation represents a transformative advancement in game development, utilizing generative artificial intelligence to dynamically generate and enhance game content. Despite notable progress in generative models, the comprehensive synthesis of high-quality game assets, including both images and videos, remains a challenging frontier. To create high-fidelity game content that simultaneously aligns with player preferences and significantly boosts designer efficiency, we present Hunyuan-Game, an innovative project designed to revolutionize intelligent game production. Hunyuan-Game encompasses two primary branches: image generation and video generation. The image generation component is built upon a vast dataset comprising billions of game images, leading to the development of a group of customized image generation models tailored for game scenarios: (1) General Text-to-Image Generation. (2) Game Visual Effects Generation, involving text-to-effect and reference image-based game visual effect generation. (3) Transparent Image Generation for characters, scenes, and game visual effects. (4) Game Character Generation based on sketches, black-and-white images, and white models. The video generation component is built upon a comprehensive dataset of millions of game and anime videos, leading to the development of five core algorithmic models, each targeting critical pain points in game development and having robust adaptation to diverse game video scenarios: (1) Image-to-Video Generation. (2) 360 A/T Pose Avatar Video Synthesis. (3) Dynamic Illustration Generation. (4) Generative Video Super-Resolution. (5) Interactive Game Video Generation. These image and video generation models not only exhibit high-level aesthetic expression but also deeply integrate domain-specific knowledge, establishing a systematic understanding of diverse game and anime art styles.
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Dec 03, 2024



Recent advancements in video generation have significantly impacted daily life for both individuals and industries. However, the leading video generation models remain closed-source, resulting in a notable performance gap between industry capabilities and those available to the public. In this report, we introduce HunyuanVideo, an innovative open-source video foundation model that demonstrates performance in video generation comparable to, or even surpassing, that of leading closed-source models. HunyuanVideo encompasses a comprehensive framework that integrates several key elements, including data curation, advanced architectural design, progressive model scaling and training, and an efficient infrastructure tailored for large-scale model training and inference. As a result, we successfully trained a video generative model with over 13 billion parameters, making it the largest among all open-source models. We conducted extensive experiments and implemented a series of targeted designs to ensure high visual quality, motion dynamics, text-video alignment, and advanced filming techniques. According to evaluations by professionals, HunyuanVideo outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models. By releasing the code for the foundation model and its applications, we aim to bridge the gap between closed-source and open-source communities. This initiative will empower individuals within the community to experiment with their ideas, fostering a more dynamic and vibrant video generation ecosystem. The code is publicly available at https://github.com/Tencent/HunyuanVideo.
Hunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding
May 14, 2024



We present Hunyuan-DiT, a text-to-image diffusion transformer with fine-grained understanding of both English and Chinese. To construct Hunyuan-DiT, we carefully design the transformer structure, text encoder, and positional encoding. We also build from scratch a whole data pipeline to update and evaluate data for iterative model optimization. For fine-grained language understanding, we train a Multimodal Large Language Model to refine the captions of the images. Finally, Hunyuan-DiT can perform multi-turn multimodal dialogue with users, generating and refining images according to the context. Through our holistic human evaluation protocol with more than 50 professional human evaluators, Hunyuan-DiT sets a new state-of-the-art in Chinese-to-image generation compared with other open-source models. Code and pretrained models are publicly available at github.com/Tencent/HunyuanDiT
DialogGen: Multi-modal Interactive Dialogue System for Multi-turn Text-to-Image Generation
Mar 13, 2024Text-to-image (T2I) generation models have significantly advanced in recent years. However, effective interaction with these models is challenging for average users due to the need for specialized prompt engineering knowledge and the inability to perform multi-turn image generation, hindering a dynamic and iterative creation process. Recent attempts have tried to equip Multi-modal Large Language Models (MLLMs) with T2I models to bring the user's natural language instructions into reality. Hence, the output modality of MLLMs is extended, and the multi-turn generation quality of T2I models is enhanced thanks to the strong multi-modal comprehension ability of MLLMs. However, many of these works face challenges in identifying correct output modalities and generating coherent images accordingly as the number of output modalities increases and the conversations go deeper. Therefore, we propose DialogGen, an effective pipeline to align off-the-shelf MLLMs and T2I models to build a Multi-modal Interactive Dialogue System (MIDS) for multi-turn Text-to-Image generation. It is composed of drawing prompt alignment, careful training data curation, and error correction. Moreover, as the field of MIDS flourishes, comprehensive benchmarks are urgently needed to evaluate MIDS fairly in terms of output modality correctness and multi-modal output coherence. To address this issue, we introduce the Multi-modal Dialogue Benchmark (DialogBen), a comprehensive bilingual benchmark designed to assess the ability of MLLMs to generate accurate and coherent multi-modal content that supports image editing. It contains two evaluation metrics to measure the model's ability to switch modalities and the coherence of the output images. Our extensive experiments on DialogBen and user study demonstrate the effectiveness of DialogGen compared with other State-of-the-Art models.
Tencent AVS: A Holistic Ads Video Dataset for Multi-modal Scene Segmentation
Dec 09, 2022


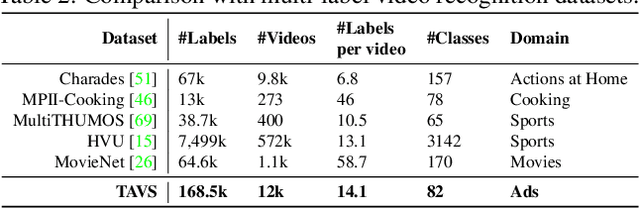
Temporal video segmentation and classification have been advanced greatly by public benchmarks in recent years. However, such research still mainly focuses on human actions, failing to describe videos in a holistic view. In addition, previous research tends to pay much attention to visual information yet ignores the multi-modal nature of videos. To fill this gap, we construct the Tencent `Ads Video Segmentation'~(TAVS) dataset in the ads domain to escalate multi-modal video analysis to a new level. TAVS describes videos from three independent perspectives as `presentation form', `place', and `style', and contains rich multi-modal information such as video, audio, and text. TAVS is organized hierarchically in semantic aspects for comprehensive temporal video segmentation with three levels of categories for multi-label classification, e.g., `place' - `working place' - `office'. Therefore, TAVS is distinguished from previous temporal segmentation datasets due to its multi-modal information, holistic view of categories, and hierarchical granularities. It includes 12,000 videos, 82 classes, 33,900 segments, 121,100 shots, and 168,500 labels. Accompanied with TAVS, we also present a strong multi-modal video segmentation baseline coupled with multi-label class prediction. Extensive experiments are conducted to evaluate our proposed method as well as existing representative methods to reveal key challenges of our dataset TAVS.
Overview of Tencent Multi-modal Ads Video Understanding Challenge
Sep 16, 2021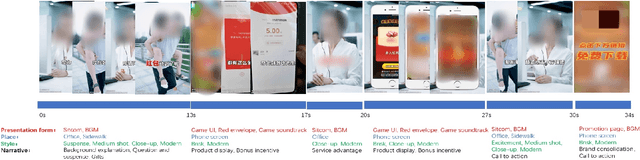
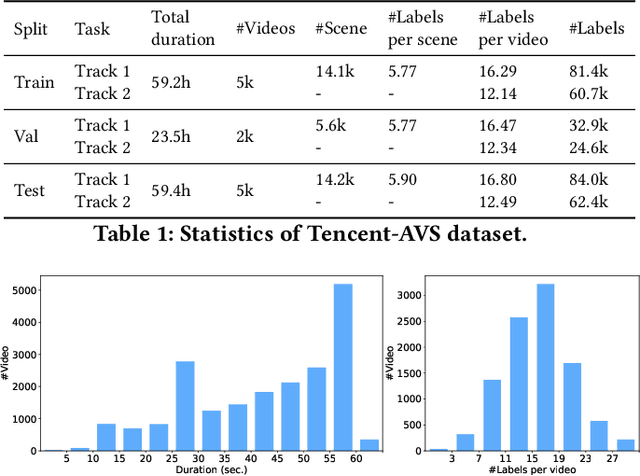
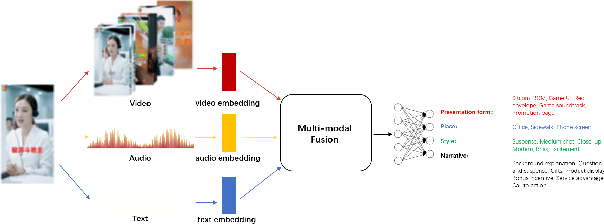
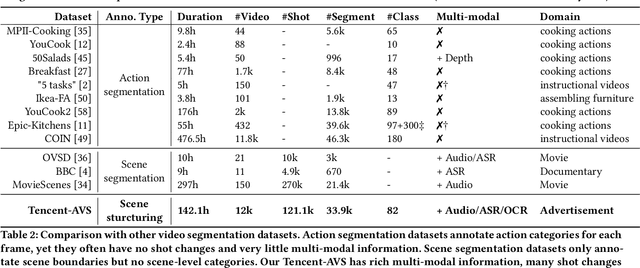
Multi-modal Ads Video Understanding Challenge is the first grand challenge aiming to comprehensively understand ads videos. Our challenge includes two tasks: video structuring in the temporal dimension and multi-modal video classification. It asks the participants to accurately predict both the scene boundaries and the multi-label categories of each scene based on a fine-grained and ads-related category hierarchy. Therefore, our task has four distinguishing features from previous ones: ads domain, multi-modal information, temporal segmentation, and multi-label classification. It will advance the foundation of ads video understanding and have a significant impact on many ads applications like video recommendation. This paper presents an overview of our challenge, including the background of ads videos, an elaborate description of task and dataset, evaluation protocol, and our proposed baseline. By ablating the key components of our baseline, we would like to reveal the main challenges of this task and provide useful guidance for future research of this area. In this paper, we give an extended version of our challenge overview. The dataset will be publicly available at https://algo.qq.com/.