 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Multi-Objective Fusion of Deepfake Speech Detectors
Apr 01, 2026While deepfake speech detectors built on large self-supervised learning (SSL) models achieve high accuracy, employing standard ensemble fusion to further enhance robustness often results in oversized systems with diminishing returns. To address this, we propose an evolutionary multi-objective score fusion framework that jointly minimizes detection error and system complexity. We explore two encodings optimized by NSGA-II: binary-coded detector selection for score averaging and a real-valued scheme that optimizes detector weights for a weighted sum. Experiments on the ASVspoof 5 dataset with 36 SSL-based detectors show that the obtained Pareto fronts outperform simple averaging and logistic regression baselines. The real-valued variant achieves 2.37% EER (0.0684 minDCF) and identifies configurations that match state-of-the-art performance while significantly reducing system complexity, requiring only half the parameters. Our method also provides a diverse set of trade-off solutions, enabling deployment choices that balance accuracy and computational cost.
SCDF: A Speaker Characteristics DeepFake Speech Dataset for Bias Analysis
Aug 11, 2025Despite growing attention to deepfake speech detection, the aspects of bias and fairness remain underexplored in the speech domain. To address this gap, we introduce the Speaker Characteristics Deepfake (SCDF) dataset: a novel, richly annotated resource enabling systematic evaluation of demographic biases in deepfake speech detection. SCDF contains over 237,000 utterances in a balanced representation of both male and female speakers spanning five languages and a wide age range. We evaluate several state-of-the-art detectors and show that speaker characteristics significantly influence detection performance, revealing disparities across sex, language, age, and synthesizer type. These findings highlight the need for bias-aware development and provide a foundation for building non-discriminatory deepfake detection systems aligned with ethical and regulatory standards.
STOPA: A Database of Systematic VariaTion Of DeePfake Audio for Open-Set Source Tracing and Attribution
May 26, 2025A key research area in deepfake speech detection is source tracing - determining the origin of synthesised utterances. The approaches may involve identifying the acoustic model (AM), vocoder model (VM), or other generation-specific parameters. However, progress is limited by the lack of a dedicated, systematically curated dataset. To address this, we introduce STOPA, a systematically varied and metadata-rich dataset for deepfake speech source tracing, covering 8 AMs, 6 VMs, and diverse parameter settings across 700k samples from 13 distinct synthesisers. Unlike existing datasets, which often feature limited variation or sparse metadata, STOPA provides a systematically controlled framework covering a broader range of generative factors, such as the choice of the vocoder model, acoustic model, or pretrained weights, ensuring higher attribution reliability. This control improves attribution accuracy, aiding forensic analysis, deepfake detection, and generative model transparency.
Diffuse or Confuse: A Diffusion Deepfake Speech Dataset
Oct 09, 2024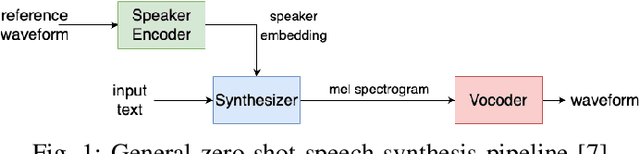
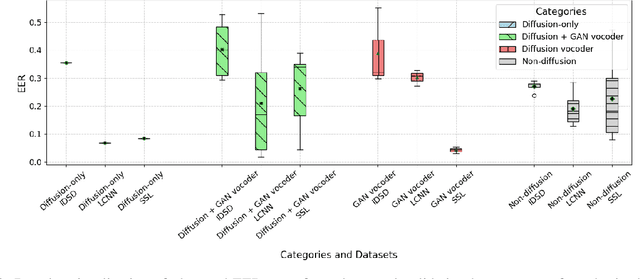
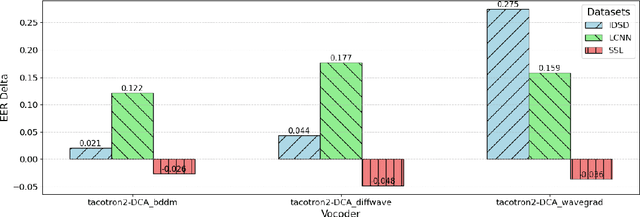
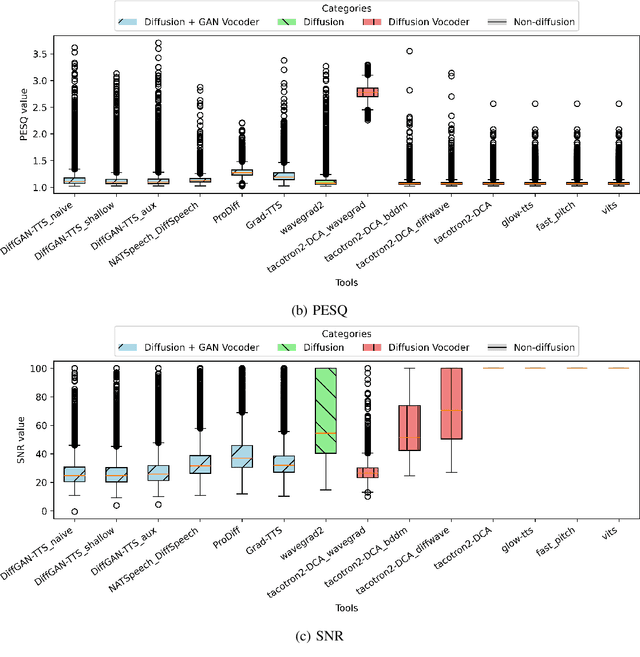
Advancements in artificial intelligence and machine learning have significantly improved synthetic speech generation. This paper explores diffusion models, a novel method for creating realistic synthetic speech. We create a diffusion dataset using available tools and pretrained models. Additionally, this study assesses the quality of diffusion-generated deepfakes versus non-diffusion ones and their potential threat to current deepfake detection systems. Findings indicate that the detection of diffusion-based deepfakes is generally comparable to non-diffusion deepfakes, with some variability based on detector architecture. Re-vocoding with diffusion vocoders shows minimal impact, and the overall speech quality is comparable to non-diffusion methods.
Enhancing Security of AI-Based Code Synthesis with GitHub Copilot via Cheap and Efficient Prompt-Engineering
Mar 19, 2024



AI assistants for coding are on the rise. However one of the reasons developers and companies avoid harnessing their full potential is the questionable security of the generated code. This paper first reviews the current state-of-the-art and identifies areas for improvement on this issue. Then, we propose a systematic approach based on prompt-altering methods to achieve better code security of (even proprietary black-box) AI-based code generators such as GitHub Copilot, while minimizing the complexity of the application from the user point-of-view, the computational resources, and operational costs. In sum, we propose and evaluate three prompt altering methods: (1) scenario-specific, (2) iterative, and (3) general clause, while we discuss their combination. Contrary to the audit of code security, the latter two of the proposed methods require no expert knowledge from the user. We assess the effectiveness of the proposed methods on the GitHub Copilot using the OpenVPN project in realistic scenarios, and we demonstrate that the proposed methods reduce the number of insecure generated code samples by up to 16\% and increase the number of secure code by up to 8\%. Since our approach does not require access to the internals of the AI models, it can be in general applied to any AI-based code synthesizer, not only GitHub Copilot.