 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaDebate: Breaking Homogeneity in Multi-Agent Debate with Dynamic Path Generation
Jan 09, 2026Recent years have witnessed the rapid development of Large Language Model-based Multi-Agent Systems (MAS), which excel at collaborative decision-making and complex problem-solving. Recently, researchers have further investigated Multi-Agent Debate (MAD) frameworks, which enhance the reasoning and collaboration capabilities of MAS through information exchange and debate among multiple agents. However, existing approaches often rely on unguided initialization, causing agents to adopt identical reasoning paths that lead to the same errors. As a result, effective debate among agents is hindered, and the final outcome frequently degenerates into simple majority voting. To solve the above problem, in this paper, we introduce Dynamic Multi-Agent Debate (DynaDebate), which enhances the effectiveness of multi-agent debate through three key mechanisms: (1) Dynamic Path Generation and Allocation, which employs a dedicated Path Generation Agent to generate diverse and logical solution paths with adaptive redundancy; (2) Process-Centric Debate, which shifts the focus from surface-level outcome voting to rigorous step-by-step logic critique to ensure process correctness; (3) A Trigger-Based Verification Agent, which is activated upon disagreement and uses external tools to objectively resolve deadlocks. Extensive experiments demonstrate that DynaDebate achieves superior performance across various benchmarks, surpassing existing state-of-the-art MAD methods.
VIGIL: Defending LLM Agents Against Tool Stream Injection via Verify-Before-Commit
Jan 09, 2026LLM agents operating in open environments face escalating risks from indirect prompt injection, particularly within the tool stream where manipulated metadata and runtime feedback hijack execution flow. Existing defenses encounter a critical dilemma as advanced models prioritize injected rules due to strict alignment while static protection mechanisms sever the feedback loop required for adaptive reasoning. To reconcile this conflict, we propose \textbf{VIGIL}, a framework that shifts the paradigm from restrictive isolation to a verify-before-commit protocol. By facilitating speculative hypothesis generation and enforcing safety through intent-grounded verification, \textbf{VIGIL} preserves reasoning flexibility while ensuring robust control. We further introduce \textbf{SIREN}, a benchmark comprising 959 tool stream injection cases designed to simulate pervasive threats characterized by dynamic dependencies. Extensive experiments demonstrate that \textbf{VIGIL} outperforms state-of-the-art dynamic defenses by reducing the attack success rate by over 22\% while more than doubling the utility under attack compared to static baselines, thereby achieving an optimal balance between security and utility. Code is available at https://anonymous.4open.science/r/VIGIL-378B/.
Digital Twin AI: Opportunities and Challenges from Large Language Models to World Models
Jan 04, 2026Digital twins, as precise digital representations of physical systems, have evolved from passive simulation tools into intelligent and autonomous entities through the integration of artificial intelligence technologies. This paper presents a unified four-stage framework that systematically characterizes AI integration across the digital twin lifecycle, spanning modeling, mirroring, intervention, and autonomous management. By synthesizing existing technologies and practices, we distill a unified four-stage framework that systematically characterizes how AI methodologies are embedded across the digital twin lifecycle: (1) modeling the physical twin through physics-based and physics-informed AI approaches, (2) mirroring the physical system into a digital twin with real-time synchronization, (3) intervening in the physical twin through predictive modeling, anomaly detection, and optimization strategies, and (4) achieving autonomous management through large language models, foundation models, and intelligent agents. We analyze the synergy between physics-based modeling and data-driven learning, highlighting the shift from traditional numerical solvers to physics-informed and foundation models for physical systems. Furthermore, we examine how generative AI technologies, including large language models and generative world models, transform digital twins into proactive and self-improving cognitive systems capable of reasoning, communication, and creative scenario generation. Through a cross-domain review spanning eleven application domains, including healthcare, aerospace, smart manufacturing, robotics, and smart cities, we identify common challenges related to scalability, explainability, and trustworthiness, and outline directions for responsible AI-driven digital twin systems.
Codebook-Centric Deep Hashing: End-to-End Joint Learning of Semantic Hash Centers and Neural Hash Function
Nov 15, 2025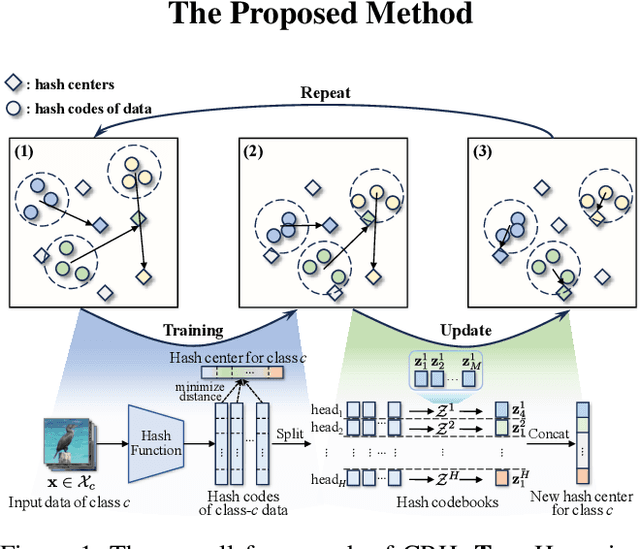
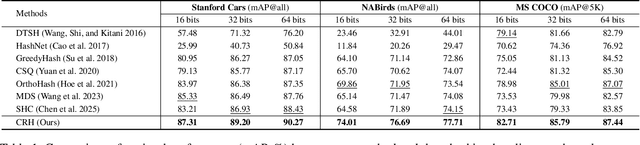

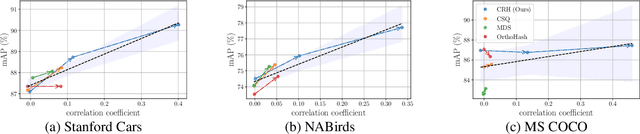
Hash center-based deep hashing methods improve upon pairwise or triplet-based approaches by assigning fixed hash centers to each class as learning targets, thereby avoiding the inefficiency of local similarity optimization. However, random center initialization often disregards inter-class semantic relationships. While existing two-stage methods mitigate this by first refining hash centers with semantics and then training the hash function, they introduce additional complexity, computational overhead, and suboptimal performance due to stage-wise discrepancies. To address these limitations, we propose $\textbf{Center-Reassigned Hashing (CRH)}$, an end-to-end framework that $\textbf{dynamically reassigns hash centers}$ from a preset codebook while jointly optimizing the hash function. Unlike previous methods, CRH adapts hash centers to the data distribution $\textbf{without explicit center optimization phases}$, enabling seamless integration of semantic relationships into the learning process. Furthermore, $\textbf{a multi-head mechanism}$ enhances the representational capacity of hash centers, capturing richer semantic structures. Extensive experiments on three benchmarks demonstrate that CRH learns semantically meaningful hash centers and outperforms state-of-the-art deep hashing methods in retrieval tasks.
FAME: Adaptive Functional Attention with Expert Routing for Function-on-Function Regression
Oct 01, 2025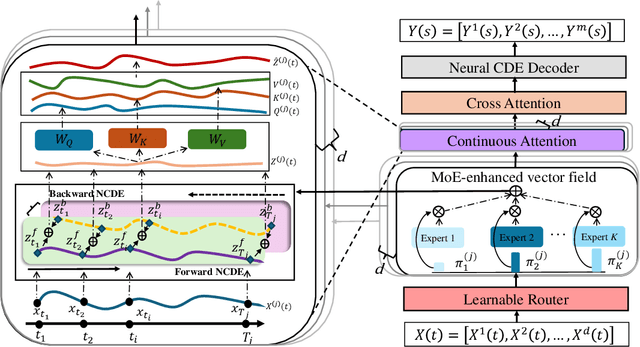
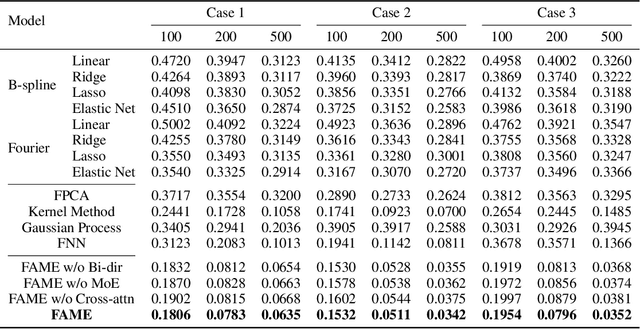
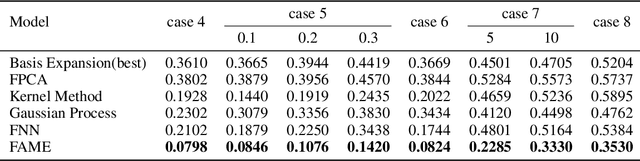
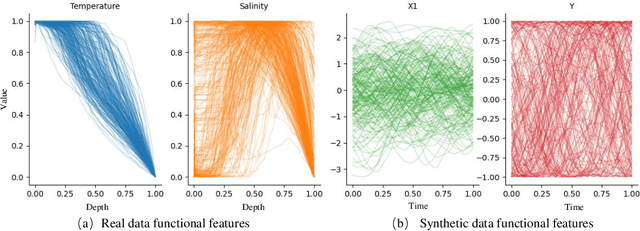
Functional data play a pivotal role across science and engineering, yet their infinite-dimensional nature makes representation learning challenging. Conventional statistical models depend on pre-chosen basis expansions or kernels, limiting the flexibility of data-driven discovery, while many deep-learning pipelines treat functions as fixed-grid vectors, ignoring inherent continuity. In this paper, we introduce Functional Attention with a Mixture-of-Experts (FAME), an end-to-end, fully data-driven framework for function-on-function regression. FAME forms continuous attention by coupling a bidirectional neural controlled differential equation with MoE-driven vector fields to capture intra-functional continuity, and further fuses change to inter-functional dependencies via multi-head cross attention. Extensive experiments on synthetic and real-world functional-regression benchmarks show that FAME achieves state-of-the-art accuracy, strong robustness to arbitrarily sampled discrete observations of functions.
Empowering Clinical Trial Design through AI: A Randomized Evaluation of PowerGPT
Sep 15, 2025



Sample size calculations for power analysis are critical for clinical research and trial design, yet their complexity and reliance on statistical expertise create barriers for many researchers. We introduce PowerGPT, an AI-powered system integrating large language models (LLMs) with statistical engines to automate test selection and sample size estimation in trial design. In a randomized trial to evaluate its effectiveness, PowerGPT significantly improved task completion rates (99.3% vs. 88.9% for test selection, 99.3% vs. 77.8% for sample size calculation) and accuracy (94.1% vs. 55.4% in sample size estimation, p < 0.001), while reducing average completion time (4.0 vs. 9.3 minutes, p < 0.001). These gains were consistent across various statistical tests and benefited both statisticians and non-statisticians as well as bridging expertise gaps. Already under deployment across multiple institutions, PowerGPT represents a scalable AI-driven approach that enhances accessibility, efficiency, and accuracy in statistical power analysis for clinical research.
Dream to Chat: Model-based Reinforcement Learning on Dialogues with User Belief Modeling
Aug 23, 2025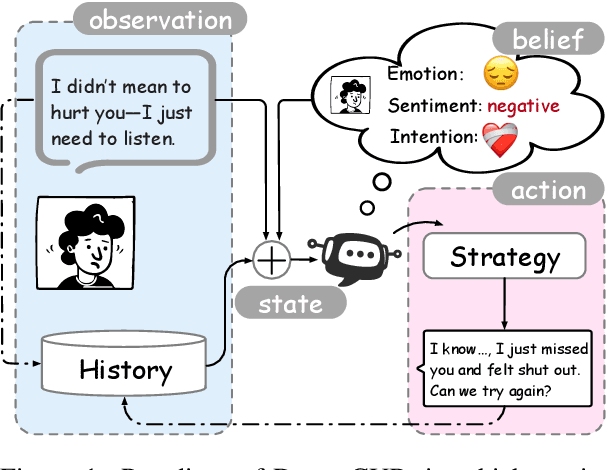
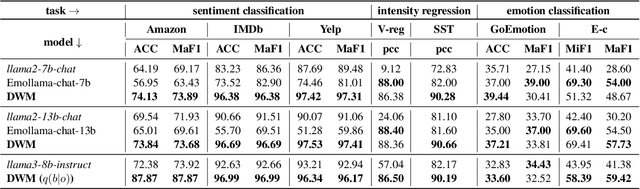
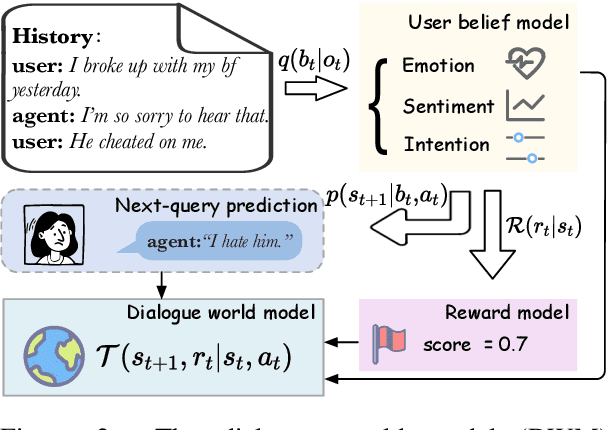
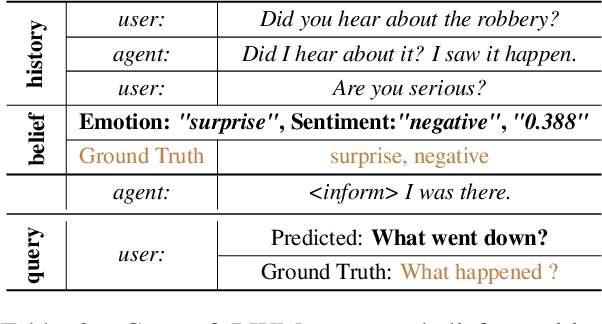
World models have been widely utilized in robotics, gaming, and auto-driving. However, their applications on natural language tasks are relatively limited. In this paper, we construct the dialogue world model, which could predict the user's emotion, sentiment, and intention, and future utterances. By defining a POMDP, we argue emotion, sentiment and intention can be modeled as the user belief and solved by maximizing the information bottleneck. By this user belief modeling, we apply the model-based reinforcement learning framework to the dialogue system, and propose a framework called DreamCUB. Experiments show that the pretrained dialogue world model can achieve state-of-the-art performances on emotion classification and sentiment identification, while dialogue quality is also enhanced by joint training of the policy, critic and dialogue world model. Further analysis shows that this manner holds a reasonable exploration-exploitation balance and also transfers well to out-of-domain scenarios such as empathetic dialogues.
DiffOSeg: Omni Medical Image Segmentation via Multi-Expert Collaboration Diffusion Model
Jul 17, 2025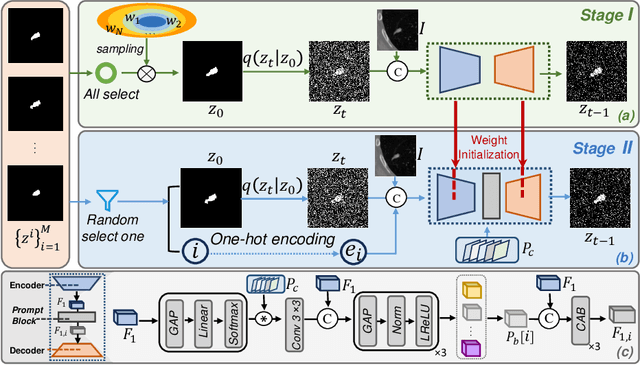
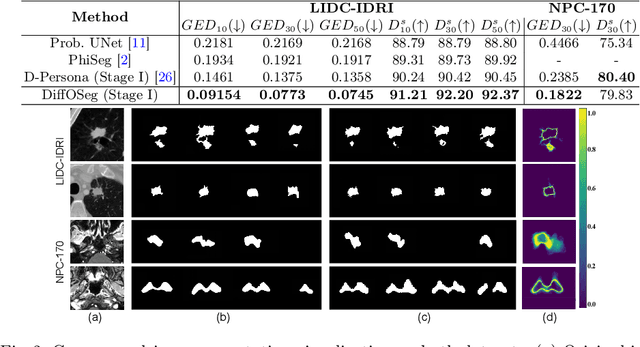
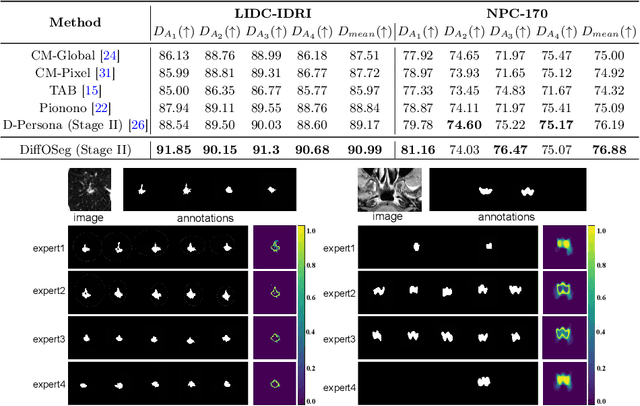

Annotation variability remains a substantial challenge in medical image segmentation, stemming from ambiguous imaging boundaries and diverse clinical expertise. Traditional deep learning methods producing single deterministic segmentation predictions often fail to capture these annotator biases. Although recent studies have explored multi-rater segmentation, existing methods typically focus on a single perspective -- either generating a probabilistic ``gold standard'' consensus or preserving expert-specific preferences -- thus struggling to provide a more omni view. In this study, we propose DiffOSeg, a two-stage diffusion-based framework, which aims to simultaneously achieve both consensus-driven (combining all experts' opinions) and preference-driven (reflecting experts' individual assessments) segmentation. Stage I establishes population consensus through a probabilistic consensus strategy, while Stage II captures expert-specific preference via adaptive prompts. Demonstrated on two public datasets (LIDC-IDRI and NPC-170), our model outperforms existing state-of-the-art methods across all evaluated metrics. Source code is available at https://github.com/string-ellipses/DiffOSeg .
SAFER: A Calibrated Risk-Aware Multimodal Recommendation Model for Dynamic Treatment Regimes
Jun 07, 2025



Dynamic treatment regimes (DTRs) are critical to precision medicine, optimizing long-term outcomes through personalized, real-time decision-making in evolving clinical contexts, but require careful supervision for unsafe treatment risks. Existing efforts rely primarily on clinician-prescribed gold standards despite the absence of a known optimal strategy, and predominantly using structured EHR data without extracting valuable insights from clinical notes, limiting their reliability for treatment recommendations. In this work, we introduce SAFER, a calibrated risk-aware tabular-language recommendation framework for DTR that integrates both structured EHR and clinical notes, enabling them to learn from each other, and addresses inherent label uncertainty by assuming ambiguous optimal treatment solution for deceased patients. Moreover, SAFER employs conformal prediction to provide statistical guarantees, ensuring safe treatment recommendations while filtering out uncertain predictions. Experiments on two publicly available sepsis datasets demonstrate that SAFER outperforms state-of-the-art baselines across multiple recommendation metrics and counterfactual mortality rate, while offering robust formal assurances. These findings underscore SAFER potential as a trustworthy and theoretically grounded solution for high-stakes DTR applications.
FreeTimeGS: Free Gaussian Primitives at Anytime and Anywhere for Dynamic Scene Reconstruction
Jun 06, 2025



This paper addresses the challenge of reconstructing dynamic 3D scenes with complex motions. Some recent works define 3D Gaussian primitives in the canonical space and use deformation fields to map canonical primitives to observation spaces, achieving real-time dynamic view synthesis. However, these methods often struggle to handle scenes with complex motions due to the difficulty of optimizing deformation fields. To overcome this problem, we propose FreeTimeGS, a novel 4D representation that allows Gaussian primitives to appear at arbitrary time and locations. In contrast to canonical Gaussian primitives, our representation possesses the strong flexibility, thus improving the ability to model dynamic 3D scenes. In addition, we endow each Gaussian primitive with an motion function, allowing it to move to neighboring regions over time, which reduces the temporal redundancy. Experiments results on several datasets show that the rendering quality of our method outperforms recent methods by a large margin. Project page: https://zju3dv.github.io/freetimegs/ .