 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding
May 14, 2024



We present Hunyuan-DiT, a text-to-image diffusion transformer with fine-grained understanding of both English and Chinese. To construct Hunyuan-DiT, we carefully design the transformer structure, text encoder, and positional encoding. We also build from scratch a whole data pipeline to update and evaluate data for iterative model optimization. For fine-grained language understanding, we train a Multimodal Large Language Model to refine the captions of the images. Finally, Hunyuan-DiT can perform multi-turn multimodal dialogue with users, generating and refining images according to the context. Through our holistic human evaluation protocol with more than 50 professional human evaluators, Hunyuan-DiT sets a new state-of-the-art in Chinese-to-image generation compared with other open-source models. Code and pretrained models are publicly available at github.com/Tencent/HunyuanDiT
Tencent AVS: A Holistic Ads Video Dataset for Multi-modal Scene Segmentation
Dec 09, 2022


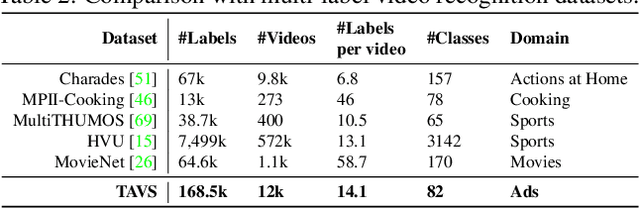
Temporal video segmentation and classification have been advanced greatly by public benchmarks in recent years. However, such research still mainly focuses on human actions, failing to describe videos in a holistic view. In addition, previous research tends to pay much attention to visual information yet ignores the multi-modal nature of videos. To fill this gap, we construct the Tencent `Ads Video Segmentation'~(TAVS) dataset in the ads domain to escalate multi-modal video analysis to a new level. TAVS describes videos from three independent perspectives as `presentation form', `place', and `style', and contains rich multi-modal information such as video, audio, and text. TAVS is organized hierarchically in semantic aspects for comprehensive temporal video segmentation with three levels of categories for multi-label classification, e.g., `place' - `working place' - `office'. Therefore, TAVS is distinguished from previous temporal segmentation datasets due to its multi-modal information, holistic view of categories, and hierarchical granularities. It includes 12,000 videos, 82 classes, 33,900 segments, 121,100 shots, and 168,500 labels. Accompanied with TAVS, we also present a strong multi-modal video segmentation baseline coupled with multi-label class prediction. Extensive experiments are conducted to evaluate our proposed method as well as existing representative methods to reveal key challenges of our dataset TAVS.