 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyclostationarity Analysis as a Complement to Self-Supervised Representations for Speech Deepfake Detection
Mar 04, 2026Speech deepfake detection (SDD) is essential for maintaining trust in voice-driven technologies and digital media. Although recent SDD systems increasingly rely on self-supervised learning (SSL) representations that capture rich contextual information, complementary signal-driven acoustic features remain important for modeling fine-grained structural properties of speech. Most existing acoustic front ends are based on time-frequency representations, which do not fully exploit higher-order spectral dependencies inherent in speech signals. We introduce a cyclostationarity-inspired acoustic feature extraction framework for SDD based on spectral correlation density (SCD). The proposed features model periodic statistical structures in speech by capturing spectral correlations between frequency components. In particular, we propose temporally structured SCD features that characterize the evolution of spectral and cyclic-frequency components over time. The effectiveness and complementarity of the proposed features are evaluated using multiple countermeasure architectures, including convolutional neural networks, SSL-based embedding systems, and hybrid fusion models. Experiments on ASVspoof 2019 LA, ASVspoof 2021 DF, and ASVspoof 5 demonstrate that SCD-based features provide complementary discriminative information to SSL embeddings and conventional acoustic representations. In particular, fusion of SSL and SCD embeddings reduces the equal error rate on ASVspoof 2019 LA from $8.28\%$ to $0.98\%$, and yields consistent improvements on the challenging ASVspoof 5 dataset. The results highlight cyclostationary signal analysis as a theoretically grounded and effective front end for speech deepfake detection.
Joint Optimization of ASV and CM tasks: BTUEF Team's Submission for WildSpoof Challenge
Feb 02, 2026Spoofing-aware speaker verification (SASV) jointly addresses automatic speaker verification and spoofing countermeasures to improve robustness against adversarial attacks. In this paper, we investigate our recently proposed modular SASV framework that enables effective reuse of publicly available ASV and CM systems through non-linear fusion, explicitly modeling their interaction, and optimization with an operating-condition-dependent trainable a-DCF loss. The framework is evaluated using ECAPA-TDNN and ReDimNet as ASV embedding extractors and SSL-AASIST as the CM model, with experiments conducted both with and without fine-tuning on the WildSpoof SASV training data. Results show that the best performance is achieved by combining ReDimNet-based ASV embeddings with fine-tuned SSL-AASIST representations, yielding an a-DCF of 0.0515 on the progress evaluation set and 0.2163 on the final evaluation set.
ASVspoof 5: Evaluation of Spoofing, Deepfake, and Adversarial Attack Detection Using Crowdsourced Speech
Jan 07, 2026ASVspoof 5 is the fifth edition in a series of challenges which promote the study of speech spoofing and deepfake detection solutions. A significant change from previous challenge editions is a new crowdsourced database collected from a substantially greater number of speakers under diverse recording conditions, and a mix of cutting-edge and legacy generative speech technology. With the new database described elsewhere, we provide in this paper an overview of the ASVspoof 5 challenge results for the submissions of 53 participating teams. While many solutions perform well, performance degrades under adversarial attacks and the application of neural encoding/compression schemes. Together with a review of post-challenge results, we also report a study of calibration in addition to other principal challenges and outline a road-map for the future of ASVspoof.
Investigating the Potential of Multi-Stage Score Fusion in Spoofing-Aware Speaker Verification
Sep 16, 2025Despite improvements in automatic speaker verification (ASV), vulnerability against spoofing attacks remains a major concern. In this study, we investigate the integration of ASV and countermeasure (CM) subsystems into a modular spoof-aware speaker verification (SASV) framework. Unlike conventional single-stage score-level fusion methods, we explore the potential of a multi-stage approach that utilizes the ASV and CM systems in multiple stages. By leveraging ECAPA-TDNN (ASV) and AASIST (CM) subsystems, we consider support vector machine and logistic regression classifiers to achieve SASV. In the second stage, we integrate their outputs with the original score to revise fusion back-end classifiers. Additionally, we incorporate another auxiliary score from RawGAT (CM) to further enhance our SASV framework. Our approach yields an equal error rate (EER) of 1.30% on the evaluation dataset of the SASV2022 challenge, representing a 24% relative improvement over the baseline system.
Multilingual Source Tracing of Speech Deepfakes: A First Benchmark
Aug 06, 2025Recent progress in generative AI has made it increasingly easy to create natural-sounding deepfake speech from just a few seconds of audio. While these tools support helpful applications, they also raise serious concerns by making it possible to generate convincing fake speech in many languages. Current research has largely focused on detecting fake speech, but little attention has been given to tracing the source models used to generate it. This paper introduces the first benchmark for multilingual speech deepfake source tracing, covering both mono- and cross-lingual scenarios. We comparatively investigate DSP- and SSL-based modeling; examine how SSL representations fine-tuned on different languages impact cross-lingual generalization performance; and evaluate generalization to unseen languages and speakers. Our findings offer the first comprehensive insights into the challenges of identifying speech generation models when training and inference languages differ. The dataset, protocol and code are available at https://github.com/xuanxixi/Multilingual-Source-Tracing.
FROST-EMA: Finnish and Russian Oral Speech Dataset of Electromagnetic Articulography Measurements with L1, L2 and Imitated L2 Accents
Jun 10, 2025We introduce a new FROST-EMA (Finnish and Russian Oral Speech Dataset of Electromagnetic Articulography) corpus. It consists of 18 bilingual speakers, who produced speech in their native language (L1), second language (L2), and imitated L2 (fake foreign accent). The new corpus enables research into language variability from phonetic and technological points of view. Accordingly, we include two preliminary case studies to demonstrate both perspectives. The first case study explores the impact of L2 and imitated L2 on the performance of an automatic speaker verification system, while the second illustrates the articulatory patterns of one speaker in L1, L2, and a fake accent.
Continuous Learning for Children's ASR: Overcoming Catastrophic Forgetting with Elastic Weight Consolidation and Synaptic Intelligence
May 26, 2025In this work, we present the first study addressing automatic speech recognition (ASR) for children in an online learning setting. This is particularly important for both child-centric applications and the privacy protection of minors, where training models with sequentially arriving data is critical. The conventional approach of model fine-tuning often suffers from catastrophic forgetting. To tackle this issue, we explore two established techniques: elastic weight consolidation (EWC) and synaptic intelligence (SI). Using a custom protocol on the MyST corpus, tailored to the online learning setting, we achieve relative word error rate (WER) reductions of 5.21% with EWC and 4.36% with SI, compared to the fine-tuning baseline.
STOPA: A Database of Systematic VariaTion Of DeePfake Audio for Open-Set Source Tracing and Attribution
May 26, 2025A key research area in deepfake speech detection is source tracing - determining the origin of synthesised utterances. The approaches may involve identifying the acoustic model (AM), vocoder model (VM), or other generation-specific parameters. However, progress is limited by the lack of a dedicated, systematically curated dataset. To address this, we introduce STOPA, a systematically varied and metadata-rich dataset for deepfake speech source tracing, covering 8 AMs, 6 VMs, and diverse parameter settings across 700k samples from 13 distinct synthesisers. Unlike existing datasets, which often feature limited variation or sparse metadata, STOPA provides a systematically controlled framework covering a broader range of generative factors, such as the choice of the vocoder model, acoustic model, or pretrained weights, ensuring higher attribution reliability. This control improves attribution accuracy, aiding forensic analysis, deepfake detection, and generative model transparency.
ASVspoof 5: Design, Collection and Validation of Resources for Spoofing, Deepfake, and Adversarial Attack Detection Using Crowdsourced Speech
Feb 13, 2025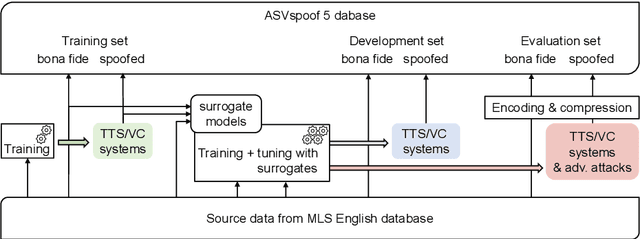

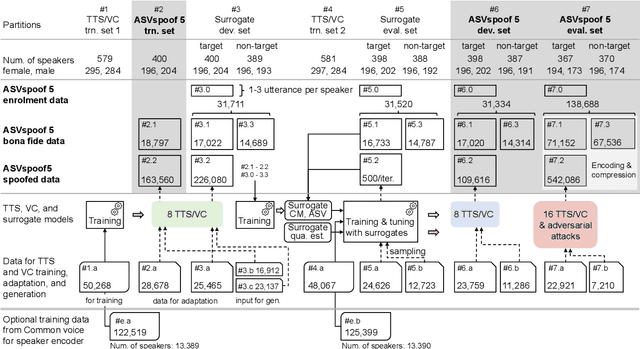
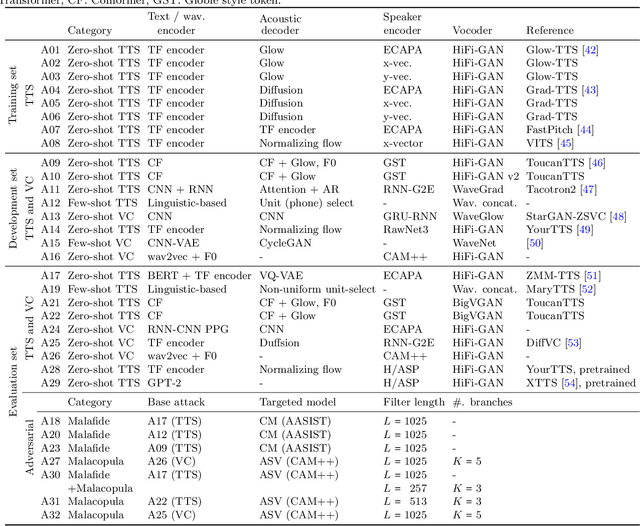
ASVspoof 5 is the fifth edition in a series of challenges which promote the study of speech spoofing and deepfake attacks as well as the design of detection solutions. We introduce the ASVspoof 5 database which is generated in crowdsourced fashion from data collected in diverse acoustic conditions (cf. studio-quality data for earlier ASVspoof databases) and from ~2,000 speakers (cf. ~100 earlier). The database contains attacks generated with 32 different algorithms, also crowdsourced, and optimised to varying degrees using new surrogate detection models. Among them are attacks generated with a mix of legacy and contemporary text-to-speech synthesis and voice conversion models, in addition to adversarial attacks which are incorporated for the first time. ASVspoof 5 protocols comprise seven speaker-disjoint partitions. They include two distinct partitions for the training of different sets of attack models, two more for the development and evaluation of surrogate detection models, and then three additional partitions which comprise the ASVspoof 5 training, development and evaluation sets. An auxiliary set of data collected from an additional 30k speakers can also be used to train speaker encoders for the implementation of attack algorithms. Also described herein is an experimental validation of the new ASVspoof 5 database using a set of automatic speaker verification and spoof/deepfake baseline detectors. With the exception of protocols and tools for the generation of spoofed/deepfake speech, the resources described in this paper, already used by participants of the ASVspoof 5 challenge in 2024, are now all freely available to the community.
Causal Analysis of ASR Errors for Children: Quantifying the Impact of Physiological, Cognitive, and Extrinsic Factors
Feb 12, 2025The increasing use of children's automatic speech recognition (ASR) systems has spurred research efforts to improve the accuracy of models designed for children's speech in recent years. The current approach utilizes either open-source speech foundation models (SFMs) directly or fine-tuning them with children's speech data. These SFMs, whether open-source or fine-tuned for children, often exhibit higher word error rates (WERs) compared to adult speech. However, there is a lack of systemic analysis of the cause of this degraded performance of SFMs. Understanding and addressing the reasons behind this performance disparity is crucial for improving the accuracy of SFMs for children's speech. Our study addresses this gap by investigating the causes of accuracy degradation and the primary contributors to WER in children's speech. In the first part of the study, we conduct a comprehensive benchmarking study on two self-supervised SFMs (Wav2Vec2.0 and Hubert) and two weakly supervised SFMs (Whisper and MMS) across various age groups on two children speech corpora, establishing the raw data for the causal inference analysis in the second part. In the second part of the study, we analyze the impact of physiological factors (age, gender), cognitive factors (pronunciation ability), and external factors (vocabulary difficulty, background noise, and word count) on SFM accuracy in children's speech using causal inference. The results indicate that physiology (age) and particular external factor (number of words in audio) have the highest impact on accuracy, followed by background noise and pronunciation ability. Fine-tuning SFMs on children's speech reduces sensitivity to physiological and cognitive factors, while sensitivity to the number of words in audio persists. Keywords: Children's ASR, Speech Foundational Models, Causal Inference, Physiology, Cognition, Pronunciation