 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffuse or Confuse: A Diffusion Deepfake Speech Dataset
Oct 09, 2024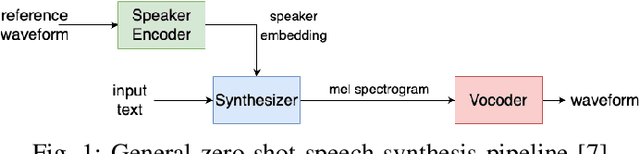
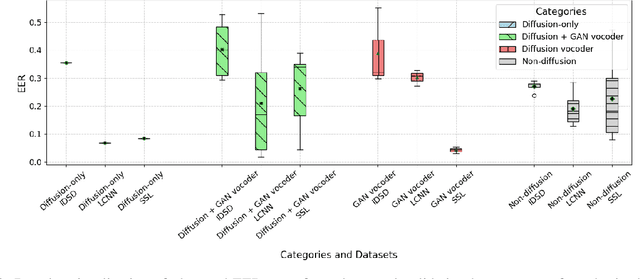
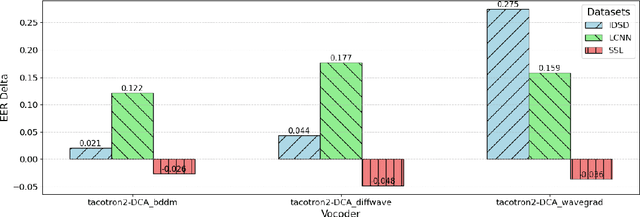
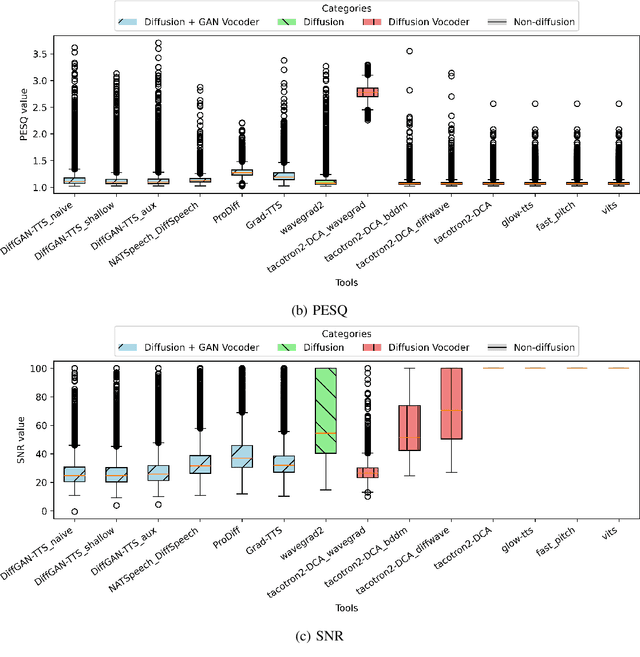
Advancements in artificial intelligence and machine learning have significantly improved synthetic speech generation. This paper explores diffusion models, a novel method for creating realistic synthetic speech. We create a diffusion dataset using available tools and pretrained models. Additionally, this study assesses the quality of diffusion-generated deepfakes versus non-diffusion ones and their potential threat to current deepfake detection systems. Findings indicate that the detection of diffusion-based deepfakes is generally comparable to non-diffusion deepfakes, with some variability based on detector architecture. Re-vocoding with diffusion vocoders shows minimal impact, and the overall speech quality is comparable to non-diffusion methods.