 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Optimization of ASV and CM tasks: BTUEF Team's Submission for WildSpoof Challenge
Feb 02, 2026Spoofing-aware speaker verification (SASV) jointly addresses automatic speaker verification and spoofing countermeasures to improve robustness against adversarial attacks. In this paper, we investigate our recently proposed modular SASV framework that enables effective reuse of publicly available ASV and CM systems through non-linear fusion, explicitly modeling their interaction, and optimization with an operating-condition-dependent trainable a-DCF loss. The framework is evaluated using ECAPA-TDNN and ReDimNet as ASV embedding extractors and SSL-AASIST as the CM model, with experiments conducted both with and without fine-tuning on the WildSpoof SASV training data. Results show that the best performance is achieved by combining ReDimNet-based ASV embeddings with fine-tuned SSL-AASIST representations, yielding an a-DCF of 0.0515 on the progress evaluation set and 0.2163 on the final evaluation set.
Joint Optimization of Speaker and Spoof Detectors for Spoofing-Robust Automatic Speaker Verification
Oct 02, 2025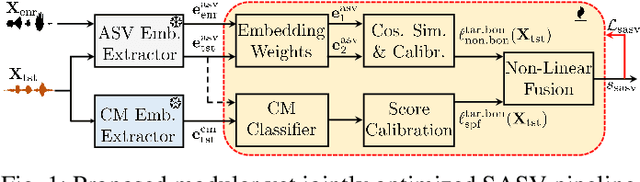
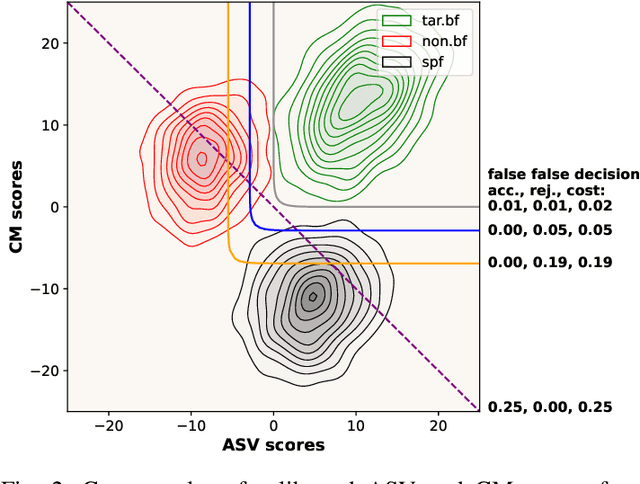
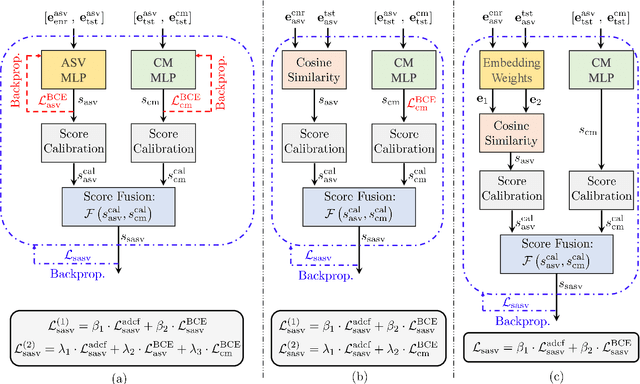
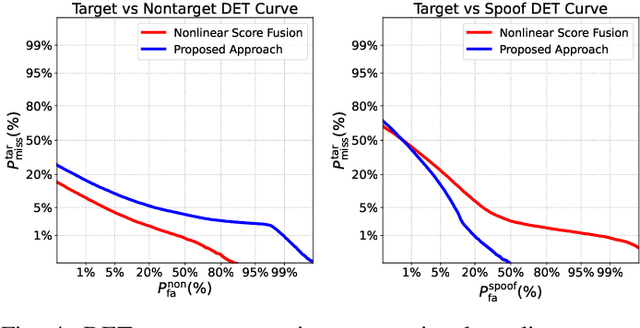
Spoofing-robust speaker verification (SASV) combines the tasks of speaker and spoof detection to authenticate speakers under adversarial settings. Many SASV systems rely on fusion of speaker and spoof cues at embedding, score or decision levels, based on independently trained subsystems. In this study, we respect similar modularity of the two subsystems, by integrating their outputs using trainable back-end classifiers. In particular, we explore various approaches for directly optimizing the back-end for the recently-proposed SASV performance metric (a-DCF) as a training objective. Our experiments on the ASVspoof 5 dataset demonstrate two important findings: (i) nonlinear score fusion consistently improves a-DCF over linear fusion, and (ii) the combination of weighted cosine scoring for speaker detection with SSL-AASIST for spoof detection achieves state-of-the-art performance, reducing min a-DCF to 0.196 and SPF-EER to 7.6%. These contributions highlight the importance of modular design, calibrated integration, and task-aligned optimization for advancing robust and interpretable SASV systems.
STOPA: A Database of Systematic VariaTion Of DeePfake Audio for Open-Set Source Tracing and Attribution
May 26, 2025A key research area in deepfake speech detection is source tracing - determining the origin of synthesised utterances. The approaches may involve identifying the acoustic model (AM), vocoder model (VM), or other generation-specific parameters. However, progress is limited by the lack of a dedicated, systematically curated dataset. To address this, we introduce STOPA, a systematically varied and metadata-rich dataset for deepfake speech source tracing, covering 8 AMs, 6 VMs, and diverse parameter settings across 700k samples from 13 distinct synthesisers. Unlike existing datasets, which often feature limited variation or sparse metadata, STOPA provides a systematically controlled framework covering a broader range of generative factors, such as the choice of the vocoder model, acoustic model, or pretrained weights, ensuring higher attribution reliability. This control improves attribution accuracy, aiding forensic analysis, deepfake detection, and generative model transparency.
Fairness of Automatic Speech Recognition in Cleft Lip and Palate Speech
May 06, 2025Speech produced by individuals with cleft lip and palate (CLP) is often highly nasalized and breathy due to structural anomalies, causing shifts in formant structure that affect automatic speech recognition (ASR) performance and fairness. This study hypothesizes that publicly available ASR systems exhibit reduced fairness for CLP speech and confirms this through experiments. Despite formant disruptions, mild and moderate CLP speech retains some spectro-temporal alignment with normal speech, motivating augmentation strategies to enhance fairness. The study systematically explores augmenting CLP speech with normal speech across severity levels and evaluates its impact on ASR fairness. Three ASR models-GMM-HMM, Whisper, and XLS-R-were tested on AIISH and NMCPC datasets. Results indicate that training with normal speech and testing on mixed data improves word error rate (WER). Notably, WER decreased from $22.64\%$ to $18.76\%$ (GMM-HMM, AIISH) and $28.45\%$ to $18.89\%$ (Whisper, NMCPC). The superior performance of GMM-HMM on AIISH may be due to its suitability for Kannada children's speech, a challenge for foundation models like XLS-R and Whisper. To assess fairness, a fairness score was introduced, revealing improvements of $17.89\%$ (AIISH) and $47.50\%$ (NMCPC) with augmentation.
Towards Explainable Spoofed Speech Attribution and Detection:a Probabilistic Approach for Characterizing Speech Synthesizer Components
Feb 07, 2025We propose an explainable probabilistic framework for characterizing spoofed speech by decomposing it into probabilistic attribute embeddings. Unlike raw high-dimensional countermeasure embeddings, which lack interpretability, the proposed probabilistic attribute embeddings aim to detect specific speech synthesizer components, represented through high-level attributes and their corresponding values. We use these probabilistic embeddings with four classifier back-ends to address two downstream tasks: spoofing detection and spoofing attack attribution. The former is the well-known bonafide-spoof detection task, whereas the latter seeks to identify the source method (generator) of a spoofed utterance. We additionally use Shapley values, a widely used technique in machine learning, to quantify the relative contribution of each attribute value to the decision-making process in each task. Results on the ASVspoof2019 dataset demonstrate the substantial role of duration and conversion modeling in spoofing detection; and waveform generation and speaker modeling in spoofing attack attribution. In the detection task, the probabilistic attribute embeddings achieve $99.7\%$ balanced accuracy and $0.22\%$ equal error rate (EER), closely matching the performance of raw embeddings ($99.9\%$ balanced accuracy and $0.22\%$ EER). Similarly, in the attribution task, our embeddings achieve $90.23\%$ balanced accuracy and $2.07\%$ EER, compared to $90.16\%$ and $2.11\%$ with raw embeddings. These results demonstrate that the proposed framework is both inherently explainable by design and capable of achieving performance comparable to raw CM embeddings.
An Explainable Probabilistic Attribute Embedding Approach for Spoofed Speech Characterization
Sep 17, 2024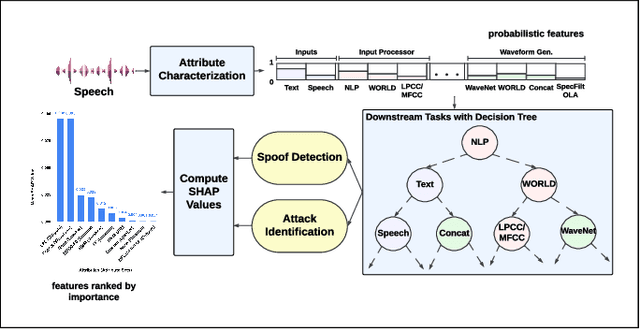
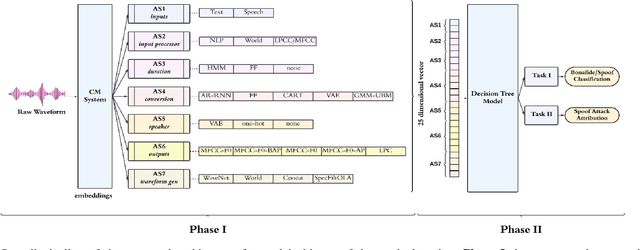
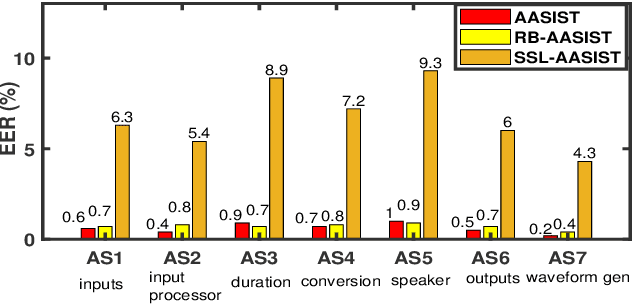
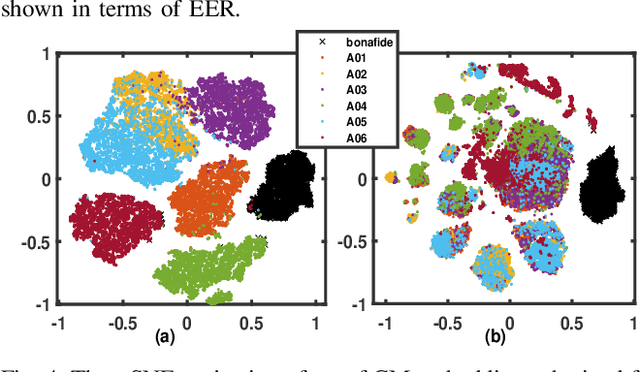
We propose a novel approach for spoofed speech characterization through explainable probabilistic attribute embeddings. In contrast to high-dimensional raw embeddings extracted from a spoofing countermeasure (CM) whose dimensions are not easy to interpret, the probabilistic attributes are designed to gauge the presence or absence of sub-components that make up a specific spoofing attack. These attributes are then applied to two downstream tasks: spoofing detection and attack attribution. To enforce interpretability also to the back-end, we adopt a decision tree classifier. Our experiments on the ASVspoof2019 dataset with spoof CM embeddings extracted from three models (AASIST, Rawboost-AASIST, SSL-AASIST) suggest that the performance of the attribute embeddings are on par with the original raw spoof CM embeddings for both tasks. The best performance achieved with the proposed approach for spoofing detection and attack attribution, in terms of accuracy, is 99.7% and 99.2%, respectively, compared to 99.7% and 94.7% using the raw CM embeddings. To analyze the relative contribution of each attribute, we estimate their Shapley values. Attributes related to acoustic feature prediction, waveform generation (vocoder), and speaker modeling are found important for spoofing detection; while duration modeling, vocoder, and input type play a role in spoofing attack attribution.
Spoofing-Robust Speaker Verification Using Parallel Embedding Fusion: BTU Speech Group's Approach for ASVspoof5 Challenge
Aug 28, 2024



This paper introduces the parallel network-based spoofing-aware speaker verification (SASV) system developed by BTU Speech Group for the ASVspoof5 Challenge. The SASV system integrates ASV and CM systems to enhance security against spoofing attacks. Our approach employs score and embedding fusion from ASV models (ECAPA-TDNN, WavLM) and CM models (AASIST). The fused embeddings are processed using a simple DNN structure, optimizing model performance with a combination of recently proposed a-DCF and BCE losses. We introduce a novel parallel network structure where two identical DNNs, fed with different inputs, independently process embeddings and produce SASV scores. The final SASV probability is derived by averaging these scores, enhancing robustness and accuracy. Experimental results demonstrate that the proposed parallel DNN structure outperforms traditional single DNN methods, offering a more reliable and secure speaker verification system against spoofing attacks.
Optimizing a-DCF for Spoofing-Robust Speaker Verification
Jul 04, 2024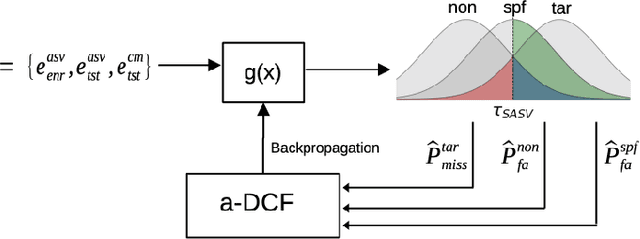
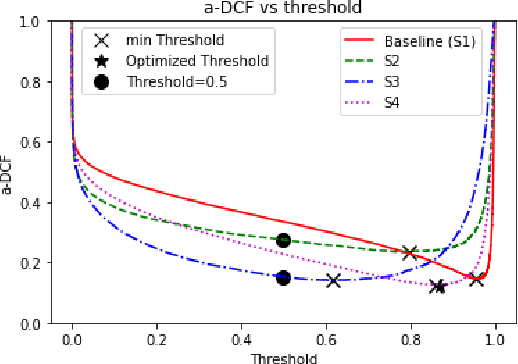
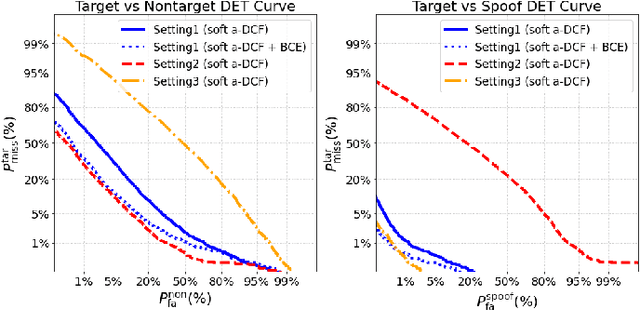
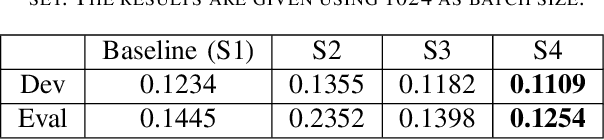
Automatic speaker verification (ASV) systems are vulnerable to spoofing attacks such as text-to-speech. In this study, we propose a novel spoofing-robust ASV back-end classifier, optimized directly for the recently introduced, architecture-agnostic detection cost function (a-DCF). We combine a-DCF and binary cross-entropy (BCE) losses to optimize the network weights, combined by a novel, straightforward detection threshold optimization technique. Experiments on the ASVspoof2019 database demonstrate considerable improvement over the baseline optimized using BCE only (from minimum a-DCF of 0.1445 to 0.1254), representing 13% relative improvement. These initial promising results demonstrate that it is possible to adjust an ASV system to find appropriate balance across the contradicting aims of user convenience and security against adversaries.
Implicit Self-supervised Language Representation for Spoken Language Diarization
Aug 21, 2023



In a code-switched (CS) scenario, the use of spoken language diarization (LD) as a pre-possessing system is essential. Further, the use of implicit frameworks is preferable over the explicit framework, as it can be easily adapted to deal with low/zero resource languages. Inspired by speaker diarization (SD) literature, three frameworks based on (1) fixed segmentation, (2) change point-based segmentation and (3) E2E are proposed to perform LD. The initial exploration with synthetic TTSF-LD dataset shows, using x-vector as implicit language representation with appropriate analysis window length ($N$) can able to achieve at per performance with explicit LD. The best implicit LD performance of $6.38$ in terms of Jaccard error rate (JER) is achieved by using the E2E framework. However, considering the E2E framework the performance of implicit LD degrades to $60.4$ while using with practical Microsoft CS (MSCS) dataset. The difference in performance is mostly due to the distributional difference between the monolingual segment duration of secondary language in the MSCS and TTSF-LD datasets. Moreover, to avoid segment smoothing, the smaller duration of the monolingual segment suggests the use of a small value of $N$. At the same time with small $N$, the x-vector representation is unable to capture the required language discrimination due to the acoustic similarity, as the same speaker is speaking both languages. Therefore, to resolve the issue a self-supervised implicit language representation is proposed in this study. In comparison with the x-vector representation, the proposed representation provides a relative improvement of $63.9\%$ and achieved a JER of $21.8$ using the E2E framework.
Implicit spoken language diarization
Jun 22, 2023



Spoken language diarization (LD) and related tasks are mostly explored using the phonotactic approach. Phonotactic approaches mostly use explicit way of language modeling, hence requiring intermediate phoneme modeling and transcribed data. Alternatively, the ability of deep learning approaches to model temporal dynamics may help for the implicit modeling of language information through deep embedding vectors. Hence this work initially explores the available speaker diarization frameworks that capture speaker information implicitly to perform LD tasks. The performance of the LD system on synthetic code-switch data using the end-to-end x-vector approach is 6.78% and 7.06%, and for practical data is 22.50% and 60.38%, in terms of diarization error rate and Jaccard error rate (JER), respectively. The performance degradation is due to the data imbalance and resolved to some extent by using pre-trained wave2vec embeddings that provide a relative improvement of 30.74% in terms of JER.