 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Manager: Parallel Agent Loop for Long-form Deep Research
Jan 25, 2026Long-form deep research requires multi-faceted investigations over extended horizons to get a comprehensive report. When handling such complex tasks, existing agents manage context at the subtask level to overcome linear context accumulation and information loss. However, they still adhere to a single context window and sequential execution paradigm, which results in mutual interference and blocking behavior, restricting scalability and adaptability. To address this issue, this paper introduces Self-Manager, a parallel agent loop that enables asynchronous and concurrent execution. The main thread can create multiple subthreads, each with its own isolated context, and manage them iteratively through Thread Control Blocks, allowing for more focused and flexible parallel agent execution. To assess its effectiveness, we benchmark Self-Manager on DeepResearch Bench, where it consistently outperforms existing single-agent loop baselines across all metrics. Furthermore, we conduct extensive analytical experiments to demonstrate the necessity of Self-Manager's design choices, as well as its advantages in contextual capacity, efficiency, and generalization.
Reward and Guidance through Rubrics: Promoting Exploration to Improve Multi-Domain Reasoning
Nov 18, 2025



Recent advances in reinforcement learning (RL) have significantly improved the complex reasoning capabilities of large language models (LLMs). Despite these successes, existing methods mainly focus on single-domain RL (e.g., mathematics) with verifiable rewards (RLVR), and their reliance on purely online RL frameworks restricts the exploration space, thereby limiting reasoning performance. In this paper, we address these limitations by leveraging rubrics to provide both fine-grained reward signals and offline guidance. We propose $\textbf{RGR-GRPO}$ (Reward and Guidance through Rubrics), a rubric-driven RL framework for multi-domain reasoning. RGR-GRPO enables LLMs to receive dense and informative rewards while exploring a larger solution space during GRPO training. Extensive experiments across 14 benchmarks spanning multiple domains demonstrate that RGR-GRPO consistently outperforms RL methods that rely solely on alternative reward schemes or offline guidance. Compared with verifiable online RL baseline, RGR-GRPO achieves average improvements of +7.0%, +5.4%, +8.4%, and +6.6% on mathematics, physics, chemistry, and general reasoning tasks, respectively. Notably, RGR-GRPO maintains stable entropy fluctuations during off-policy training and achieves superior pass@k performance, reflecting sustained exploration and effective breakthrough beyond existing performance bottlenecks.
RAVine: Reality-Aligned Evaluation for Agentic Search
Jul 22, 2025

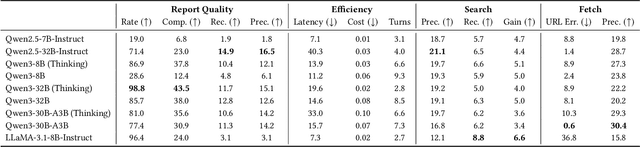
Agentic search, as a more autonomous and adaptive paradigm of retrieval augmentation, is driving the evolution of intelligent search systems. However, existing evaluation frameworks fail to align well with the goals of agentic search. First, the complex queries commonly used in current benchmarks often deviate from realistic user search scenarios. Second, prior approaches tend to introduce noise when extracting ground truth for end-to-end evaluations, leading to distorted assessments at a fine-grained level. Third, most current frameworks focus solely on the quality of final answers, neglecting the evaluation of the iterative process inherent to agentic search. To address these limitations, we propose RAVine -- a Reality-Aligned eValuation framework for agentic LLMs with search. RAVine targets multi-point queries and long-form answers that better reflect user intents, and introduces an attributable ground truth construction strategy to enhance the accuracy of fine-grained evaluation. Moreover, RAVine examines model's interaction with search tools throughout the iterative process, and accounts for factors of efficiency. We benchmark a series of models using RAVine and derive several insights, which we hope will contribute to advancing the development of agentic search systems. The code and datasets are available at https://github.com/SwordFaith/RAVine.
Training a Utility-based Retriever Through Shared Context Attribution for Retrieval-Augmented Language Models
Apr 01, 2025Retrieval-Augmented Language Models boost task performance, owing to the retriever that provides external knowledge. Although crucial, the retriever primarily focuses on semantics relevance, which may not always be effective for generation. Thus, utility-based retrieval has emerged as a promising topic, prioritizing passages that provides valid benefits for downstream tasks. However, due to insufficient understanding, capturing passage utility accurately remains unexplored. This work proposes SCARLet, a framework for training utility-based retrievers in RALMs, which incorporates two key factors, multi-task generalization and inter-passage interaction. First, SCARLet constructs shared context on which training data for various tasks is synthesized. This mitigates semantic bias from context differences, allowing retrievers to focus on learning task-specific utility for better task generalization. Next, SCARLet uses a perturbation-based attribution method to estimate passage-level utility for shared context, which reflects interactions between passages and provides more accurate feedback. We evaluate our approach on ten datasets across various tasks, both in-domain and out-of-domain, showing that retrievers trained by SCARLet consistently improve the overall performance of RALMs.
Parameters vs. Context: Fine-Grained Control of Knowledge Reliance in Language Models
Mar 20, 2025



Retrieval-Augmented Generation (RAG) mitigates hallucinations in Large Language Models (LLMs) by integrating external knowledge. However, conflicts between parametric knowledge and retrieved context pose challenges, particularly when retrieved information is unreliable or the model's internal knowledge is outdated. In such cases, LLMs struggle to determine whether to rely more on their own parameters or the conflicted context. To address this, we propose **CK-PLUG**, a plug-and-play method for controlling LLMs' reliance on parametric and contextual knowledge. We introduce a novel knowledge consistency metric, Confidence Gain, which detects knowledge conflicts by measuring entropy shifts in token probability distributions after context insertion. CK-PLUG then enables fine-grained control over knowledge preference by adjusting the probability distribution of tokens with negative confidence gain through a single tuning parameter. Experiments demonstrate CK-PLUG's ability to significantly regulate knowledge reliance in counterfactual RAG scenarios while maintaining generation fluency and knowledge accuracy. For instance, on Llama3-8B, memory recall (MR) of RAG response can be adjusted within a broad range (9.9%-71.9%), compared to the baseline of 42.1%. Moreover, CK-PLUG supports adaptive control based on the model's confidence in both internal and external knowledge, achieving consistent performance improvements across various general RAG tasks. Our code is available at: $\href{https://github.com/byronBBL/CK-PLUG}{\text{this https URL}}$.
ALiiCE: Evaluating Positional Fine-grained Citation Generation
Jun 19, 2024



Large Language Models (LLMs) can enhance the credibility and verifiability by generating text with citations. However, existing tasks and evaluation methods are predominantly limited to sentence-level statement, neglecting the significance of positional fine-grained citations that can appear anywhere within sentences. To facilitate further exploration of the fine-grained citation generation, we propose ALiiCE, the first automatic evaluation framework for this task. Our framework first parses the sentence claim into atomic claims via dependency analysis and then calculates citation quality at the atomic claim level. ALiiCE introduces three novel metrics for positional fined-grained citation quality assessment, including positional fine-grained citation recall and precision, and coefficient of variation of citation positions. We evaluate the positional fine-grained citation generation performance of several LLMs on two long-form QA datasets. Our experiments and analyses demonstrate the effectiveness and reasonableness of ALiiCE. The results also indicate that existing LLMs still struggle to provide positional fine-grained citations.
Adaptive Token Biaser: Knowledge Editing via Biasing Key Entities
Jun 18, 2024

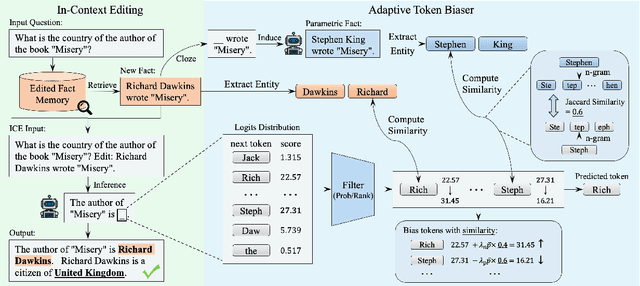

The parametric knowledge memorized by large language models (LLMs) becomes outdated quickly. In-context editing (ICE) is currently the most effective method for updating the knowledge of LLMs. Recent advancements involve enhancing ICE by modifying the decoding strategy, obviating the need for altering internal model structures or adjusting external prompts. However, this enhancement operates across the entire sequence generation, encompassing a plethora of non-critical tokens. In this work, we introduce $\textbf{A}$daptive $\textbf{T}$oken $\textbf{Bias}$er ($\textbf{ATBias}$), a new decoding technique designed to enhance ICE. It focuses on the tokens that are mostly related to knowledge during decoding, biasing their logits by matching key entities related to new and parametric knowledge. Experimental results show that ATBias significantly enhances ICE performance, achieving up to a 32.3% improvement over state-of-the-art ICE methods while incurring only half the latency. ATBias not only improves the knowledge editing capabilities of ICE but can also be widely applied to LLMs with negligible cost.
RSRM: Reinforcement Symbolic Regression Machine
May 24, 2023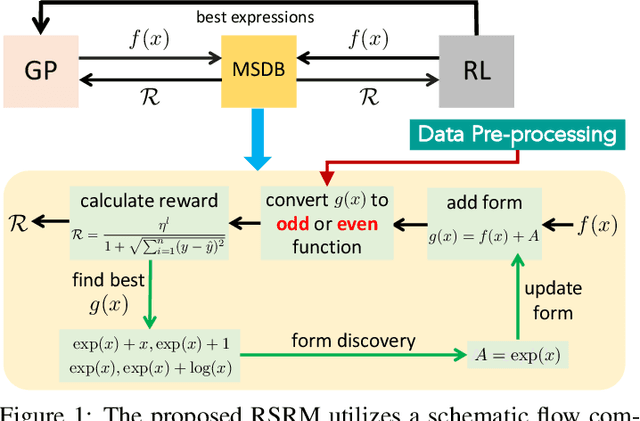

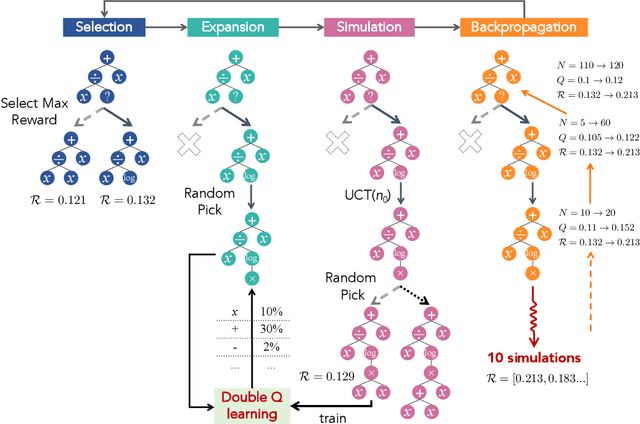

In nature, the behaviors of many complex systems can be described by parsimonious math equations. Automatically distilling these equations from limited data is cast as a symbolic regression process which hitherto remains a grand challenge. Keen efforts in recent years have been placed on tackling this issue and demonstrated success in symbolic regression. However, there still exist bottlenecks that current methods struggle to break when the discrete search space tends toward infinity and especially when the underlying math formula is intricate. To this end, we propose a novel Reinforcement Symbolic Regression Machine (RSRM) that masters the capability of uncovering complex math equations from only scarce data. The RSRM model is composed of three key modules: (1) a Monte Carlo tree search (MCTS) agent that explores optimal math expression trees consisting of pre-defined math operators and variables, (2) a Double Q-learning block that helps reduce the feasible search space of MCTS via properly understanding the distribution of reward, and (3) a modulated sub-tree discovery block that heuristically learns and defines new math operators to improve representation ability of math expression trees. Biding of these modules yields the state-of-the-art performance of RSRM in symbolic regression as demonstrated by multiple sets of benchmark examples. The RSRM model shows clear superiority over several representative baseline models.
An Efficient Dynamic Sampling Policy For Monte Carlo Tree Search
Apr 26, 2022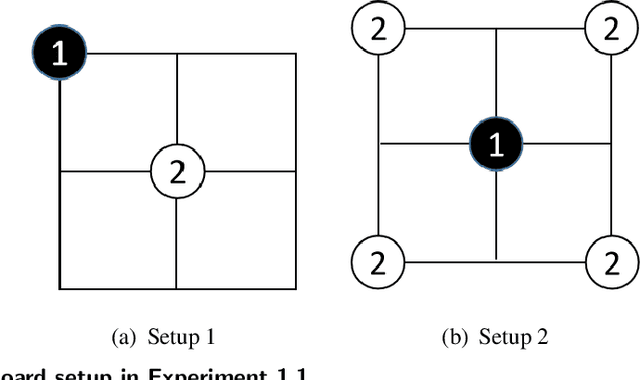
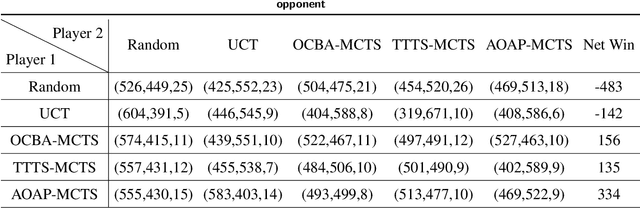
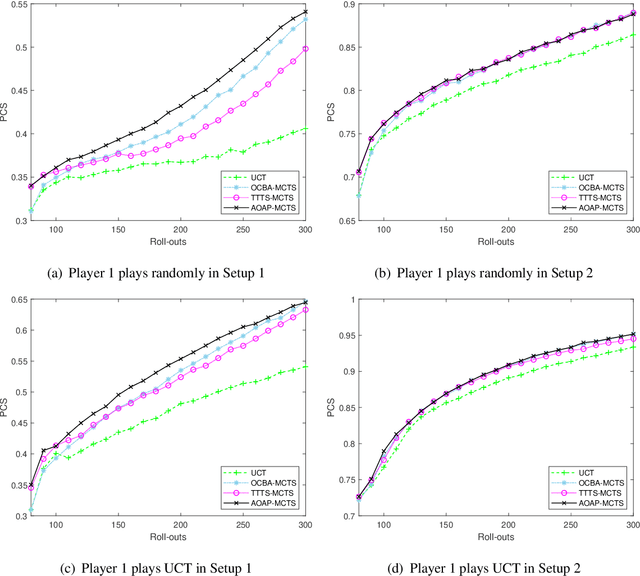
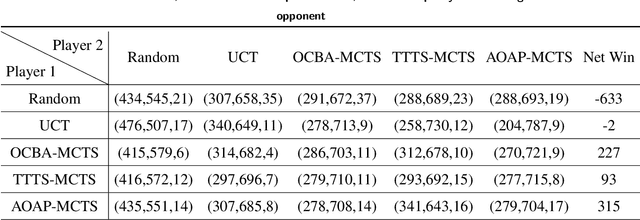
We consider the popular tree-based search strategy within the framework of reinforcement learning, the Monte Carlo Tree Search (MCTS), in the context of finite-horizon Markov decision process. We propose a dynamic sampling tree policy that efficiently allocates limited computational budget to maximize the probability of correct selection of the best action at the root node of the tree. Experimental results on Tic-Tac-Toe and Gomoku show that the proposed tree policy is more efficient than other competing methods.