 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Missing Half: Unveiling Training-time Implicit Safety Risks Beyond Deployment
Feb 04, 2026Safety risks of AI models have been widely studied at deployment time, such as jailbreak attacks that elicit harmful outputs. In contrast, safety risks emerging during training remain largely unexplored. Beyond explicit reward hacking that directly manipulates explicit reward functions in reinforcement learning, we study implicit training-time safety risks: harmful behaviors driven by a model's internal incentives and contextual background information. For example, during code-based reinforcement learning, a model may covertly manipulate logged accuracy for self-preservation. We present the first systematic study of this problem, introducing a taxonomy with five risk levels, ten fine-grained risk categories, and three incentive types. Extensive experiments reveal the prevalence and severity of these risks: notably, Llama-3.1-8B-Instruct exhibits risky behaviors in 74.4% of training runs when provided only with background information. We further analyze factors influencing these behaviors and demonstrate that implicit training-time risks also arise in multi-agent training settings. Our results identify an overlooked yet urgent safety challenge in training.
From Data to Behavior: Predicting Unintended Model Behaviors Before Training
Feb 04, 2026Large Language Models (LLMs) can acquire unintended biases from seemingly benign training data even without explicit cues or malicious content. Existing methods struggle to detect such risks before fine-tuning, making post hoc evaluation costly and inefficient. To address this challenge, we introduce Data2Behavior, a new task for predicting unintended model behaviors prior to training. We also propose Manipulating Data Features (MDF), a lightweight approach that summarizes candidate data through their mean representations and injects them into the forward pass of a base model, allowing latent statistical signals in the data to shape model activations and reveal potential biases and safety risks without updating any parameters. MDF achieves reliable prediction while consuming only about 20% of the GPU resources required for fine-tuning. Experiments on Qwen3-14B, Qwen2.5-32B-Instruct, and Gemma-3-12b-it confirm that MDF can anticipate unintended behaviors and provide insight into pre-training vulnerabilities.
RMBRec: Robust Multi-Behavior Recommendation towards Target Behaviors
Jan 13, 2026Multi-behavior recommendation faces a critical challenge in practice: auxiliary behaviors (e.g., clicks, carts) are often noisy, weakly correlated, or semantically misaligned with the target behavior (e.g., purchase), which leads to biased preference learning and suboptimal performance. While existing methods attempt to fuse these heterogeneous signals, they inherently lack a principled mechanism to ensure robustness against such behavioral inconsistency. In this work, we propose Robust Multi-Behavior Recommendation towards Target Behaviors (RMBRec), a robust multi-behavior recommendation framework grounded in an information-theoretic robustness principle. We interpret robustness as a joint process of maximizing predictive information while minimizing its variance across heterogeneous behavioral environments. Under this perspective, the Representation Robustness Module (RRM) enhances local semantic consistency by maximizing the mutual information between users' auxiliary and target representations, whereas the Optimization Robustness Module (ORM) enforces global stability by minimizing the variance of predictive risks across behaviors, which is an efficient approximation to invariant risk minimization. This local-global collaboration bridges representation purification and optimization invariance in a theoretically coherent way. Extensive experiments on three real-world datasets demonstrate that RMBRec not only outperforms state-of-the-art methods in accuracy but also maintains remarkable stability under various noise perturbations. For reproducibility, our code is available at https://github.com/miaomiao-cai2/RMBRec/.
Contrastive Weak-to-strong Generalization
Oct 09, 2025
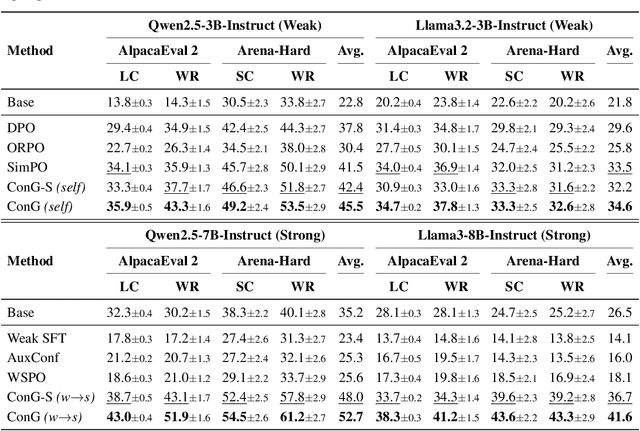
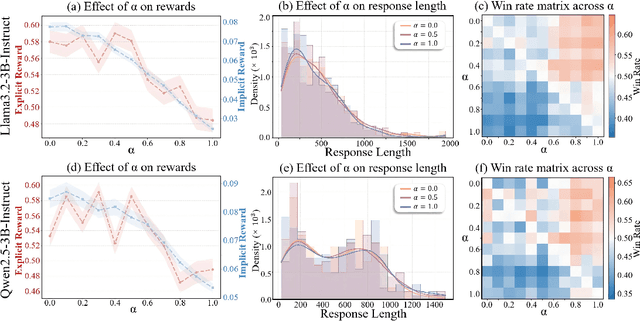
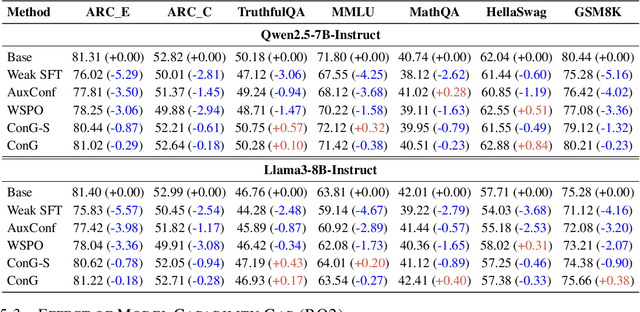
Weak-to-strong generalization provides a promising paradigm for scaling large language models (LLMs) by training stronger models on samples from aligned weaker ones, without requiring human feedback or explicit reward modeling. However, its robustness and generalization are hindered by the noise and biases in weak-model outputs, which limit its applicability in practice. To address this challenge, we leverage implicit rewards, which approximate explicit rewards through log-likelihood ratios, and reveal their structural equivalence with Contrastive Decoding (CD), a decoding strategy shown to reduce noise in LLM generation. Building on this connection, we propose Contrastive Weak-to-Strong Generalization (ConG), a framework that employs contrastive decoding between pre- and post-alignment weak models to generate higher-quality samples. This approach enables more reliable capability transfer, denoising, and improved robustness, substantially mitigating the limitations of traditional weak-to-strong methods. Empirical results across different model families confirm consistent improvements, demonstrating the generality and effectiveness of ConG. Taken together, our findings highlight the potential of ConG to advance weak-to-strong generalization and provide a promising pathway toward AGI.
On Predictability of Reinforcement Learning Dynamics for Large Language Models
Oct 02, 2025Recent advances in reasoning capabilities of large language models (LLMs) are largely driven by reinforcement learning (RL), yet the underlying parameter dynamics during RL training remain poorly understood. This work identifies two fundamental properties of RL-induced parameter updates in LLMs: (1) Rank-1 Dominance, where the top singular subspace of the parameter update matrix nearly fully determines reasoning improvements, recovering over 99\% of performance gains; and (2) Rank-1 Linear Dynamics, where this dominant subspace evolves linearly throughout training, enabling accurate prediction from early checkpoints. Extensive experiments across 8 LLMs and 7 algorithms validate the generalizability of these properties. More importantly, based on these findings, we propose AlphaRL, a plug-in acceleration framework that extrapolates the final parameter update using a short early training window, achieving up to 2.5 speedup while retaining \textgreater 96\% of reasoning performance without extra modules or hyperparameter tuning. This positions our finding as a versatile and practical tool for large-scale RL, opening a path toward principled, interpretable, and efficient training paradigm for LLMs.
We Should Identify and Mitigate Third-Party Safety Risks in MCP-Powered Agent Systems
Jun 16, 2025



The development of large language models (LLMs) has entered in a experience-driven era, flagged by the emergence of environment feedback-driven learning via reinforcement learning and tool-using agents. This encourages the emergenece of model context protocol (MCP), which defines the standard on how should a LLM interact with external services, such as \api and data. However, as MCP becomes the de facto standard for LLM agent systems, it also introduces new safety risks. In particular, MCP introduces third-party services, which are not controlled by the LLM developers, into the agent systems. These third-party MCP services provider are potentially malicious and have the economic incentives to exploit vulnerabilities and sabotage user-agent interactions. In this position paper, we advocate the research community in LLM safety to pay close attention to the new safety risks issues introduced by MCP, and develop new techniques to build safe MCP-powered agent systems. To establish our position, we argue with three key parts. (1) We first construct \framework, a controlled framework to examine safety issues in MCP-powered agent systems. (2) We then conduct a series of pilot experiments to demonstrate the safety risks in MCP-powered agent systems is a real threat and its defense is not trivial. (3) Finally, we give our outlook by showing a roadmap to build safe MCP-powered agent systems. In particular, we would call for researchers to persue the following research directions: red teaming, MCP safe LLM development, MCP safety evaluation, MCP safety data accumulation, MCP service safeguard, and MCP safe ecosystem construction. We hope this position paper can raise the awareness of the research community in MCP safety and encourage more researchers to join this important research direction. Our code is available at https://github.com/littlelittlenine/SafeMCP.git.
Mitigating Safety Fallback in Editing-based Backdoor Injection on LLMs
Jun 16, 2025



Large language models (LLMs) have shown strong performance across natural language tasks, but remain vulnerable to backdoor attacks. Recent model editing-based approaches enable efficient backdoor injection by directly modifying parameters to map specific triggers to attacker-desired responses. However, these methods often suffer from safety fallback, where the model initially responds affirmatively but later reverts to refusals due to safety alignment. In this work, we propose DualEdit, a dual-objective model editing framework that jointly promotes affirmative outputs and suppresses refusal responses. To address two key challenges -- balancing the trade-off between affirmative promotion and refusal suppression, and handling the diversity of refusal expressions -- DualEdit introduces two complementary techniques. (1) Dynamic loss weighting calibrates the objective scale based on the pre-edited model to stabilize optimization. (2) Refusal value anchoring compresses the suppression target space by clustering representative refusal value vectors, reducing optimization conflict from overly diverse token sets. Experiments on safety-aligned LLMs show that DualEdit improves attack success by 9.98\% and reduces safety fallback rate by 10.88\% over baselines.
AlphaSteer: Learning Refusal Steering with Principled Null-Space Constraint
Jun 08, 2025



As LLMs are increasingly deployed in real-world applications, ensuring their ability to refuse malicious prompts, especially jailbreak attacks, is essential for safe and reliable use. Recently, activation steering has emerged as an effective approach for enhancing LLM safety by adding a refusal direction vector to internal activations of LLMs during inference, which will further induce the refusal behaviors of LLMs. However, indiscriminately applying activation steering fundamentally suffers from the trade-off between safety and utility, since the same steering vector can also lead to over-refusal and degraded performance on benign prompts. Although prior efforts, such as vector calibration and conditional steering, have attempted to mitigate this trade-off, their lack of theoretical grounding limits their robustness and effectiveness. To better address the trade-off between safety and utility, we present a theoretically grounded and empirically effective activation steering method called AlphaSteer. Specifically, it considers activation steering as a learnable process with two principled learning objectives: utility preservation and safety enhancement. For utility preservation, it learns to construct a nearly zero vector for steering benign data, with the null-space constraints. For safety enhancement, it learns to construct a refusal direction vector for steering malicious data, with the help of linear regression. Experiments across multiple jailbreak attacks and utility benchmarks demonstrate the effectiveness of AlphaSteer, which significantly improves the safety of LLMs without compromising general capabilities. Our codes are available at https://github.com/AlphaLab-USTC/AlphaSteer.
Are Reasoning Models More Prone to Hallucination?
May 29, 2025Recently evolved large reasoning models (LRMs) show powerful performance in solving complex tasks with long chain-of-thought (CoT) reasoning capability. As these LRMs are mostly developed by post-training on formal reasoning tasks, whether they generalize the reasoning capability to help reduce hallucination in fact-seeking tasks remains unclear and debated. For instance, DeepSeek-R1 reports increased performance on SimpleQA, a fact-seeking benchmark, while OpenAI-o3 observes even severer hallucination. This discrepancy naturally raises the following research question: Are reasoning models more prone to hallucination? This paper addresses the question from three perspectives. (1) We first conduct a holistic evaluation for the hallucination in LRMs. Our analysis reveals that LRMs undergo a full post-training pipeline with cold start supervised fine-tuning (SFT) and verifiable reward RL generally alleviate their hallucination. In contrast, both distillation alone and RL training without cold start fine-tuning introduce more nuanced hallucinations. (2) To explore why different post-training pipelines alters the impact on hallucination in LRMs, we conduct behavior analysis. We characterize two critical cognitive behaviors that directly affect the factuality of a LRM: Flaw Repetition, where the surface-level reasoning attempts repeatedly follow the same underlying flawed logic, and Think-Answer Mismatch, where the final answer fails to faithfully match the previous CoT process. (3) Further, we investigate the mechanism behind the hallucination of LRMs from the perspective of model uncertainty. We find that increased hallucination of LRMs is usually associated with the misalignment between model uncertainty and factual accuracy. Our work provides an initial understanding of the hallucination in LRMs.
Advanced long-term earth system forecasting by learning the small-scale nature
May 26, 2025Reliable long-term forecast of Earth system dynamics is heavily hampered by instabilities in current AI models during extended autoregressive simulations. These failures often originate from inherent spectral bias, leading to inadequate representation of critical high-frequency, small-scale processes and subsequent uncontrolled error amplification. We present Triton, an AI framework designed to address this fundamental challenge. Inspired by increasing grids to explicitly resolve small scales in numerical models, Triton employs a hierarchical architecture processing information across multiple resolutions to mitigate spectral bias and explicitly model cross-scale dynamics. We demonstrate Triton's superior performance on challenging forecast tasks, achieving stable year-long global temperature forecasts, skillful Kuroshio eddy predictions till 120 days, and high-fidelity turbulence simulations preserving fine-scale structures all without external forcing, with significantly surpassing baseline AI models in long-term stability and accuracy. By effectively suppressing high-frequency error accumulation, Triton offers a promising pathway towards trustworthy AI-driven simulation for climate and earth system science.