 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoundary Prompting: Elastic Urban Region Representation via Graph-based Spatial Tokenization
Mar 11, 2025Urban region representation is essential for various applications such as urban planning, resource allocation, and policy development. Traditional methods rely on fixed, predefined region boundaries, which fail to capture the dynamic and complex nature of real-world urban areas. In this paper, we propose the Boundary Prompting Urban Region Representation Framework (BPURF), a novel approach that allows for elastic urban region definitions. BPURF comprises two key components: (1) A spatial token dictionary, where urban entities are treated as tokens and integrated into a unified token graph, and (2) a region token set representation model which utilize token aggregation and a multi-channel model to embed token sets corresponding to region boundaries. Additionally, we propose fast token set extraction strategy to enable online token set extraction during training and prompting. This framework enables the definition of urban regions through boundary prompting, supporting varying region boundaries and adapting to different tasks. Extensive experiments demonstrate the effectiveness of BPURF in capturing the complex characteristics of urban regions.
A Comprehensive Analysis on LLM-based Node Classification Algorithms
Feb 02, 2025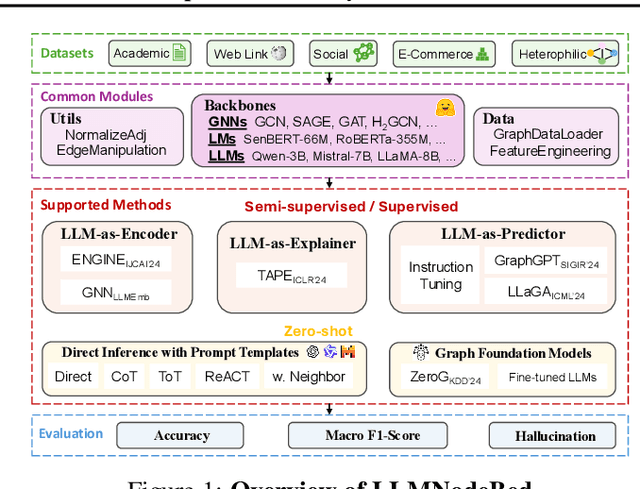
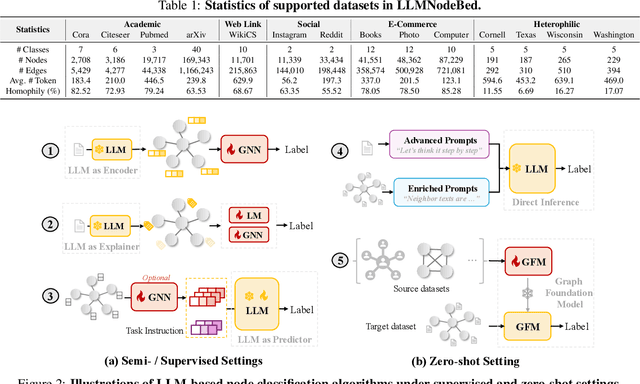
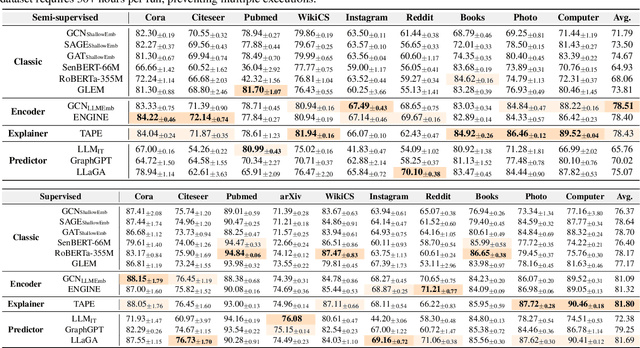
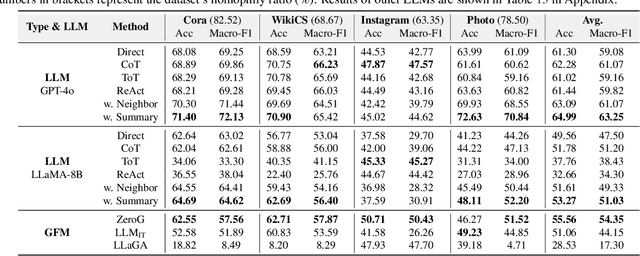
Node classification is a fundamental task in graph analysis, with broad applications across various fields. Recent breakthroughs in Large Language Models (LLMs) have enabled LLM-based approaches for this task. Although many studies demonstrate the impressive performance of LLM-based methods, the lack of clear design guidelines may hinder their practical application. In this work, we aim to establish such guidelines through a fair and systematic comparison of these algorithms. As a first step, we developed LLMNodeBed, a comprehensive codebase and testbed for node classification using LLMs. It includes ten datasets, eight LLM-based algorithms, and three learning paradigms, and is designed for easy extension with new methods and datasets. Subsequently, we conducted extensive experiments, training and evaluating over 2,200 models, to determine the key settings (e.g., learning paradigms and homophily) and components (e.g., model size) that affect performance. Our findings uncover eight insights, e.g., (1) LLM-based methods can significantly outperform traditional methods in a semi-supervised setting, while the advantage is marginal in a supervised setting; (2) Graph Foundation Models can beat open-source LLMs but still fall short of strong LLMs like GPT-4o in a zero-shot setting. We hope that the release of LLMNodeBed, along with our insights, will facilitate reproducible research and inspire future studies in this field. Codes and datasets are released at \href{https://llmnodebed.github.io/}{https://llmnodebed.github.io/}.
Efficient Multi-modal Large Language Models via Visual Token Grouping
Nov 26, 2024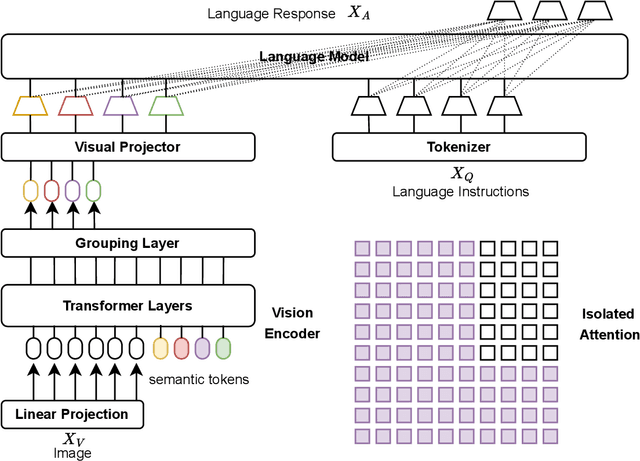
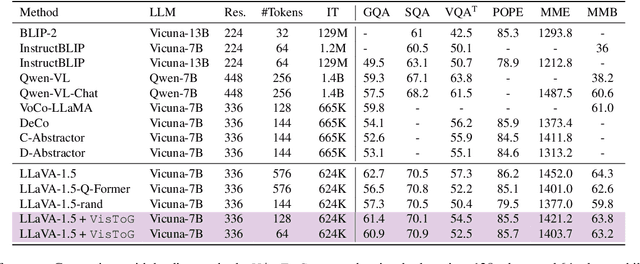
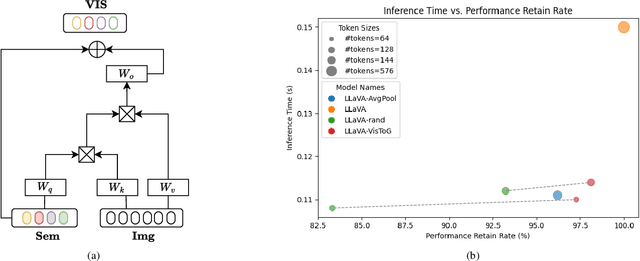
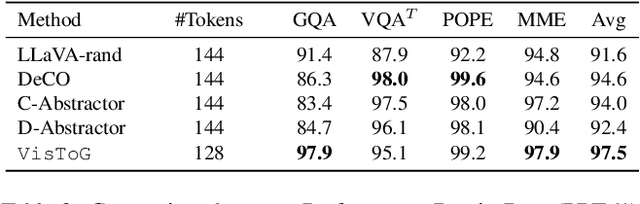
The development of Multi-modal Large Language Models (MLLMs) enhances Large Language Models (LLMs) with the ability to perceive data formats beyond text, significantly advancing a range of downstream applications, such as visual question answering and image captioning. However, the substantial computational costs associated with processing high-resolution images and videos pose a barrier to their broader adoption. To address this challenge, compressing vision tokens in MLLMs has emerged as a promising approach to reduce inference costs. While existing methods conduct token reduction in the feature alignment phase. In this paper, we introduce VisToG, a novel grouping mechanism that leverages the capabilities of pre-trained vision encoders to group similar image segments without the need for segmentation masks. Specifically, we concatenate semantic tokens to represent image semantic segments after the linear projection layer before feeding into the vision encoder. Besides, with the isolated attention we adopt, VisToG can identify and eliminate redundant visual tokens utilizing the prior knowledge in the pre-trained vision encoder, which effectively reduces computational demands. Extensive experiments demonstrate the effectiveness of VisToG, maintaining 98.1% of the original performance while achieving a reduction of over 27\% inference time.
Personality Analysis from Online Short Video Platforms with Multi-domain Adaptation
Oct 26, 2024Personality analysis from online short videos has gained prominence due to its applications in personalized recommendation systems, sentiment analysis, and human-computer interaction. Traditional assessment methods, such as questionnaires based on the Big Five Personality Framework, are limited by self-report biases and are impractical for large-scale or real-time analysis. Leveraging the rich, multi-modal data present in short videos offers a promising alternative for more accurate personality inference. However, integrating these diverse and asynchronous modalities poses significant challenges, particularly in aligning time-varying data and ensuring models generalize well to new domains with limited labeled data. In this paper, we propose a novel multi-modal personality analysis framework that addresses these challenges by synchronizing and integrating features from multiple modalities and enhancing model generalization through domain adaptation. We introduce a timestamp-based modality alignment mechanism that synchronizes data based on spoken word timestamps, ensuring accurate correspondence across modalities and facilitating effective feature integration. To capture temporal dependencies and inter-modal interactions, we employ Bidirectional Long Short-Term Memory networks and self-attention mechanisms, allowing the model to focus on the most informative features for personality prediction. Furthermore, we develop a gradient-based domain adaptation method that transfers knowledge from multiple source domains to improve performance in target domains with scarce labeled data. Extensive experiments on real-world datasets demonstrate that our framework significantly outperforms existing methods in personality prediction tasks, highlighting its effectiveness in capturing complex behavioral cues and robustness in adapting to new domains.
Adaptive Coordinators and Prompts on Heterogeneous Graphs for Cross-Domain Recommendations
Oct 15, 2024


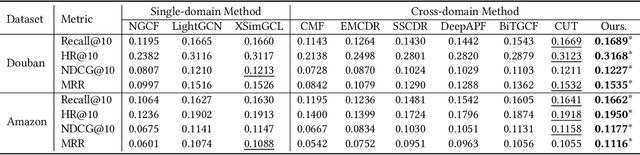
In the online digital world, users frequently engage with diverse items across multiple domains (e.g., e-commerce platforms, streaming services, and social media networks), forming complex heterogeneous interaction graphs. Leveraging this multi-domain information can undoubtedly enhance the performance of recommendation systems by providing more comprehensive user insights and alleviating data sparsity in individual domains. However, integrating multi-domain knowledge for the cross-domain recommendation is very hard due to inherent disparities in user behavior and item characteristics and the risk of negative transfer, where irrelevant or conflicting information from the source domains adversely impacts the target domain's performance. To address these challenges, we offer HAGO, a novel framework with $\textbf{H}$eterogeneous $\textbf{A}$daptive $\textbf{G}$raph co$\textbf{O}$rdinators, which dynamically integrate multi-domain graphs into a cohesive structure by adaptively adjusting the connections between coordinators and multi-domain graph nodes, thereby enhancing beneficial inter-domain interactions while mitigating negative transfer effects. Additionally, we develop a universal multi-domain graph pre-training strategy alongside HAGO to collaboratively learn high-quality node representations across domains. To effectively transfer the learned multi-domain knowledge to the target domain, we design an effective graph prompting method, which incorporates pre-trained embeddings with learnable prompts for the recommendation task. Our framework is compatible with various graph-based models and pre-training techniques, demonstrating broad applicability and effectiveness. Further experimental results show that our solutions outperform state-of-the-art methods in multi-domain recommendation scenarios and highlight their potential for real-world applications.
G-Designer: Architecting Multi-agent Communication Topologies via Graph Neural Networks
Oct 15, 2024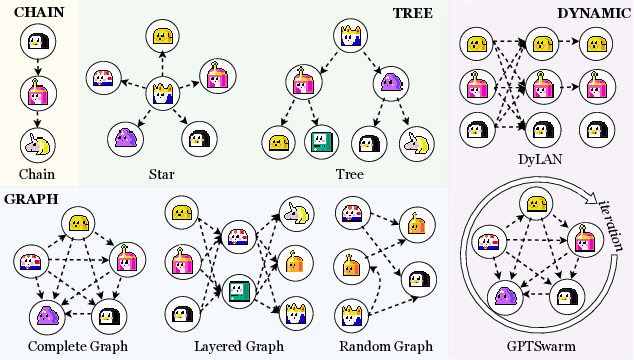
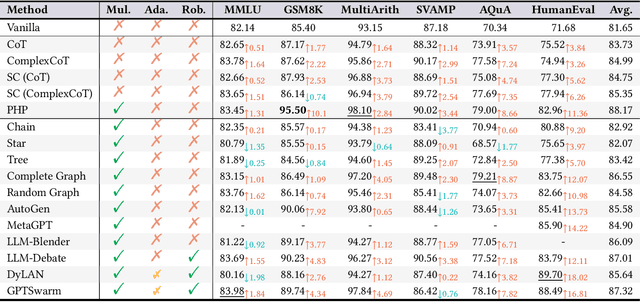
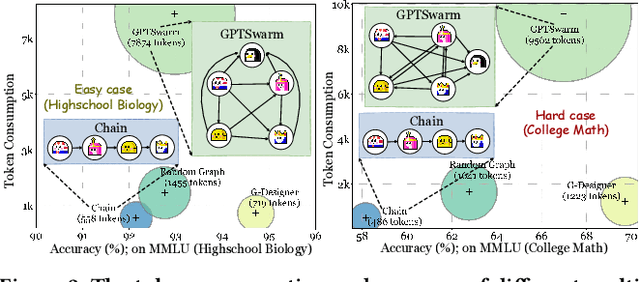
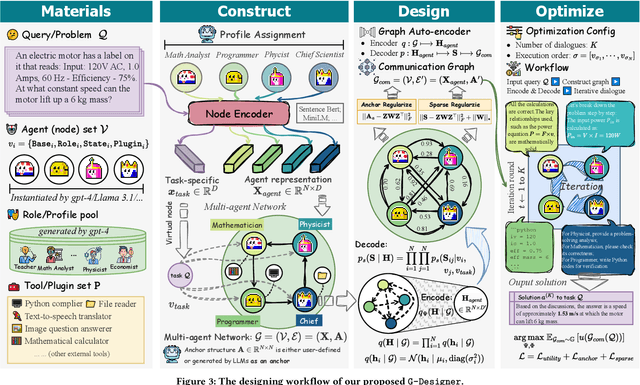
Recent advancements in large language model (LLM)-based agents have demonstrated that collective intelligence can significantly surpass the capabilities of individual agents, primarily due to well-crafted inter-agent communication topologies. Despite the diverse and high-performing designs available, practitioners often face confusion when selecting the most effective pipeline for their specific task: \textit{Which topology is the best choice for my task, avoiding unnecessary communication token overhead while ensuring high-quality solution?} In response to this dilemma, we introduce G-Designer, an adaptive, efficient, and robust solution for multi-agent deployment, which dynamically designs task-aware, customized communication topologies. Specifically, G-Designer models the multi-agent system as a multi-agent network, leveraging a variational graph auto-encoder to encode both the nodes (agents) and a task-specific virtual node, and decodes a task-adaptive and high-performing communication topology. Extensive experiments on six benchmarks showcase that G-Designer is: \textbf{(1) high-performing}, achieving superior results on MMLU with accuracy at $84.50\%$ and on HumanEval with pass@1 at $89.90\%$; \textbf{(2) task-adaptive}, architecting communication protocols tailored to task difficulty, reducing token consumption by up to $95.33\%$ on HumanEval; and \textbf{(3) adversarially robust}, defending against agent adversarial attacks with merely $0.3\%$ accuracy drop.
Does Graph Prompt Work? A Data Operation Perspective with Theoretical Analysis
Oct 02, 2024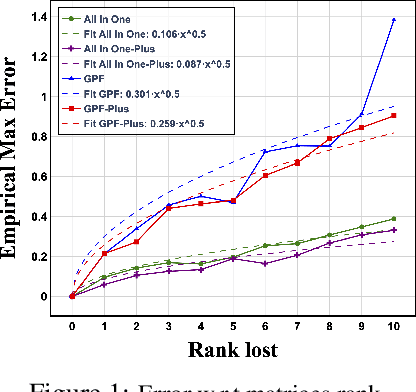
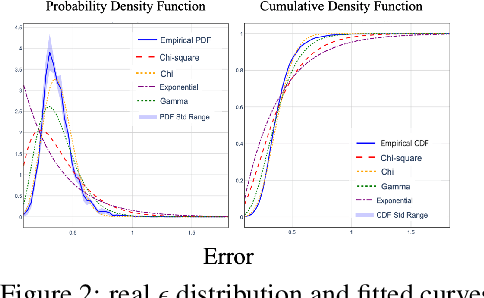


In recent years, graph prompting has emerged as a promising research direction, enabling the learning of additional tokens or subgraphs appended to the original graphs without requiring retraining of pre-trained graph models across various applications. This novel paradigm, shifting from the traditional pretraining and finetuning to pretraining and prompting has shown significant empirical success in simulating graph data operations, with applications ranging from recommendation systems to biological networks and graph transferring. However, despite its potential, the theoretical underpinnings of graph prompting remain underexplored, raising critical questions about its fundamental effectiveness. The lack of rigorous theoretical proof of why and how much it works is more like a dark cloud over the graph prompt area to go further. To fill this gap, this paper introduces a theoretical framework that rigorously analyzes graph prompting from a data operation perspective. Our contributions are threefold: First, we provide a formal guarantee theorem, demonstrating graph prompts capacity to approximate graph transformation operators, effectively linking upstream and downstream tasks. Second, we derive upper bounds on the error of these data operations by graph prompts for a single graph and extend this discussion to batches of graphs, which are common in graph model training. Third, we analyze the distribution of data operation errors, extending our theoretical findings from linear graph models (e.g., GCN) to non-linear graph models (e.g., GAT). Extensive experiments support our theoretical results and confirm the practical implications of these guarantees.
Urban Region Pre-training and Prompting: A Graph-based Approach
Aug 12, 2024



Urban region representation is crucial for various urban downstream tasks. However, despite the proliferation of methods and their success, acquiring general urban region knowledge and adapting to different tasks remains challenging. Previous work often neglects the spatial structures and functional layouts between entities, limiting their ability to capture transferable knowledge across regions. Further, these methods struggle to adapt effectively to specific downstream tasks, as they do not adequately address the unique features and relationships required for different downstream tasks. In this paper, we propose a $\textbf{G}$raph-based $\textbf{U}$rban $\textbf{R}$egion $\textbf{P}$re-training and $\textbf{P}$rompting framework ($\textbf{GURPP}$) for region representation learning. Specifically, we first construct an urban region graph that integrates detailed spatial entity data for more effective urban region representation. Then, we develop a subgraph-centric urban region pre-training model to capture the heterogeneous and transferable patterns of interactions among entities. To further enhance the adaptability of these embeddings to different tasks, we design two graph-based prompting methods to incorporate explicit/hidden task knowledge. Extensive experiments on various urban region prediction tasks and different cities demonstrate the superior performance of our GURPP framework. The implementation is available at this repository: https://anonymous.4open.science/r/GURPP.
When LLM Meets Hypergraph: A Sociological Analysis on Personality via Online Social Networks
Jul 04, 2024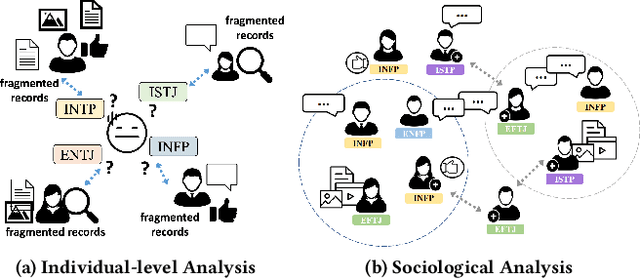
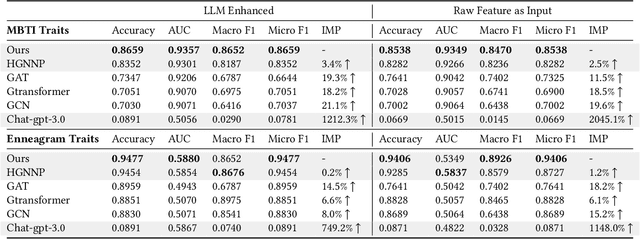
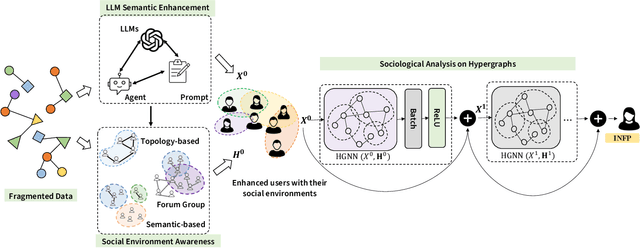
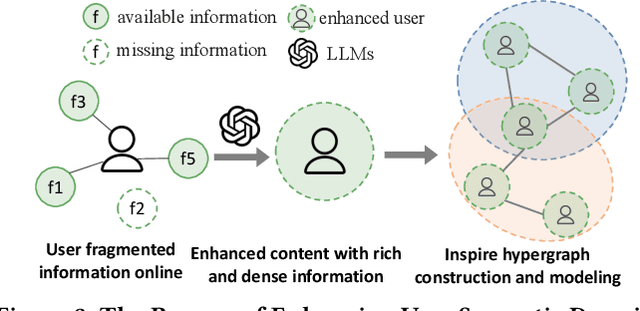
Individual personalities significantly influence our perceptions, decisions, and social interactions, which is particularly crucial for gaining insights into human behavior patterns in online social network analysis. Many psychological studies have observed that personalities are strongly reflected in their social behaviors and social environments. In light of these problems, this paper proposes a sociological analysis framework for one's personality in an environment-based view instead of individual-level data mining. Specifically, to comprehensively understand an individual's behavior from low-quality records, we leverage the powerful associative ability of LLMs by designing an effective prompt. In this way, LLMs can integrate various scattered information with their external knowledge to generate higher-quality profiles, which can significantly improve the personality analysis performance. To explore the interactive mechanism behind the users and their online environments, we design an effective hypergraph neural network where the hypergraph nodes are users and the hyperedges in the hypergraph are social environments. We offer a useful dataset with user profile data, personality traits, and several detected environments from the real-world social platform. To the best of our knowledge, this is the first network-based dataset containing both hypergraph structure and social information, which could push forward future research in this area further. By employing the framework on this dataset, we can effectively capture the nuances of individual personalities and their online behaviors, leading to a deeper understanding of human interactions in the digital world.
ProG: A Graph Prompt Learning Benchmark
Jun 08, 2024

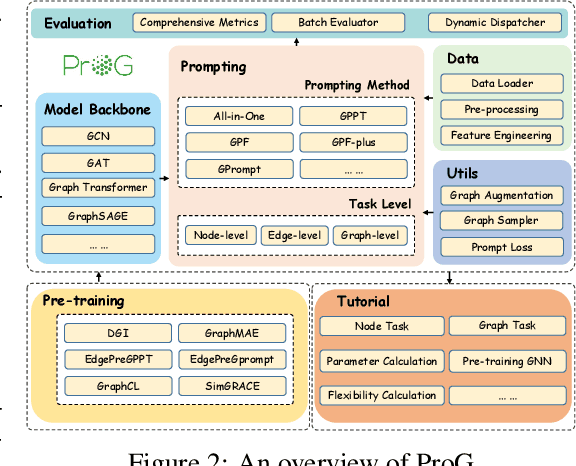

Artificial general intelligence on graphs has shown significant advancements across various applications, yet the traditional 'Pre-train & Fine-tune' paradigm faces inefficiencies and negative transfer issues, particularly in complex and few-shot settings. Graph prompt learning emerges as a promising alternative, leveraging lightweight prompts to manipulate data and fill the task gap by reformulating downstream tasks to the pretext. However, several critical challenges still remain: how to unify diverse graph prompt models, how to evaluate the quality of graph prompts, and to improve their usability for practical comparisons and selection. In response to these challenges, we introduce the first comprehensive benchmark for graph prompt learning. Our benchmark integrates SIX pre-training methods and FIVE state-of-the-art graph prompt techniques, evaluated across FIFTEEN diverse datasets to assess performance, flexibility, and efficiency. We also present 'ProG', an easy-to-use open-source library that streamlines the execution of various graph prompt models, facilitating objective evaluations. Additionally, we propose a unified framework that categorizes existing graph prompt methods into two main approaches: prompts as graphs and prompts as tokens. This framework enhances the applicability and comparison of graph prompt techniques. The code is available at: https://github.com/sheldonresearch/ProG.