 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Multi-modal Large Language Models via Visual Token Grouping
Nov 26, 2024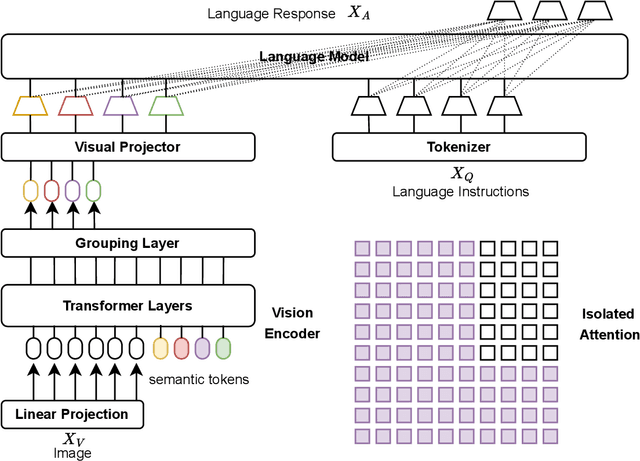
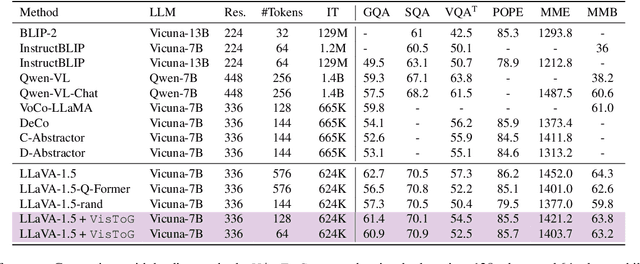
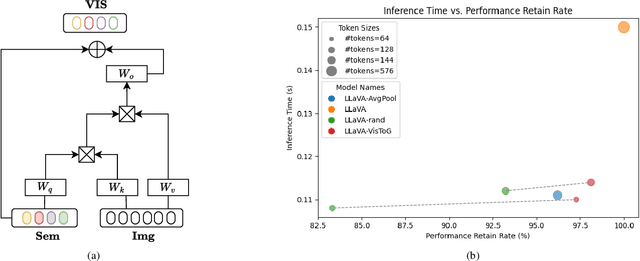
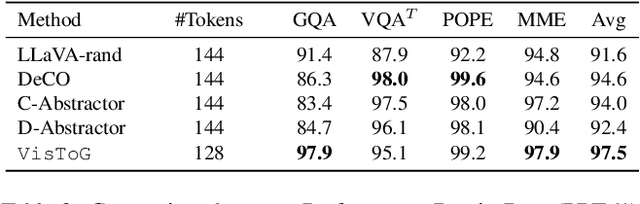
The development of Multi-modal Large Language Models (MLLMs) enhances Large Language Models (LLMs) with the ability to perceive data formats beyond text, significantly advancing a range of downstream applications, such as visual question answering and image captioning. However, the substantial computational costs associated with processing high-resolution images and videos pose a barrier to their broader adoption. To address this challenge, compressing vision tokens in MLLMs has emerged as a promising approach to reduce inference costs. While existing methods conduct token reduction in the feature alignment phase. In this paper, we introduce VisToG, a novel grouping mechanism that leverages the capabilities of pre-trained vision encoders to group similar image segments without the need for segmentation masks. Specifically, we concatenate semantic tokens to represent image semantic segments after the linear projection layer before feeding into the vision encoder. Besides, with the isolated attention we adopt, VisToG can identify and eliminate redundant visual tokens utilizing the prior knowledge in the pre-trained vision encoder, which effectively reduces computational demands. Extensive experiments demonstrate the effectiveness of VisToG, maintaining 98.1% of the original performance while achieving a reduction of over 27\% inference time.
DAPE V2: Process Attention Score as Feature Map for Length Extrapolation
Oct 07, 2024



The attention mechanism is a fundamental component of the Transformer model, contributing to interactions among distinct tokens, in contrast to earlier feed-forward neural networks. In general, the attention scores are determined simply by the key-query products. However, this work's occasional trial (combining DAPE and NoPE) of including additional MLPs on attention scores without position encoding indicates that the classical key-query multiplication may limit the performance of Transformers. In this work, we conceptualize attention as a feature map and apply the convolution operator (for neighboring attention scores across different heads) to mimic the processing methods in computer vision. Specifically, the main contribution of this paper is identifying and interpreting the Transformer length extrapolation problem as a result of the limited expressiveness of the naive query and key dot product, and we successfully translate the length extrapolation issue into a well-understood feature map processing problem. The novel insight, which can be adapted to various attention-related models, reveals that the current Transformer architecture has the potential for further evolution. Extensive experiments demonstrate that treating attention as a feature map and applying convolution as a processing method significantly enhances Transformer performance.
CAPE: Context-Adaptive Positional Encoding for Length Extrapolation
May 23, 2024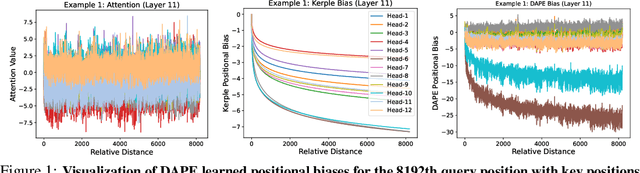
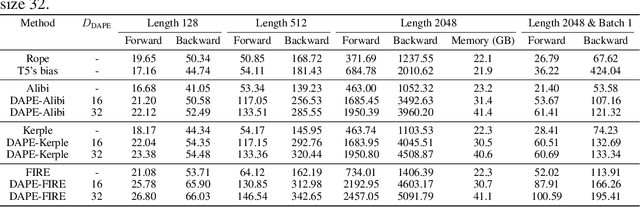
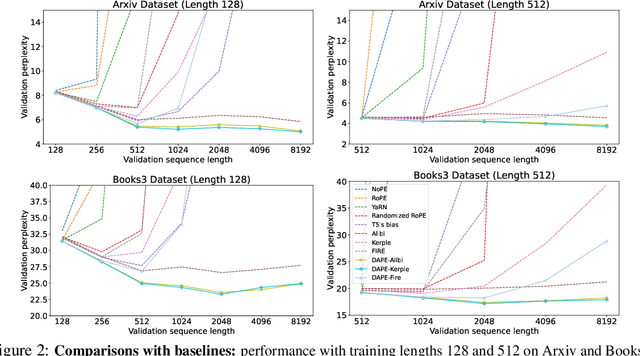
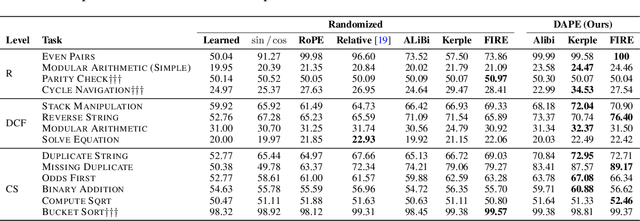
Positional encoding plays a crucial role in transformers, significantly impacting model performance and length generalization. Prior research has introduced absolute positional encoding (APE) and relative positional encoding (RPE) to distinguish token positions in given sequences. However, both APE and RPE remain fixed after model training regardless of input data, limiting their adaptability and flexibility. Hence, we expect that the desired positional encoding should be context-adaptive and can be dynamically adjusted with the given attention. In this paper, we propose a Context-Adaptive Positional Encoding (CAPE) method, which dynamically and semantically adjusts based on input context and learned fixed priors. Experimental validation on real-world datasets (Arxiv, Books3, and CHE) demonstrates that CAPE enhances model performances in terms of trained length and length generalization, where the improvements are statistically significant. The model visualization suggests that our model can keep both local and anti-local information. Finally, we successfully train the model on sequence length 128 and achieve better performance at evaluation sequence length 8192, compared with other static positional encoding methods, revealing the benefit of the adaptive positional encoding method.
Hunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding
May 14, 2024



We present Hunyuan-DiT, a text-to-image diffusion transformer with fine-grained understanding of both English and Chinese. To construct Hunyuan-DiT, we carefully design the transformer structure, text encoder, and positional encoding. We also build from scratch a whole data pipeline to update and evaluate data for iterative model optimization. For fine-grained language understanding, we train a Multimodal Large Language Model to refine the captions of the images. Finally, Hunyuan-DiT can perform multi-turn multimodal dialogue with users, generating and refining images according to the context. Through our holistic human evaluation protocol with more than 50 professional human evaluators, Hunyuan-DiT sets a new state-of-the-art in Chinese-to-image generation compared with other open-source models. Code and pretrained models are publicly available at github.com/Tencent/HunyuanDiT
TheaterGen: Character Management with LLM for Consistent Multi-turn Image Generation
Apr 29, 2024



Recent advances in diffusion models can generate high-quality and stunning images from text. However, multi-turn image generation, which is of high demand in real-world scenarios, still faces challenges in maintaining semantic consistency between images and texts, as well as contextual consistency of the same subject across multiple interactive turns. To address this issue, we introduce TheaterGen, a training-free framework that integrates large language models (LLMs) and text-to-image (T2I) models to provide the capability of multi-turn image generation. Within this framework, LLMs, acting as a "Screenwriter", engage in multi-turn interaction, generating and managing a standardized prompt book that encompasses prompts and layout designs for each character in the target image. Based on these, Theatergen generate a list of character images and extract guidance information, akin to the "Rehearsal". Subsequently, through incorporating the prompt book and guidance information into the reverse denoising process of T2I diffusion models, Theatergen generate the final image, as conducting the "Final Performance". With the effective management of prompt books and character images, TheaterGen significantly improves semantic and contextual consistency in synthesized images. Furthermore, we introduce a dedicated benchmark, CMIGBench (Consistent Multi-turn Image Generation Benchmark) with 8000 multi-turn instructions. Different from previous multi-turn benchmarks, CMIGBench does not define characters in advance. Both the tasks of story generation and multi-turn editing are included on CMIGBench for comprehensive evaluation. Extensive experimental results show that TheaterGen outperforms state-of-the-art methods significantly. It raises the performance bar of the cutting-edge Mini DALLE 3 model by 21% in average character-character similarity and 19% in average text-image similarity.
DialogGen: Multi-modal Interactive Dialogue System for Multi-turn Text-to-Image Generation
Mar 13, 2024Text-to-image (T2I) generation models have significantly advanced in recent years. However, effective interaction with these models is challenging for average users due to the need for specialized prompt engineering knowledge and the inability to perform multi-turn image generation, hindering a dynamic and iterative creation process. Recent attempts have tried to equip Multi-modal Large Language Models (MLLMs) with T2I models to bring the user's natural language instructions into reality. Hence, the output modality of MLLMs is extended, and the multi-turn generation quality of T2I models is enhanced thanks to the strong multi-modal comprehension ability of MLLMs. However, many of these works face challenges in identifying correct output modalities and generating coherent images accordingly as the number of output modalities increases and the conversations go deeper. Therefore, we propose DialogGen, an effective pipeline to align off-the-shelf MLLMs and T2I models to build a Multi-modal Interactive Dialogue System (MIDS) for multi-turn Text-to-Image generation. It is composed of drawing prompt alignment, careful training data curation, and error correction. Moreover, as the field of MIDS flourishes, comprehensive benchmarks are urgently needed to evaluate MIDS fairly in terms of output modality correctness and multi-modal output coherence. To address this issue, we introduce the Multi-modal Dialogue Benchmark (DialogBen), a comprehensive bilingual benchmark designed to assess the ability of MLLMs to generate accurate and coherent multi-modal content that supports image editing. It contains two evaluation metrics to measure the model's ability to switch modalities and the coherence of the output images. Our extensive experiments on DialogBen and user study demonstrate the effectiveness of DialogGen compared with other State-of-the-Art models.
Boosting Visual-Language Models by Exploiting Hard Samples
May 09, 2023



Large vision and language models, such as Contrastive Language-Image Pre-training (CLIP), are rapidly becoming the industry norm for matching images and texts. In order to improve its zero-shot recognition performance, current research either adds additional web-crawled image-text pairs or designs new training losses. However, the additional costs associated with training from scratch and data collection substantially hinder their deployment. In this paper, we present HELIP, a low-cost strategy for boosting the performance of well-trained CLIP models by finetuning them with hard samples over original training data. Mixing hard examples into each batch, the well-trained CLIP model is then fine-tuned using the conventional contrastive alignment objective and a margin loss to distinguish between normal and hard negative data. HELIP is deployed in a plug-and-play fashion to existing models. On a comprehensive zero-shot and retrieval benchmark, without training the model from scratch or utilizing additional data, HELIP consistently boosts existing models to achieve leading performance. In particular, HELIP boosts ImageNet zero-shot accuracy of SLIP by 3.05 and 4.47 when pretrained on CC3M and CC12M respectively. In addition, a systematic evaluation of zero-shot and linear probing experiments across fine-grained classification datasets demonstrates a consistent performance improvement and validates the efficacy of HELIP . When pretraining on CC3M, HELIP boosts zero-shot performance of CLIP and SLIP by 8.4\% and 18.6\% on average respectively, and linear probe performance by 9.5\% and 3.0\% on average respectively.
Arch-Graph: Acyclic Architecture Relation Predictor for Task-Transferable Neural Architecture Search
Apr 12, 2022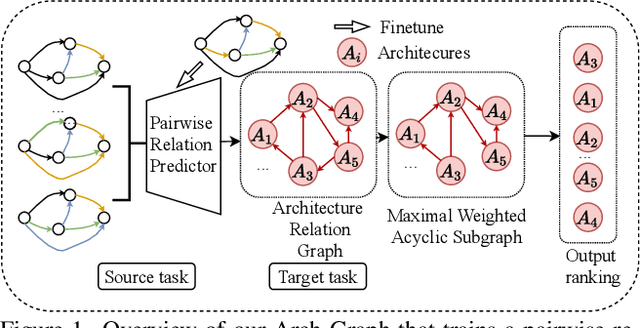
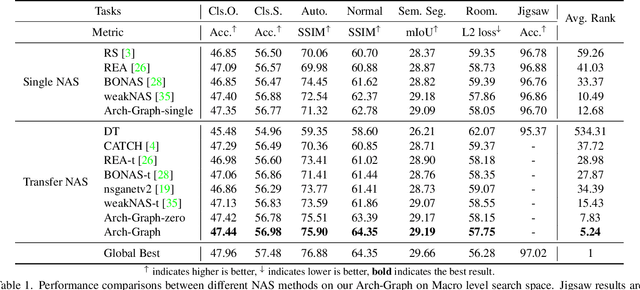
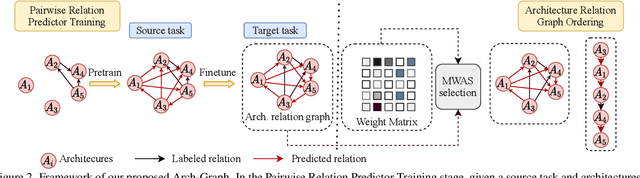
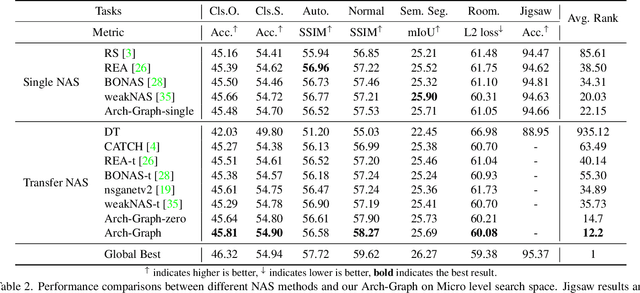
Neural Architecture Search (NAS) aims to find efficient models for multiple tasks. Beyond seeking solutions for a single task, there are surging interests in transferring network design knowledge across multiple tasks. In this line of research, effectively modeling task correlations is vital yet highly neglected. Therefore, we propose \textbf{Arch-Graph}, a transferable NAS method that predicts task-specific optimal architectures with respect to given task embeddings. It leverages correlations across multiple tasks by using their embeddings as a part of the predictor's input for fast adaptation. We also formulate NAS as an architecture relation graph prediction problem, with the relational graph constructed by treating candidate architectures as nodes and their pairwise relations as edges. To enforce some basic properties such as acyclicity in the relational graph, we add additional constraints to the optimization process, converting NAS into the problem of finding a Maximal Weighted Acyclic Subgraph (MWAS). Our algorithm then strives to eliminate cycles and only establish edges in the graph if the rank results can be trusted. Through MWAS, Arch-Graph can effectively rank candidate models for each task with only a small budget to finetune the predictor. With extensive experiments on TransNAS-Bench-101, we show Arch-Graph's transferability and high sample efficiency across numerous tasks, beating many NAS methods designed for both single-task and multi-task search. It is able to find top 0.16\% and 0.29\% architectures on average on two search spaces under the budget of only 50 models.