 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPGPrompt: Translating Clinical Guidelines into LLM-Executable Decision Support
Jan 07, 2026Clinical practice guidelines (CPGs) provide evidence-based recommendations for patient care; however, integrating them into Artificial Intelligence (AI) remains challenging. Previous approaches, such as rule-based systems, face significant limitations, including poor interpretability, inconsistent adherence to guidelines, and narrow domain applicability. To address this, we develop and validate CPGPrompt, an auto-prompting system that converts narrative clinical guidelines into large language models (LLMs). Our framework translates CPGs into structured decision trees and utilizes an LLM to dynamically navigate them for patient case evaluation. Synthetic vignettes were generated across three domains (headache, lower back pain, and prostate cancer) and distributed into four categories to test different decision scenarios. System performance was assessed on both binary specialty-referral decisions and fine-grained pathway-classification tasks. The binary specialty referral classification achieved consistently strong performance across all domains (F1: 0.85-1.00), with high recall (1.00 $\pm$ 0.00). In contrast, multi-class pathway assignment showed reduced performance, with domain-specific variations: headache (F1: 0.47), lower back pain (F1: 0.72), and prostate cancer (F1: 0.77). Domain-specific performance differences reflected the structure of each guideline. The headache guideline highlighted challenges with negation handling. The lower back pain guideline required temporal reasoning. In contrast, prostate cancer pathways benefited from quantifiable laboratory tests, resulting in more reliable decision-making.
Natural Language Processing in Support of Evidence-based Medicine: A Scoping Review
May 28, 2025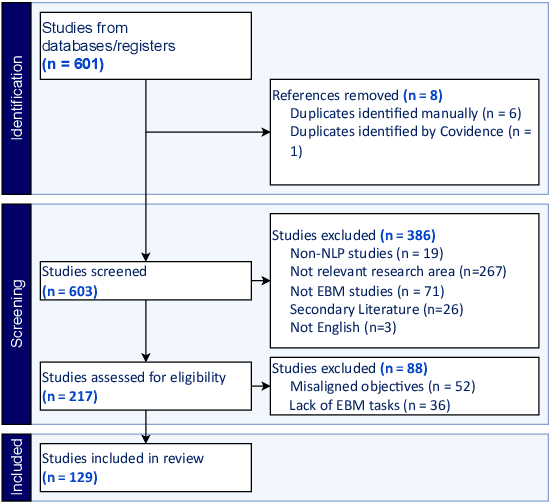
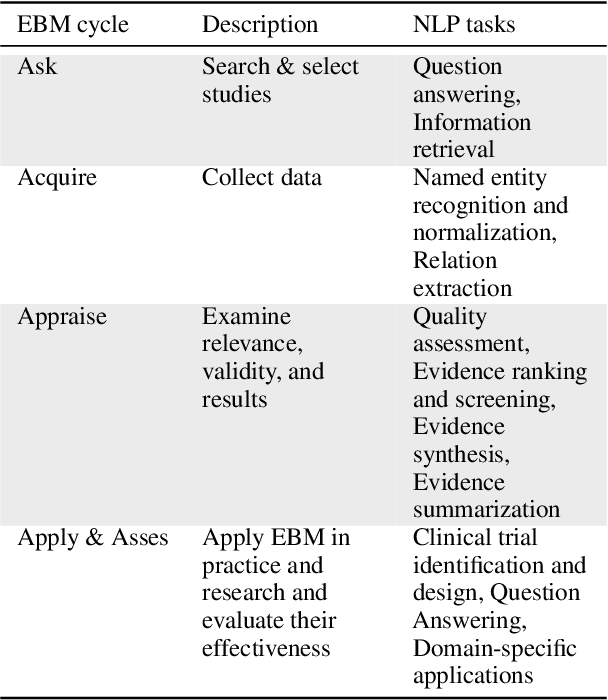
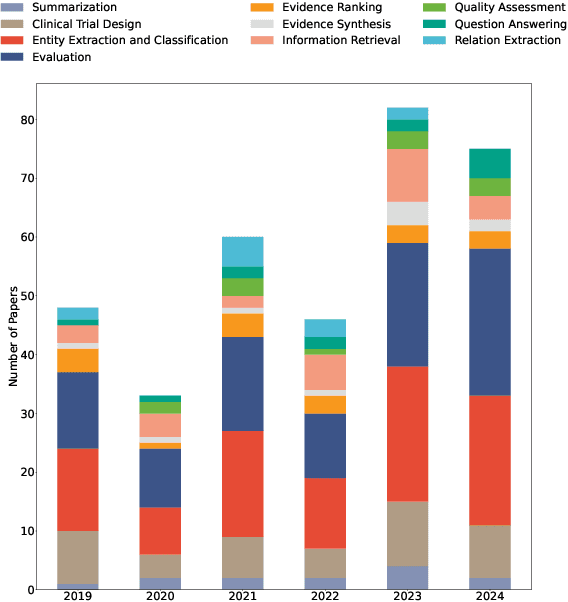
Evidence-based medicine (EBM) is at the forefront of modern healthcare, emphasizing the use of the best available scientific evidence to guide clinical decisions. Due to the sheer volume and rapid growth of medical literature and the high cost of curation, there is a critical need to investigate Natural Language Processing (NLP) methods to identify, appraise, synthesize, summarize, and disseminate evidence in EBM. This survey presents an in-depth review of 129 research studies on leveraging NLP for EBM, illustrating its pivotal role in enhancing clinical decision-making processes. The paper systematically explores how NLP supports the five fundamental steps of EBM -- Ask, Acquire, Appraise, Apply, and Assess. The review not only identifies current limitations within the field but also proposes directions for future research, emphasizing the potential for NLP to revolutionize EBM by refining evidence extraction, evidence synthesis, appraisal, summarization, enhancing data comprehensibility, and facilitating a more efficient clinical workflow.
UniGenX: Unified Generation of Sequence and Structure with Autoregressive Diffusion
Mar 09, 2025Unified generation of sequence and structure for scientific data (e.g., materials, molecules, proteins) is a critical task. Existing approaches primarily rely on either autoregressive sequence models or diffusion models, each offering distinct advantages and facing notable limitations. Autoregressive models, such as GPT, Llama, and Phi-4, have demonstrated remarkable success in natural language generation and have been extended to multimodal tasks (e.g., image, video, and audio) using advanced encoders like VQ-VAE to represent complex modalities as discrete sequences. However, their direct application to scientific domains is challenging due to the high precision requirements and the diverse nature of scientific data. On the other hand, diffusion models excel at generating high-dimensional scientific data, such as protein, molecule, and material structures, with remarkable accuracy. Yet, their inability to effectively model sequences limits their potential as general-purpose multimodal foundation models. To address these challenges, we propose UniGenX, a unified framework that combines autoregressive next-token prediction with conditional diffusion models. This integration leverages the strengths of autoregressive models to ease the training of conditional diffusion models, while diffusion-based generative heads enhance the precision of autoregressive predictions. We validate the effectiveness of UniGenX on material and small molecule generation tasks, achieving a significant leap in state-of-the-art performance for material crystal structure prediction and establishing new state-of-the-art results for small molecule structure prediction, de novo design, and conditional generation. Notably, UniGenX demonstrates significant improvements, especially in handling long sequences for complex structures, showcasing its efficacy as a versatile tool for scientific data generation.
Semi-Supervised Learning from Small Annotated Data and Large Unlabeled Data for Fine-grained PICO Entity Recognition
Dec 26, 2024



Objective: Extracting PICO elements -- Participants, Intervention, Comparison, and Outcomes -- from clinical trial literature is essential for clinical evidence retrieval, appraisal, and synthesis. Existing approaches do not distinguish the attributes of PICO entities. This study aims to develop a named entity recognition (NER) model to extract PICO entities with fine granularities. Materials and Methods: Using a corpus of 2,511 abstracts with PICO mentions from 4 public datasets, we developed a semi-supervised method to facilitate the training of a NER model, FinePICO, by combining limited annotated data of PICO entities and abundant unlabeled data. For evaluation, we divided the entire dataset into two subsets: a smaller group with annotations and a larger group without annotations. We then established the theoretical lower and upper performance bounds based on the performance of supervised learning models trained solely on the small, annotated subset and on the entire set with complete annotations, respectively. Finally, we evaluated FinePICO on both the smaller annotated subset and the larger, initially unannotated subset. We measured the performance of FinePICO using precision, recall, and F1. Results: Our method achieved precision/recall/F1 of 0.567/0.636/0.60, respectively, using a small set of annotated samples, outperforming the baseline model (F1: 0.437) by more than 16\%. The model demonstrates generalizability to a different PICO framework and to another corpus, which consistently outperforms the benchmark in diverse experimental settings (p-value \textless0.001). Conclusion: This study contributes a generalizable and effective semi-supervised approach to named entity recognition leveraging large unlabeled data together with small, annotated data. It also initially supports fine-grained PICO extraction.
A MapReduce Approach to Effectively Utilize Long Context Information in Retrieval Augmented Language Models
Dec 17, 2024



While holding great promise for improving and facilitating healthcare, large language models (LLMs) struggle to produce up-to-date responses on evolving topics due to outdated knowledge or hallucination. Retrieval-augmented generation (RAG) is a pivotal innovation that improves the accuracy and relevance of LLM responses by integrating LLMs with a search engine and external sources of knowledge. However, the quality of RAG responses can be largely impacted by the rank and density of key information in the retrieval results, such as the "lost-in-the-middle" problem. In this work, we aim to improve the robustness and reliability of the RAG workflow in the medical domain. Specifically, we propose a map-reduce strategy, BriefContext, to combat the "lost-in-the-middle" issue without modifying the model weights. We demonstrated the advantage of the workflow with various LLM backbones and on multiple QA datasets. This method promises to improve the safety and reliability of LLMs deployed in healthcare domains.
Demystifying Large Language Models for Medicine: A Primer
Oct 24, 2024



Large language models (LLMs) represent a transformative class of AI tools capable of revolutionizing various aspects of healthcare by generating human-like responses across diverse contexts and adapting to novel tasks following human instructions. Their potential application spans a broad range of medical tasks, such as clinical documentation, matching patients to clinical trials, and answering medical questions. In this primer paper, we propose an actionable guideline to help healthcare professionals more efficiently utilize LLMs in their work, along with a set of best practices. This approach consists of several main phases, including formulating the task, choosing LLMs, prompt engineering, fine-tuning, and deployment. We start with the discussion of critical considerations in identifying healthcare tasks that align with the core capabilities of LLMs and selecting models based on the selected task and data, performance requirements, and model interface. We then review the strategies, such as prompt engineering and fine-tuning, to adapt standard LLMs to specialized medical tasks. Deployment considerations, including regulatory compliance, ethical guidelines, and continuous monitoring for fairness and bias, are also discussed. By providing a structured step-by-step methodology, this tutorial aims to equip healthcare professionals with the tools necessary to effectively integrate LLMs into clinical practice, ensuring that these powerful technologies are applied in a safe, reliable, and impactful manner.
Closing the gap between open-source and commercial large language models for medical evidence summarization
Jul 25, 2024



Large language models (LLMs) hold great promise in summarizing medical evidence. Most recent studies focus on the application of proprietary LLMs. Using proprietary LLMs introduces multiple risk factors, including a lack of transparency and vendor dependency. While open-source LLMs allow better transparency and customization, their performance falls short compared to proprietary ones. In this study, we investigated to what extent fine-tuning open-source LLMs can further improve their performance in summarizing medical evidence. Utilizing a benchmark dataset, MedReview, consisting of 8,161 pairs of systematic reviews and summaries, we fine-tuned three broadly-used, open-sourced LLMs, namely PRIMERA, LongT5, and Llama-2. Overall, the fine-tuned LLMs obtained an increase of 9.89 in ROUGE-L (95% confidence interval: 8.94-10.81), 13.21 in METEOR score (95% confidence interval: 12.05-14.37), and 15.82 in CHRF score (95% confidence interval: 13.89-16.44). The performance of fine-tuned LongT5 is close to GPT-3.5 with zero-shot settings. Furthermore, smaller fine-tuned models sometimes even demonstrated superior performance compared to larger zero-shot models. The above trends of improvement were also manifested in both human and GPT4-simulated evaluations. Our results can be applied to guide model selection for tasks demanding particular domain knowledge, such as medical evidence summarization.
A Span-based Model for Extracting Overlapping PICO Entities from RCT Publications
Jan 08, 2024



Objectives Extraction of PICO (Populations, Interventions, Comparison, and Outcomes) entities is fundamental to evidence retrieval. We present a novel method PICOX to extract overlapping PICO entities. Materials and Methods PICOX first identifies entities by assessing whether a word marks the beginning or conclusion of an entity. Then it uses a multi-label classifier to assign one or more PICO labels to a span candidate. PICOX was evaluated using one of the best-performing baselines, EBM-NLP, and three more datasets, i.e., PICO-Corpus, and RCT publications on Alzheimer's Disease or COVID-19, using entity-level precision, recall, and F1 scores. Results PICOX achieved superior precision, recall, and F1 scores across the board, with the micro F1 score improving from 45.05 to 50.87 (p << 0.01). On the PICO-Corpus, PICOX obtained higher recall and F1 scores than the baseline and improved the micro recall score from 56.66 to 67.33. On the COVID-19 dataset, PICOX also outperformed the baseline and improved the micro F1 score from 77.10 to 80.32. On the AD dataset, PICOX demonstrated comparable F1 scores with higher precision when compared to the baseline. Conclusion PICOX excels in identifying overlapping entities and consistently surpasses a leading baseline across multiple datasets. Ablation studies reveal that its data augmentation strategy effectively minimizes false positives and improves precision.
Leveraging Generative AI for Clinical Evidence Summarization Needs to Achieve Trustworthiness
Nov 19, 2023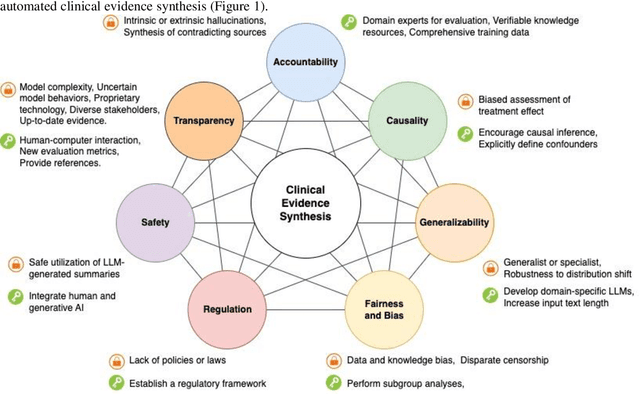
Evidence-based medicine aims to improve the quality of healthcare by empowering medical decisions and practices with the best available evidence. The rapid growth of medical evidence, which can be obtained from various sources, poses a challenge in collecting, appraising, and synthesizing the evidential information. Recent advancements in generative AI, exemplified by large language models, hold promise in facilitating the arduous task. However, developing accountable, fair, and inclusive models remains a complicated undertaking. In this perspective, we discuss the trustworthiness of generative AI in the context of automated summarization of medical evidence.
Efficient Learning for Selecting Top-m Context-Dependent Designs
May 06, 2023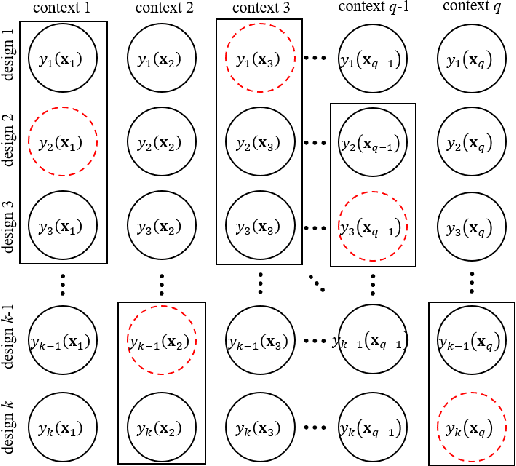
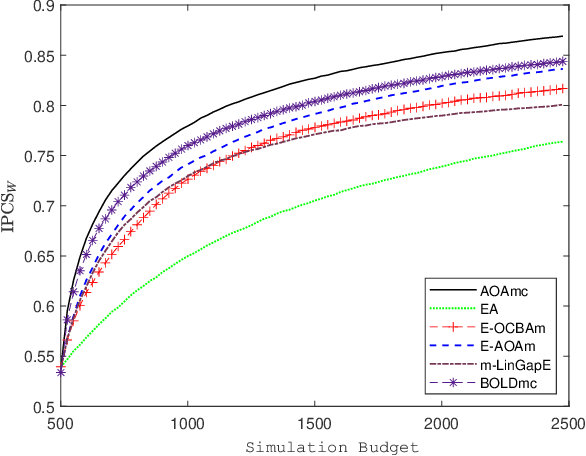
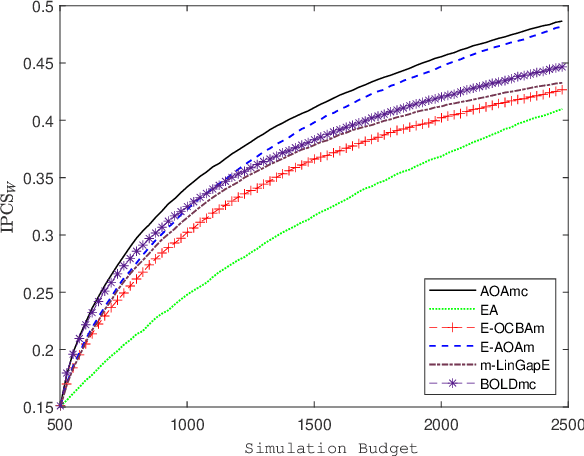

We consider a simulation optimization problem for a context-dependent decision-making, which aims to determine the top-m designs for all contexts. Under a Bayesian framework, we formulate the optimal dynamic sampling decision as a stochastic dynamic programming problem, and develop a sequential sampling policy to efficiently learn the performance of each design under each context. The asymptotically optimal sampling ratios are derived to attain the optimal large deviations rate of the worst-case of probability of false selection. The proposed sampling policy is proved to be consistent and its asymptotic sampling ratios are asymptotically optimal. Numerical experiments demonstrate that the proposed method improves the efficiency for selection of top-m context-dependent designs.