 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhonetically Explainable Speech Deepfake Detection
Jun 13, 2026Speech deepfake detection is predominantly treated as an opaque classification task where all temporal frames are aggregated equally. This ignores that different phonetic categories carry vastly different amounts of discriminative information. To address this, we propose a phoneme-guided cross-attention framework that transforms detection into an interpretable, phonetically grounded process. We factorize the spoofing posterior $P(\text{spoofed}\mid X, W)$, conditioned on the acoustic representation $X$ and the phonetic posteriorgram $W$. The resulting factorization can be written as $P(\text{spoofed} \mid X, W) = \sum_{i=1}^{M} w_i \cdot P(\text{spoofed} \mid X, Z = z_i)$, where $M$ denotes the number of phonetic classes, $P(\text{spoofed} \mid X, Z = z_i)$ is the spoofing probability for the $i$-th phonetic class $z_i$ conditioned on $X$, and each $w_i$ is the prevalence of phonetic class $z_i$ in the utterance. Our transformer-based architecture instantiates this through a cross-attention block in which phonetic queries selectively probe information in acoustic keys and values, with softmax-normalized pooling supplying explicit phone-presence weights. Unlike prior approaches that rely heavily on post-hoc explainability methods, our framework offers phonetic-explainability-by-design. We evaluate the framework on an LJSpeech-derived corpus, ASVspoof 2019 LA, and ASVspoof 5 Track 1. Per-phone importance rankings reveal that discriminative power concentrates on articulatory categories that generative models struggle to reproduce faithfully. Stops, fricatives, affricates, nasals, and silence-boundary closures rank most discriminative, while periodic vowels and semivowels rank lower. Beyond competitive performance, our model provides structural interpretability, yielding an inspectable per-articulatory category breakdown of the final verdict.
Kinship Verification Using Voice
Jun 01, 2026Kinship verification (KV) from voice, the task of determining whether two speakers are biologically related, has received only little attention. Our work establishes a foundational basis for this emerging frontier, contributing to both performance evaluation and detection methodologies. First, leveraging the speech recordings of the large-scale audio-visual dataset, KAN-AV, we propose a revised evaluation protocol that controls for various confounders and adopts a family-disjoint train--test split to address open-set KV. Second, we analyze the close connection between speaker verification and KV, showing that genealogical similarity of speaker pairs plays opposite roles in the two tasks. Third, we tackle KV using three neural speaker embedding extractors (ECAPA-TDNN, WavLM-ECAPA, and ReDimNet) combined with various back-ends. In zero-shot KV including same-speaker target trials, ReDimNet achieves the lowest equal error rate (EER) of $20.8\%$; however, performance degrades to $39.7\%$ under strict kin trials, where same-speaker target trials are excluded. Our best trainable back-end, which applies asymmetric processing of the embedding pair to mitigate age-difference effects, obtains an EER of $32.0\%$ ($18.6\%$ with speaker target trials included). These results highlight the difficulty of KV while showing that speaker embeddings encode familial cues, offering a promising foundation for voice-based kinship analysis.
Disentangling Speaker Traits for Deepfake Source Verification via Chebyshev Polynomial and Riemannian Metric Learning
Mar 23, 2026Speech deepfake source verification systems aims to determine whether two synthetic speech utterances originate from the same source generator, often assuming that the resulting source embeddings are independent of speaker traits. However, this assumption remains unverified. In this paper, we first investigate the impact of speaker factors on source verification. We propose a speaker-disentangled metric learning (SDML) framework incorporating two novel loss functions. The first leverages Chebyshev polynomial to mitigate gradient instability during disentanglement optimization. The second projects source and speaker embeddings into hyperbolic space, leveraging Riemannian metric distances to reduce speaker information and learn more discriminative source features. Experimental results on MLAAD benchmark, evaluated under four newly proposed protocols designed for source-speaker disentanglement scenarios, demonstrate the effectiveness of SDML framework. The code, evaluation protocols and demo website are available at https://github.com/xxuan-acoustics/RiemannSD-Net.
WST-X Series: Wavelet Scattering Transform for Interpretable Speech Deepfake Detection
Feb 03, 2026Designing front-ends for speech deepfake detectors primarily focuses on two categories. Hand-crafted filterbank features are transparent but are limited in capturing high-level semantic details, often resulting in performance gaps compared to self-supervised (SSL) features. SSL features, in turn, lack interpretability and may overlook fine-grained spectral anomalies. We propose the WST-X series, a novel family of feature extractors that combines the best of both worlds via the wavelet scattering transform (WST), integrating wavelets with nonlinearities analogous to deep convolutional networks. We investigate 1D and 2D WSTs to extract acoustic details and higher-order structural anomalies, respectively. Experimental results on the recent and challenging Deepfake-Eval-2024 dataset indicate that WST-X outperforms existing front-ends by a wide margin. Our analysis reveals that a small averaging scale ($J$), combined with high-frequency and directional resolutions ($Q, L$), is critical for capturing subtle artifacts. This underscores the value of translation-invariant and deformation-stable features for robust and interpretable speech deepfake detection.
Shortcut Learning in Binary Classifier Black Boxes: Applications to Voice Anti-Spoofing and Biometrics
Jan 25, 2026The widespread adoption of deep-learning models in data-driven applications has drawn attention to the potential risks associated with biased datasets and models. Neglected or hidden biases within datasets and models can lead to unexpected results. This study addresses the challenges of dataset bias and explores ``shortcut learning'' or ``Clever Hans effect'' in binary classifiers. We propose a novel framework for analyzing the black-box classifiers and for examining the impact of both training and test data on classifier scores. Our framework incorporates intervention and observational perspectives, employing a linear mixed-effects model for post-hoc analysis. By evaluating classifier performance beyond error rates, we aim to provide insights into biased datasets and offer a comprehensive understanding of their influence on classifier behavior. The effectiveness of our approach is demonstrated through experiments on audio anti-spoofing and speaker verification tasks using both statistical models and deep neural networks. The insights gained from this study have broader implications for tackling biases in other domains and advancing the field of explainable artificial intelligence.
Joint Optimization of Speaker and Spoof Detectors for Spoofing-Robust Automatic Speaker Verification
Oct 02, 2025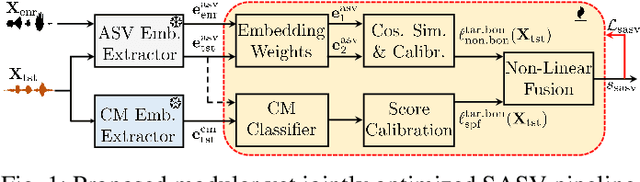
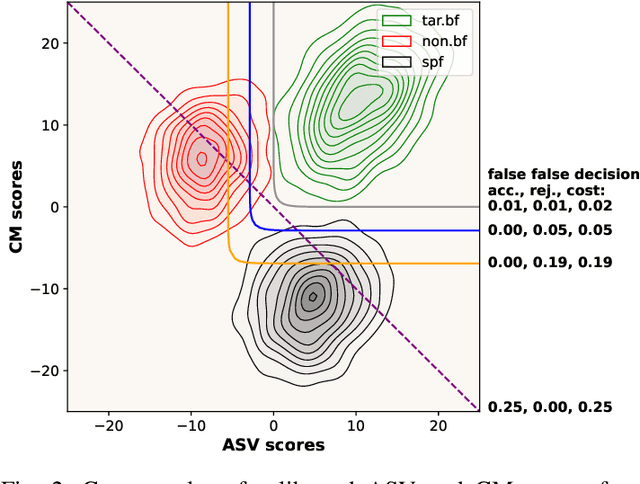
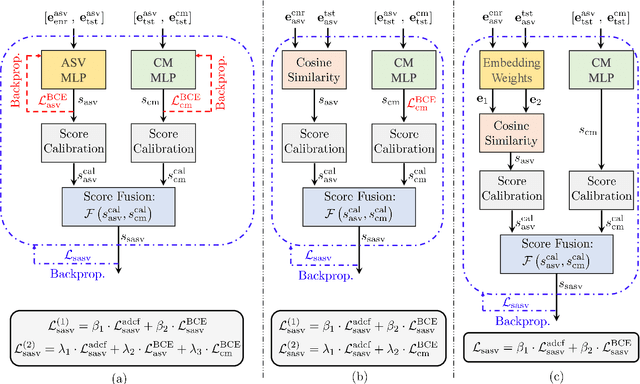
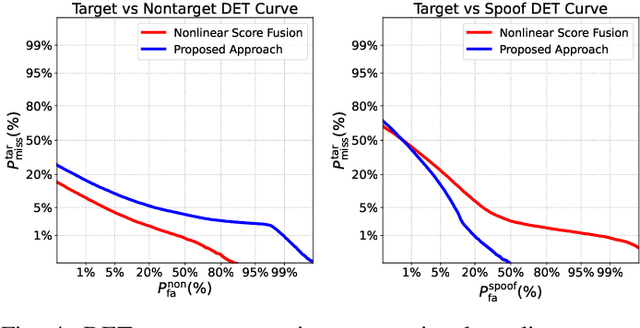
Spoofing-robust speaker verification (SASV) combines the tasks of speaker and spoof detection to authenticate speakers under adversarial settings. Many SASV systems rely on fusion of speaker and spoof cues at embedding, score or decision levels, based on independently trained subsystems. In this study, we respect similar modularity of the two subsystems, by integrating their outputs using trainable back-end classifiers. In particular, we explore various approaches for directly optimizing the back-end for the recently-proposed SASV performance metric (a-DCF) as a training objective. Our experiments on the ASVspoof 5 dataset demonstrate two important findings: (i) nonlinear score fusion consistently improves a-DCF over linear fusion, and (ii) the combination of weighted cosine scoring for speaker detection with SSL-AASIST for spoof detection achieves state-of-the-art performance, reducing min a-DCF to 0.196 and SPF-EER to 7.6%. These contributions highlight the importance of modular design, calibrated integration, and task-aligned optimization for advancing robust and interpretable SASV systems.
Towards Explainable Spoofed Speech Attribution and Detection:a Probabilistic Approach for Characterizing Speech Synthesizer Components
Feb 07, 2025We propose an explainable probabilistic framework for characterizing spoofed speech by decomposing it into probabilistic attribute embeddings. Unlike raw high-dimensional countermeasure embeddings, which lack interpretability, the proposed probabilistic attribute embeddings aim to detect specific speech synthesizer components, represented through high-level attributes and their corresponding values. We use these probabilistic embeddings with four classifier back-ends to address two downstream tasks: spoofing detection and spoofing attack attribution. The former is the well-known bonafide-spoof detection task, whereas the latter seeks to identify the source method (generator) of a spoofed utterance. We additionally use Shapley values, a widely used technique in machine learning, to quantify the relative contribution of each attribute value to the decision-making process in each task. Results on the ASVspoof2019 dataset demonstrate the substantial role of duration and conversion modeling in spoofing detection; and waveform generation and speaker modeling in spoofing attack attribution. In the detection task, the probabilistic attribute embeddings achieve $99.7\%$ balanced accuracy and $0.22\%$ equal error rate (EER), closely matching the performance of raw embeddings ($99.9\%$ balanced accuracy and $0.22\%$ EER). Similarly, in the attribution task, our embeddings achieve $90.23\%$ balanced accuracy and $2.07\%$ EER, compared to $90.16\%$ and $2.11\%$ with raw embeddings. These results demonstrate that the proposed framework is both inherently explainable by design and capable of achieving performance comparable to raw CM embeddings.
An Explainable Probabilistic Attribute Embedding Approach for Spoofed Speech Characterization
Sep 17, 2024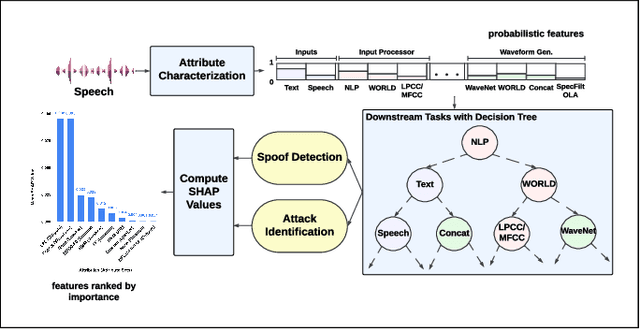
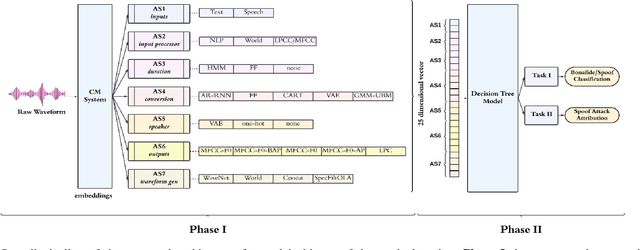
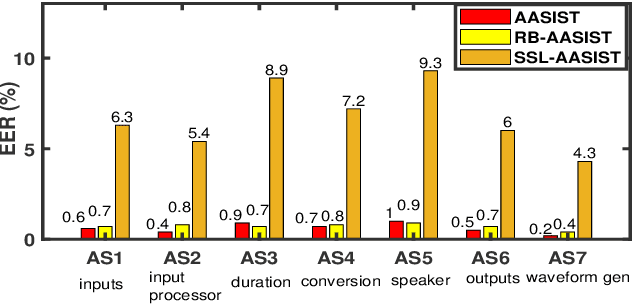
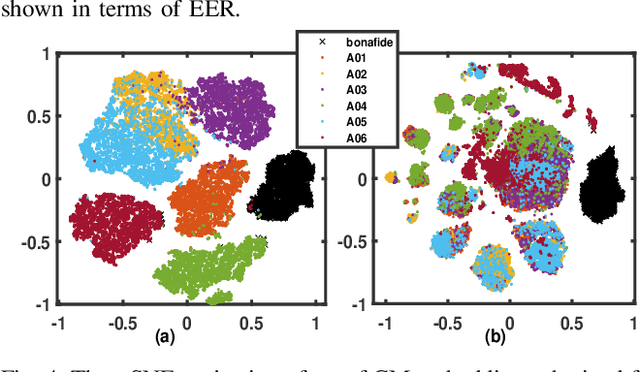
We propose a novel approach for spoofed speech characterization through explainable probabilistic attribute embeddings. In contrast to high-dimensional raw embeddings extracted from a spoofing countermeasure (CM) whose dimensions are not easy to interpret, the probabilistic attributes are designed to gauge the presence or absence of sub-components that make up a specific spoofing attack. These attributes are then applied to two downstream tasks: spoofing detection and attack attribution. To enforce interpretability also to the back-end, we adopt a decision tree classifier. Our experiments on the ASVspoof2019 dataset with spoof CM embeddings extracted from three models (AASIST, Rawboost-AASIST, SSL-AASIST) suggest that the performance of the attribute embeddings are on par with the original raw spoof CM embeddings for both tasks. The best performance achieved with the proposed approach for spoofing detection and attack attribution, in terms of accuracy, is 99.7% and 99.2%, respectively, compared to 99.7% and 94.7% using the raw CM embeddings. To analyze the relative contribution of each attribute, we estimate their Shapley values. Attributes related to acoustic feature prediction, waveform generation (vocoder), and speaker modeling are found important for spoofing detection; while duration modeling, vocoder, and input type play a role in spoofing attack attribution.
Optimizing a-DCF for Spoofing-Robust Speaker Verification
Jul 04, 2024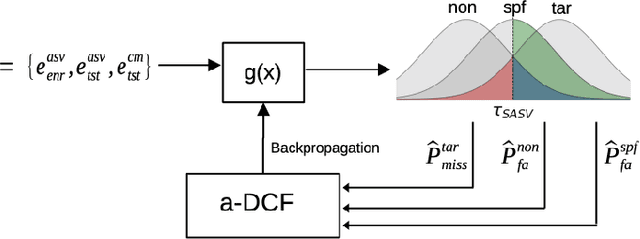
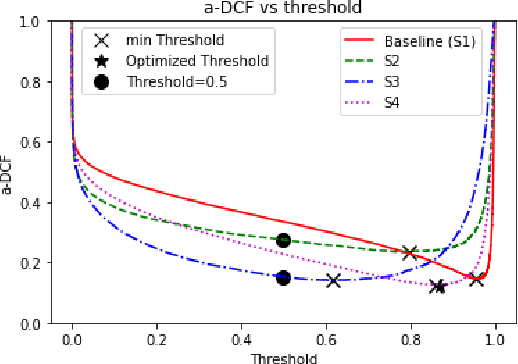
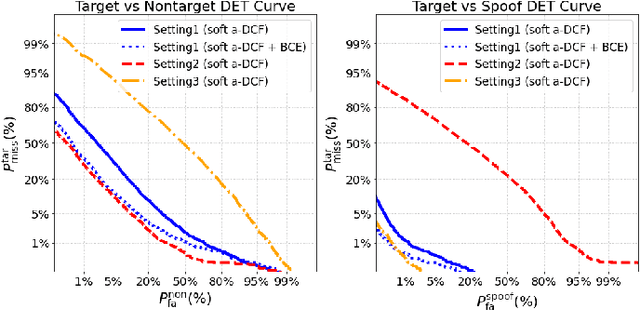
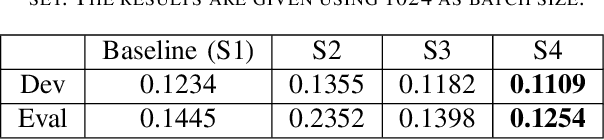
Automatic speaker verification (ASV) systems are vulnerable to spoofing attacks such as text-to-speech. In this study, we propose a novel spoofing-robust ASV back-end classifier, optimized directly for the recently introduced, architecture-agnostic detection cost function (a-DCF). We combine a-DCF and binary cross-entropy (BCE) losses to optimize the network weights, combined by a novel, straightforward detection threshold optimization technique. Experiments on the ASVspoof2019 database demonstrate considerable improvement over the baseline optimized using BCE only (from minimum a-DCF of 0.1445 to 0.1254), representing 13% relative improvement. These initial promising results demonstrate that it is possible to adjust an ASV system to find appropriate balance across the contradicting aims of user convenience and security against adversaries.
An Initial study on Birdsong Re-synthesis Using Neural Vocoders
Sep 21, 2022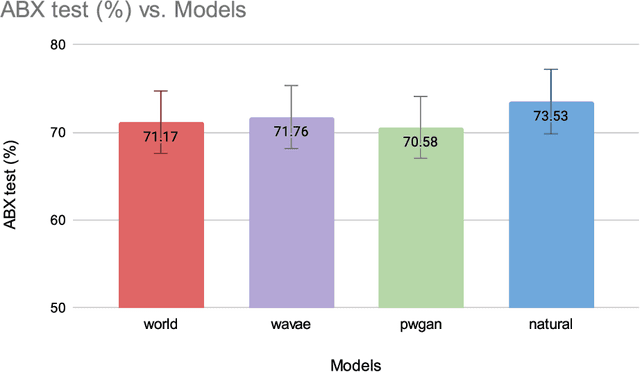
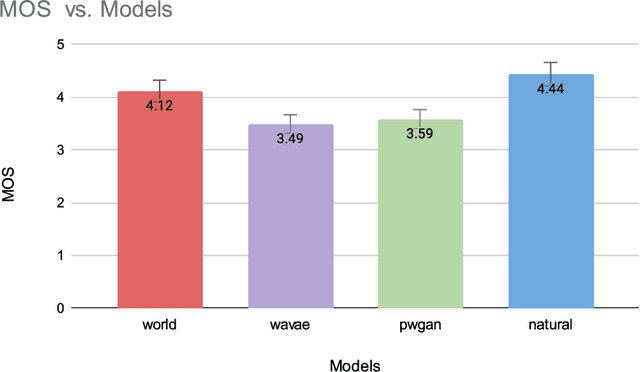
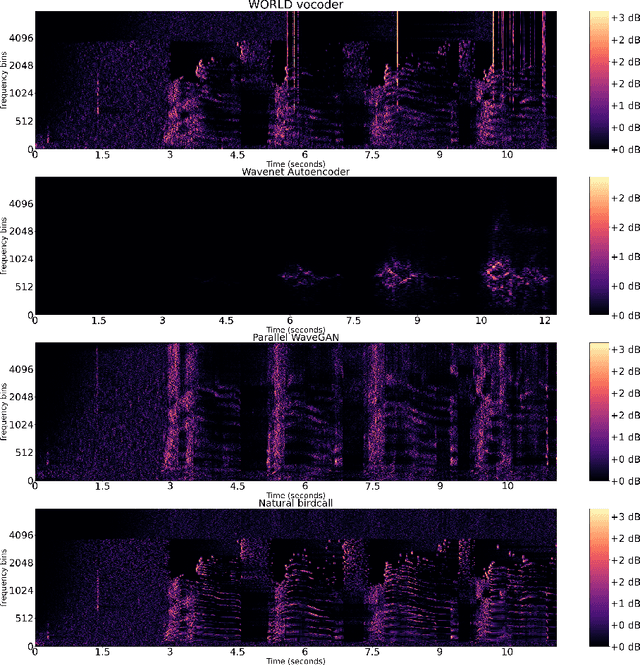
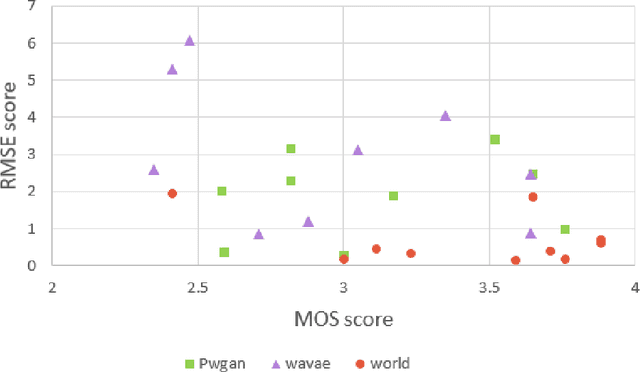
Modern speech synthesis uses neural vocoders to model raw waveform samples directly. This increased versatility has expanded the scope of vocoders from speech to other domains, such as music. We address another interesting domain of bio-acoustics. We provide initial comparative analysis-resynthesis experiments of birdsong using traditional (WORLD) and two neural (WaveNet autoencoder, parallel WaveGAN) vocoders. Our subjective results indicate no difference in the three vocoders in terms of species discrimination (ABX test). Nonetheless, the WORLD vocoder samples were rated higher in terms of retaining bird-like qualities (MOS test). All vocoders faced issues with pitch and voicing. Our results indicate some of the challenges in processing low-quality wildlife audio data.