 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoices of Civilizations: A Multilingual QA Benchmark for Global Music Understanding
Feb 28, 2026We introduce Voices of Civilizations, the first multilingual QA benchmark for evaluating audio LLMs' cultural comprehension on full-length music recordings. Covering 380 tracks across 38 languages, our automated pipeline yields 1,190 multiple-choice questions through four stages - each followed by manual verification: 1) compiling a representative music list; 2) generating cultural-background documents for each sample in the music list via LLMs; 3) extracting key attributes from those documents; and 4) constructing multiple-choice questions probing language, region associations, mood, and thematic content. We evaluate models under four conditions and report per-language accuracy. Our findings demonstrate that even state-of-the-art audio LLMs struggle to capture subtle cultural nuances without rich textual context and exhibit systematic biases in interpreting music from different cultural traditions. The dataset is publicly available on Hugging Face to foster culturally inclusive music understanding research.
Summary of The Inaugural Music Source Restoration Challenge
Jan 07, 2026Music Source Restoration (MSR) aims to recover original, unprocessed instrument stems from professionally mixed and degraded audio, requiring the reversal of both production effects and real-world degradations. We present the inaugural MSR Challenge, which features objective evaluation on studio-produced mixtures using Multi-Mel-SNR, Zimtohrli, and FAD-CLAP, alongside subjective evaluation on real-world degraded recordings. Five teams participated in the challenge. The winning system achieved 4.46 dB Multi-Mel-SNR and 3.47 MOS-Overall, corresponding to relative improvements of 91% and 18% over the second-place system, respectively. Per-stem analysis reveals substantial variation in restoration difficulty across instruments, with bass averaging 4.59 dB across all teams, while percussion averages only 0.29 dB. The dataset, evaluation protocols, and baselines are available at https://msrchallenge.com/.
PromptReverb: Multimodal Room Impulse Response Generation Through Latent Rectified Flow Matching
Oct 25, 2025Room impulse response (RIR) generation remains a critical challenge for creating immersive virtual acoustic environments. Current methods suffer from two fundamental limitations: the scarcity of full-band RIR datasets and the inability of existing models to generate acoustically accurate responses from diverse input modalities. We present PromptReverb, a two-stage generative framework that addresses these challenges. Our approach combines a variational autoencoder that upsamples band-limited RIRs to full-band quality (48 kHz), and a conditional diffusion transformer model based on rectified flow matching that generates RIRs from descriptions in natural language. Empirical evaluation demonstrates that PromptReverb produces RIRs with superior perceptual quality and acoustic accuracy compared to existing methods, achieving 8.8% mean RT60 error compared to -37% for widely used baselines and yielding more realistic room-acoustic parameters. Our method enables practical applications in virtual reality, architectural acoustics, and audio production where flexible, high-quality RIR synthesis is essential.
Music Source Restoration
May 27, 2025We introduce Music Source Restoration (MSR), a novel task addressing the gap between idealized source separation and real-world music production. Current Music Source Separation (MSS) approaches assume mixtures are simple sums of sources, ignoring signal degradations employed during music production like equalization, compression, and reverb. MSR models mixtures as degraded sums of individually degraded sources, with the goal of recovering original, undegraded signals. Due to the lack of data for MSR, we present RawStems, a dataset annotation of 578 songs with unprocessed source signals organized into 8 primary and 17 secondary instrument groups, totaling 354.13 hours. To the best of our knowledge, RawStems is the first dataset that contains unprocessed music stems with hierarchical categories. We consider spectral filtering, dynamic range compression, harmonic distortion, reverb and lossy codec as possible degradations, and establish U-Former as a baseline method, demonstrating the feasibility of MSR on our dataset. We release the RawStems dataset annotations, degradation simulation pipeline, training code and pre-trained models to be publicly available.
Training-Free Multi-Step Audio Source Separation
May 26, 2025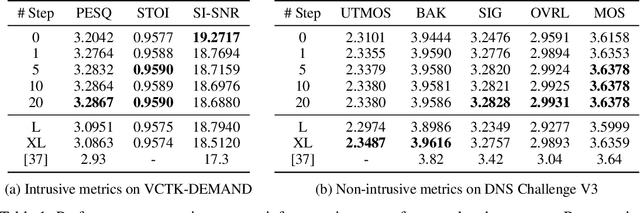
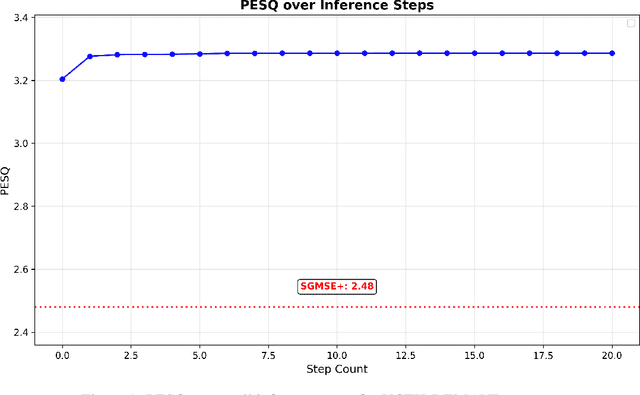
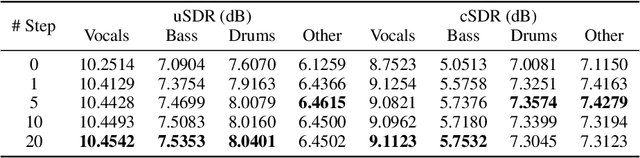
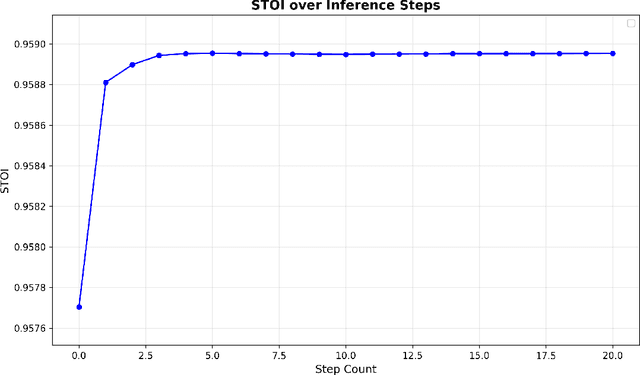
Audio source separation aims to separate a mixture into target sources. Previous audio source separation systems usually conduct one-step inference, which does not fully explore the separation ability of models. In this work, we reveal that pretrained one-step audio source separation models can be leveraged for multi-step separation without additional training. We propose a simple yet effective inference method that iteratively applies separation by optimally blending the input mixture with the previous step's separation result. At each step, we determine the optimal blending ratio by maximizing a metric. We prove that our method always yield improvement over one-step inference, provide error bounds based on model smoothness and metric robustness, and provide theoretical analysis connecting our method to denoising along linear interpolation paths between noise and clean distributions, a property we link to denoising diffusion bridge models. Our approach effectively delivers improved separation performance as a "free lunch" from existing models. Our empirical results demonstrate that our multi-step separation approach consistently outperforms one-step inference across both speech enhancement and music source separation tasks, and can achieve scaling performance similar to training a larger model, using more data, or in some cases employing a multi-step training objective. These improvements appear not only on the optimization metric during multi-step inference, but also extend to nearly all non-optimized metrics (with one exception). We also discuss limitations of our approach and directions for future research.
YuE: Scaling Open Foundation Models for Long-Form Music Generation
Mar 11, 2025We tackle the task of long-form music generation--particularly the challenging \textbf{lyrics-to-song} problem--by introducing YuE, a family of open foundation models based on the LLaMA2 architecture. Specifically, YuE scales to trillions of tokens and generates up to five minutes of music while maintaining lyrical alignment, coherent musical structure, and engaging vocal melodies with appropriate accompaniment. It achieves this through (1) track-decoupled next-token prediction to overcome dense mixture signals, (2) structural progressive conditioning for long-context lyrical alignment, and (3) a multitask, multiphase pre-training recipe to converge and generalize. In addition, we redesign the in-context learning technique for music generation, enabling versatile style transfer (e.g., converting Japanese city pop into an English rap while preserving the original accompaniment) and bidirectional generation. Through extensive evaluation, we demonstrate that YuE matches or even surpasses some of the proprietary systems in musicality and vocal agility. In addition, fine-tuning YuE enables additional controls and enhanced support for tail languages. Furthermore, beyond generation, we show that YuE's learned representations can perform well on music understanding tasks, where the results of YuE match or exceed state-of-the-art methods on the MARBLE benchmark. Keywords: lyrics2song, song generation, long-form, foundation model, music generation
ASVspoof 5: Design, Collection and Validation of Resources for Spoofing, Deepfake, and Adversarial Attack Detection Using Crowdsourced Speech
Feb 13, 2025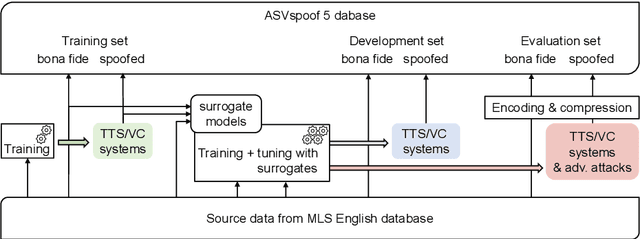

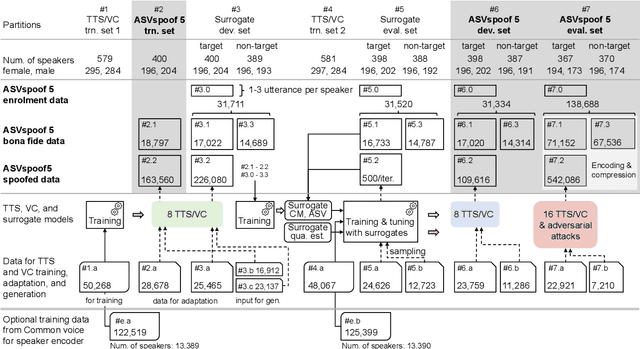
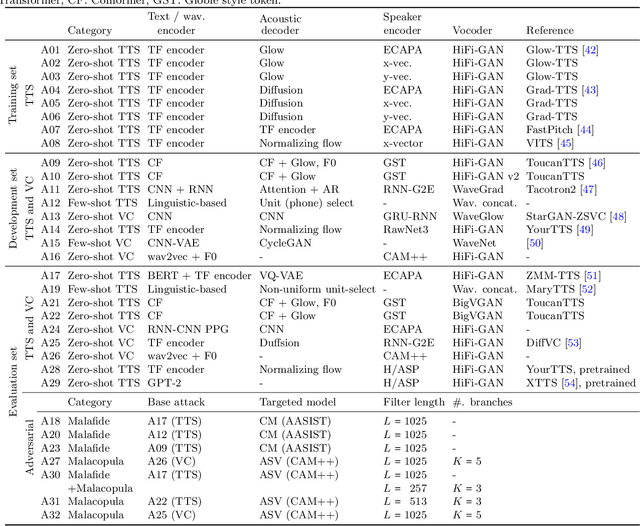
ASVspoof 5 is the fifth edition in a series of challenges which promote the study of speech spoofing and deepfake attacks as well as the design of detection solutions. We introduce the ASVspoof 5 database which is generated in crowdsourced fashion from data collected in diverse acoustic conditions (cf. studio-quality data for earlier ASVspoof databases) and from ~2,000 speakers (cf. ~100 earlier). The database contains attacks generated with 32 different algorithms, also crowdsourced, and optimised to varying degrees using new surrogate detection models. Among them are attacks generated with a mix of legacy and contemporary text-to-speech synthesis and voice conversion models, in addition to adversarial attacks which are incorporated for the first time. ASVspoof 5 protocols comprise seven speaker-disjoint partitions. They include two distinct partitions for the training of different sets of attack models, two more for the development and evaluation of surrogate detection models, and then three additional partitions which comprise the ASVspoof 5 training, development and evaluation sets. An auxiliary set of data collected from an additional 30k speakers can also be used to train speaker encoders for the implementation of attack algorithms. Also described herein is an experimental validation of the new ASVspoof 5 database using a set of automatic speaker verification and spoof/deepfake baseline detectors. With the exception of protocols and tools for the generation of spoofed/deepfake speech, the resources described in this paper, already used by participants of the ASVspoof 5 challenge in 2024, are now all freely available to the community.
Piano Transcription by Hierarchical Language Modeling with Pretrained Roll-based Encoders
Jan 07, 2025



Automatic Music Transcription (AMT), aiming to get musical notes from raw audio, typically uses frame-level systems with piano-roll outputs or language model (LM)-based systems with note-level predictions. However, frame-level systems require manual thresholding, while the LM-based systems struggle with long sequences. In this paper, we propose a hybrid method combining pre-trained roll-based encoders with an LM decoder to leverage the strengths of both methods. Besides, our approach employs a hierarchical prediction strategy, first predicting onset and pitch, then velocity, and finally offset. The hierarchical prediction strategy reduces computational costs by breaking down long sequences into different hierarchies. Evaluated on two benchmark roll-based encoders, our method outperforms traditional piano-roll outputs 0.01 and 0.022 in onset-offset-velocity F1 score, demonstrating its potential as a performance-enhancing plug-in for arbitrary roll-based music transcription encoder.
SVDD 2024: The Inaugural Singing Voice Deepfake Detection Challenge
Aug 28, 2024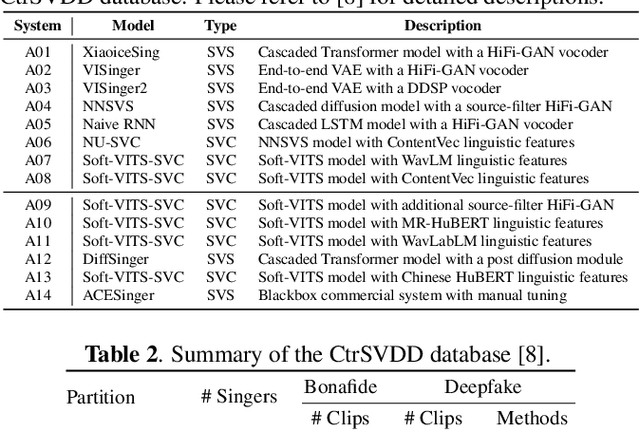
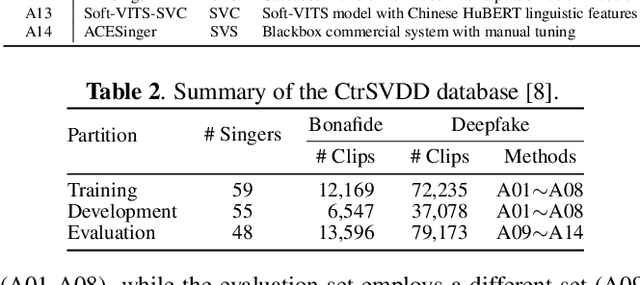
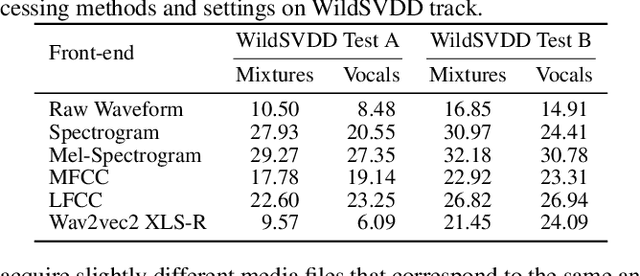
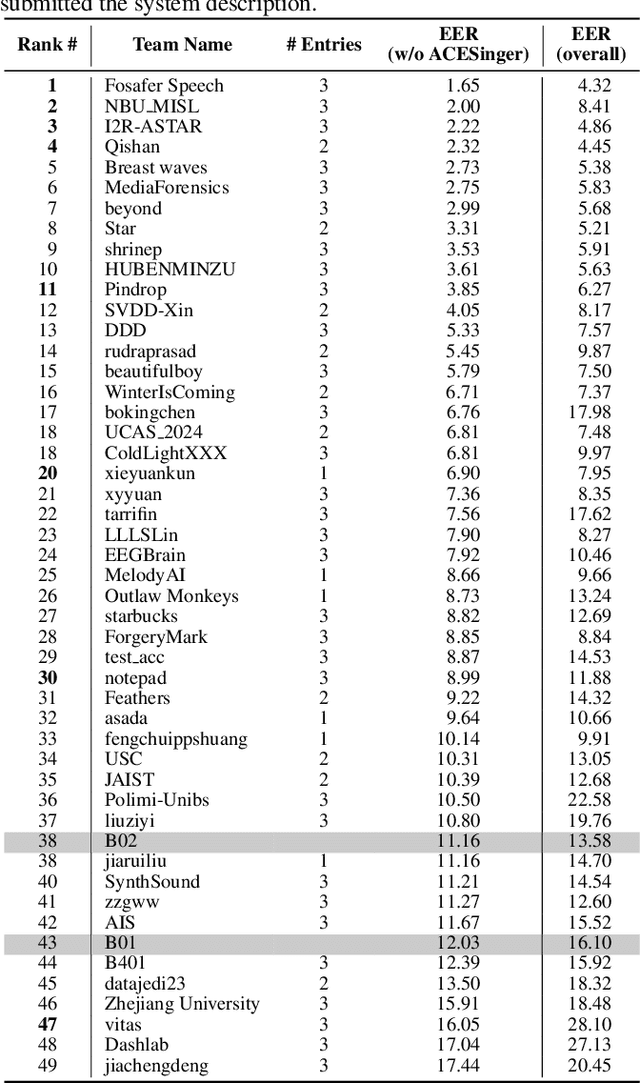
With the advancements in singing voice generation and the growing presence of AI singers on media platforms, the inaugural Singing Voice Deepfake Detection (SVDD) Challenge aims to advance research in identifying AI-generated singing voices from authentic singers. This challenge features two tracks: a controlled setting track (CtrSVDD) and an in-the-wild scenario track (WildSVDD). The CtrSVDD track utilizes publicly available singing vocal data to generate deepfakes using state-of-the-art singing voice synthesis and conversion systems. Meanwhile, the WildSVDD track expands upon the existing SingFake dataset, which includes data sourced from popular user-generated content websites. For the CtrSVDD track, we received submissions from 47 teams, with 37 surpassing our baselines and the top team achieving a 1.65% equal error rate. For the WildSVDD track, we benchmarked the baselines. This paper reviews these results, discusses key findings, and outlines future directions for SVDD research.
The Interpretation Gap in Text-to-Music Generation Models
Jul 14, 2024



Large-scale text-to-music generation models have significantly enhanced music creation capabilities, offering unprecedented creative freedom. However, their ability to collaborate effectively with human musicians remains limited. In this paper, we propose a framework to describe the musical interaction process, which includes expression, interpretation, and execution of controls. Following this framework, we argue that the primary gap between existing text-to-music models and musicians lies in the interpretation stage, where models lack the ability to interpret controls from musicians. We also propose two strategies to address this gap and call on the music information retrieval community to tackle the interpretation challenge to improve human-AI musical collaboration.