 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHYB-VITON: A Hybrid Approach to Virtual Try-On Combining Explicit and Implicit Warping
Jan 07, 2025



Virtual try-on systems have significant potential in e-commerce, allowing customers to visualize garments on themselves. Existing image-based methods fall into two categories: those that directly warp garment-images onto person-images (explicit warping), and those using cross-attention to reconstruct given garments (implicit warping). Explicit warping preserves garment details but often produces unrealistic output, while implicit warping achieves natural reconstruction but struggles with fine details. We propose HYB-VITON, a novel approach that combines the advantages of each method and includes both a preprocessing pipeline for warped garments and a novel training option. These components allow us to utilize beneficial regions of explicitly warped garments while leveraging the natural reconstruction of implicit warping. A series of experiments demonstrates that HYB-VITON preserves garment details more faithfully than recent diffusion-based methods, while producing more realistic results than a state-of-the-art explicit warping method.
Reading Is Believing: Revisiting Language Bottleneck Models for Image Classification
Jun 22, 2024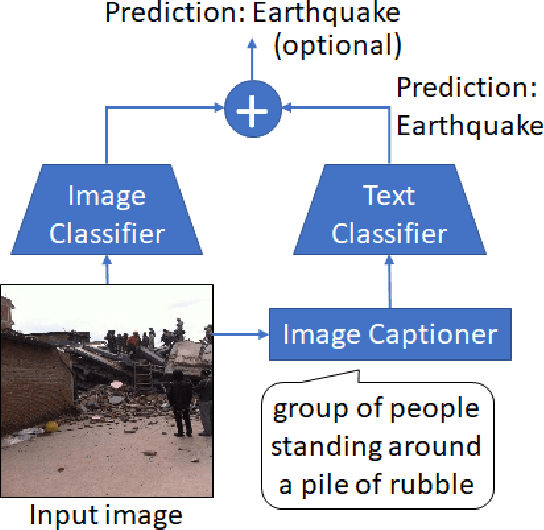
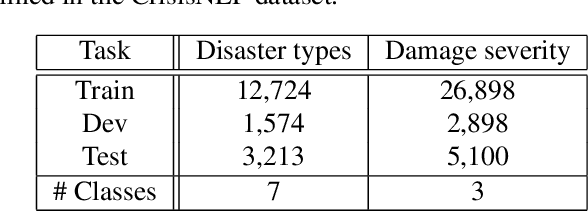
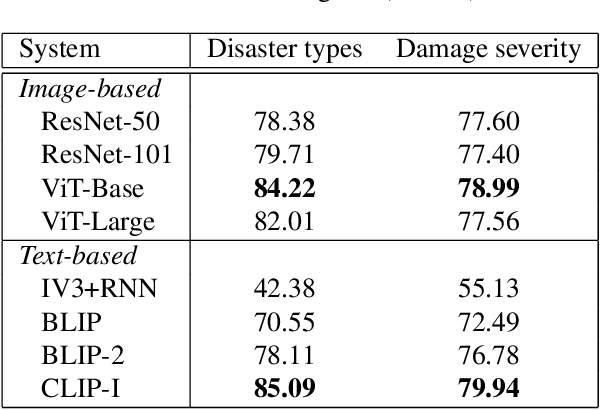

We revisit language bottleneck models as an approach to ensuring the explainability of deep learning models for image classification. Because of inevitable information loss incurred in the step of converting images into language, the accuracy of language bottleneck models is considered to be inferior to that of standard black-box models. Recent image captioners based on large-scale foundation models of Vision and Language, however, have the ability to accurately describe images in verbal detail to a degree that was previously believed to not be realistically possible. In a task of disaster image classification, we experimentally show that a language bottleneck model that combines a modern image captioner with a pre-trained language model can achieve image classification accuracy that exceeds that of black-box models. We also demonstrate that a language bottleneck model and a black-box model may be thought to extract different features from images and that fusing the two can create a synergistic effect, resulting in even higher classification accuracy.
Generalized domain adaptation framework for parametric back-end in speaker recognition
May 24, 2023



State-of-the-art speaker recognition systems comprise a speaker embedding front-end followed by a probabilistic linear discriminant analysis (PLDA) back-end. The effectiveness of these components relies on the availability of a large amount of labeled training data. In practice, it is common for domains (e.g., language, channel, demographic) in which a system is deployed to differ from that in which a system has been trained. To close the resulting gap, domain adaptation is often essential for PLDA models. Among two of its variants are Heavy-tailed PLDA (HT-PLDA) and Gaussian PLDA (G-PLDA). Though the former better fits real feature spaces than does the latter, its popularity has been severely limited by its computational complexity and, especially, by the difficulty, it presents in domain adaptation, which results from its non-Gaussian property. Various domain adaptation methods have been proposed for G-PLDA. This paper proposes a generalized framework for domain adaptation that can be applied to both of the above variants of PLDA for speaker recognition. It not only includes several existing supervised and unsupervised domain adaptation methods but also makes possible more flexible usage of available data in different domains. In particular, we introduce here two new techniques: (1) correlation-alignment in the model level, and (2) covariance regularization. To the best of our knowledge, this is the first proposed application of such techniques for domain adaptation w.r.t. HT-PLDA. The efficacy of the proposed techniques has been experimentally validated on NIST 2016, 2018, and 2019 Speaker Recognition Evaluation (SRE'16, SRE'18, and SRE'19) datasets.
Image Captioners Sometimes Tell More Than Images They See
May 11, 2023



Image captioning, a.k.a. "image-to-text," which generates descriptive text from given images, has been rapidly developing throughout the era of deep learning. To what extent is the information in the original image preserved in the descriptive text generated by an image captioner? To answer that question, we have performed experiments involving the classification of images from descriptive text alone, without referring to the images at all, and compared results with those from standard image-based classifiers. We have evaluate several image captioning models with respect to a disaster image classification task, CrisisNLP, and show that descriptive text classifiers can sometimes achieve higher accuracy than standard image-based classifiers. Further, we show that fusing an image-based classifier with a descriptive text classifier can provide improvement in accuracy.
Task-aware Warping Factors in Mask-based Speech Enhancement
Aug 27, 2021
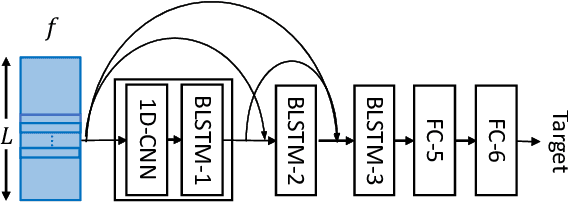
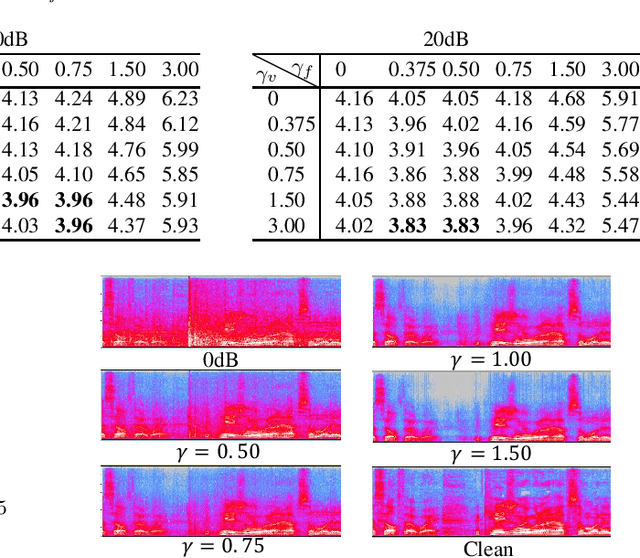
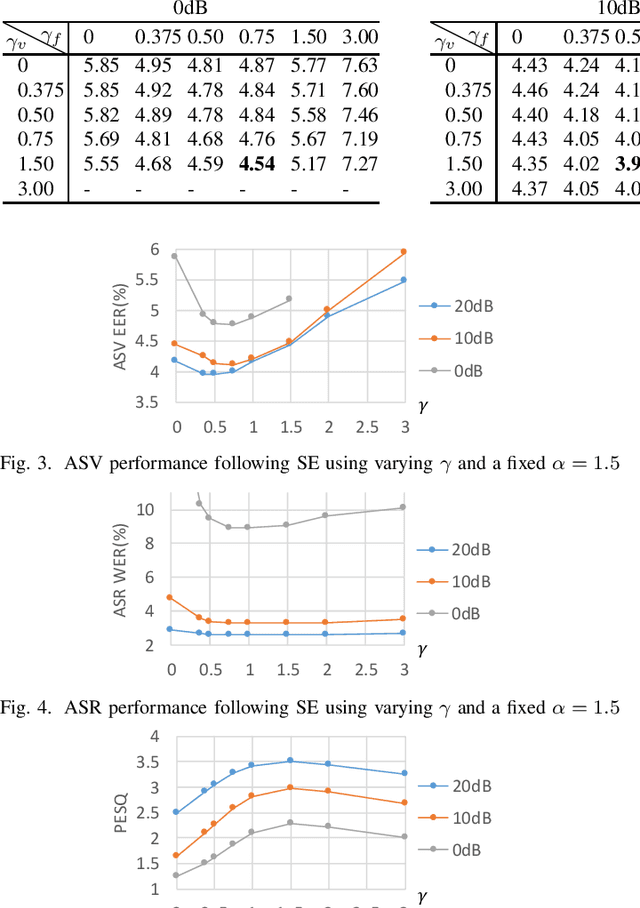
This paper proposes the use of two task-aware warping factors in mask-based speech enhancement (SE). One controls the balance between speech-maintenance and noise-removal in training phases, while the other controls SE power applied to specific downstream tasks in testing phases. Our intention is to alleviate the problem that SE systems trained to improve speech quality often fail to improve other downstream tasks, such as automatic speaker verification (ASV) and automatic speech recognition (ASR), because they do not share the same objects. It is easy to apply the proposed dual-warping factors approach to any mask-based SE method, and it allows a single SE system to handle multiple tasks without task-dependent training. The effectiveness of our proposed approach has been confirmed on the SITW dataset for ASV evaluation and the LibriSpeech dataset for ASR and speech quality evaluations of 0-20dB. We show that different warping values are necessary for a single SE to achieve optimal performance w.r.t. the three tasks. With the use of task-dependent warping factors, speech quality was improved by an 84.7% PESQ increase, ASV had a 22.4% EER reduction, and ASR had a 52.2% WER reduction, on 0dB speech. The effectiveness of the task-dependent warping factors were also cross-validated on VoxCeleb-1 test set for ASV and LibriSpeech dev-clean set for ASV and quality evaluations. The proposed method is highly effective and easy to apply in practice.
Xi-Vector Embedding for Speaker Recognition
Aug 12, 2021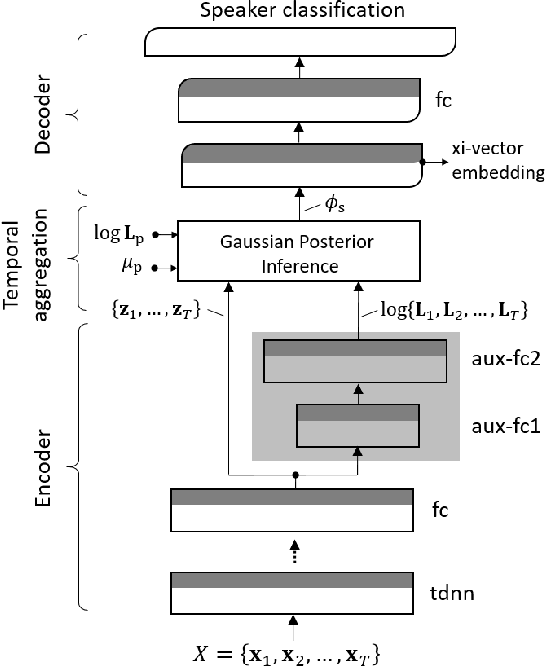

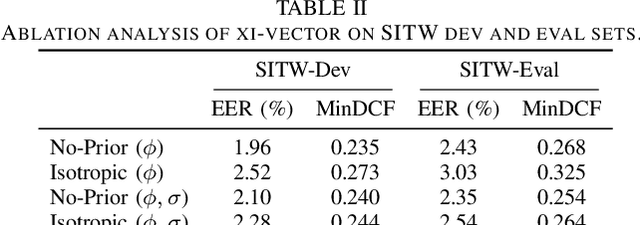

We present a Bayesian formulation for deep speaker embedding, wherein the xi-vector is the Bayesian counterpart of the x-vector, taking into account the uncertainty estimate. On the technology front, we offer a simple and straightforward extension to the now widely used x-vector. It consists of an auxiliary neural net predicting the frame-wise uncertainty of the input sequence. We show that the proposed extension leads to substantial improvement across all operating points, with a significant reduction in error rates and detection cost. On the theoretical front, our proposal integrates the Bayesian formulation of linear Gaussian model to speaker-embedding neural networks via the pooling layer. In one sense, our proposal integrates the Bayesian formulation of the i-vector to that of the x-vector. Hence, we refer to the embedding as the xi-vector, which is pronounced as /zai/ vector. Experimental results on the SITW evaluation set show a consistent improvement of over 17.5% in equal-error-rate and 10.9% in minimum detection cost.
Unleashing the Unused Potential of I-Vectors Enabled by GPU Acceleration
Jun 20, 2019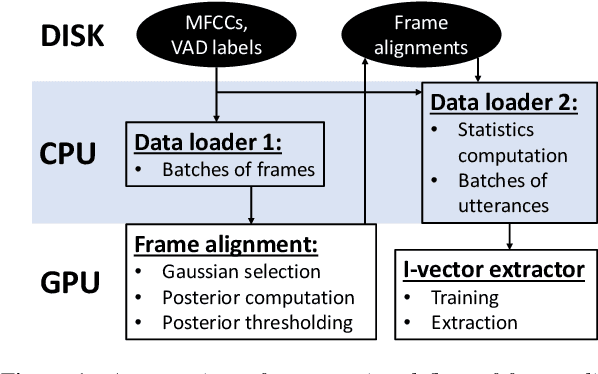
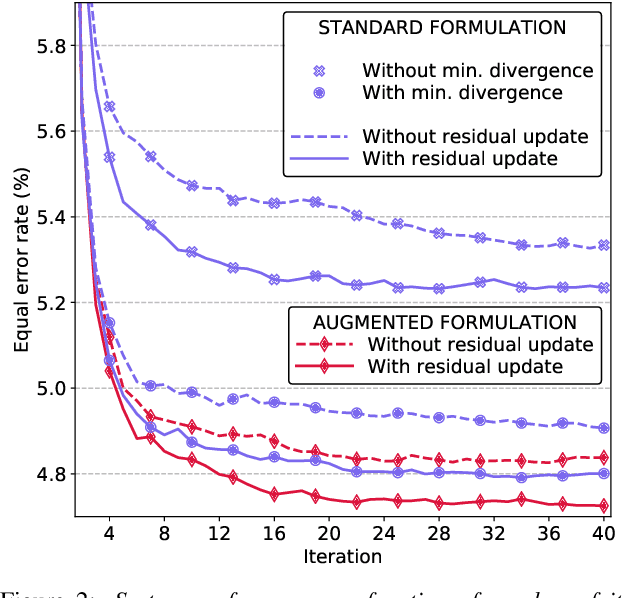
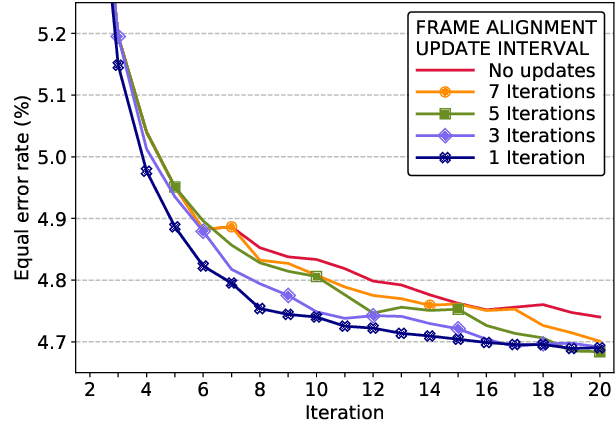
Speaker embeddings are continuous-value vector representations that allow easy comparison between voices of speakers with simple geometric operations. Among others, i-vector and x-vector have emerged as the mainstream methods for speaker embedding. In this paper, we illustrate the use of modern computation platform to harness the benefit of GPU acceleration for i-vector extraction. In particular, we achieve an acceleration of 3000 times in frame posterior computation compared to real time and 25 times in training the i-vector extractor compared to the CPU baseline from Kaldi toolkit. This significant speed-up allows the exploration of ideas that were hitherto impossible. In particular, we show that it is beneficial to update the universal background model (UBM) and re-compute frame alignments while training the i-vector extractor. Additionally, we are able to study different variations of i-vector extractors more rigorously than before. In this process, we reveal some undocumented details of Kaldi's i-vector extractor and show that it outperforms the standard formulation by a margin of 1 to 2% when tested with VoxCeleb speaker verification protocol. All of our findings are asserted by ensemble averaging the results from multiple runs with random start.
I4U Submission to NIST SRE 2018: Leveraging from a Decade of Shared Experiences
Apr 16, 2019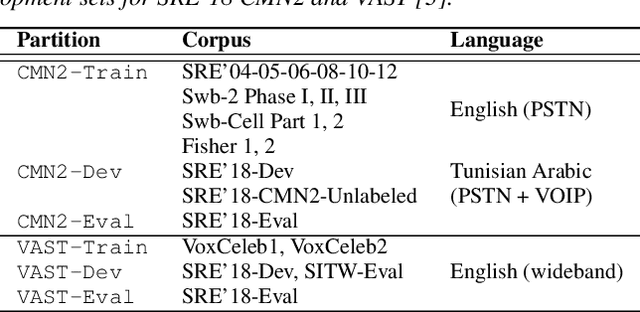
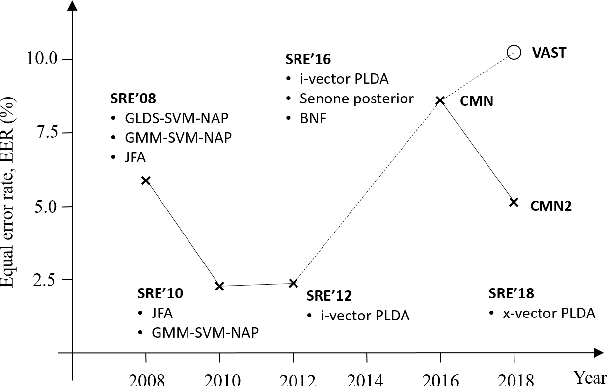
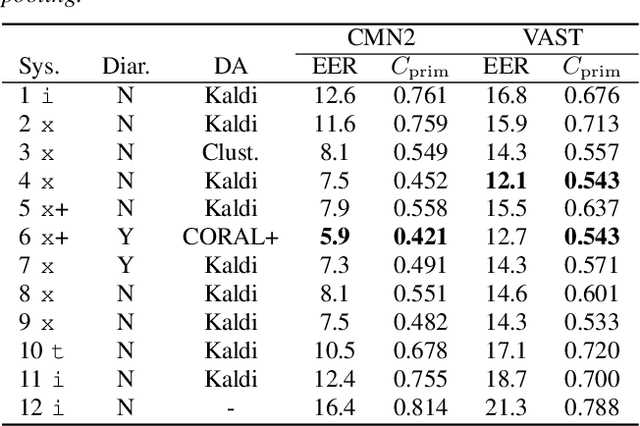
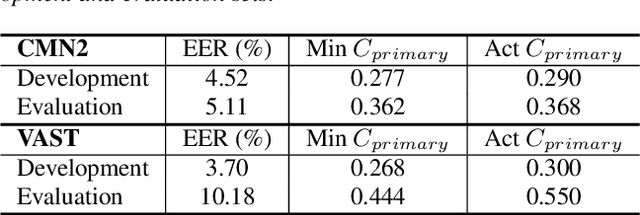
The I4U consortium was established to facilitate a joint entry to NIST speaker recognition evaluations (SRE). The latest edition of such joint submission was in SRE 2018, in which the I4U submission was among the best-performing systems. SRE'18 also marks the 10-year anniversary of I4U consortium into NIST SRE series of evaluation. The primary objective of the current paper is to summarize the results and lessons learned based on the twelve sub-systems and their fusion submitted to SRE'18. It is also our intention to present a shared view on the advancements, progresses, and major paradigm shifts that we have witnessed as an SRE participant in the past decade from SRE'08 to SRE'18. In this regard, we have seen, among others, a paradigm shift from supervector representation to deep speaker embedding, and a switch of research challenge from channel compensation to domain adaptation.
The CORAL+ Algorithm for Unsupervised Domain Adaptation of PLDA
Dec 26, 2018


State-of-the-art speaker recognition systems comprise an x-vector (or i-vector) speaker embedding front-end followed by a probabilistic linear discriminant analysis (PLDA) backend. The effectiveness of these components relies on the availability of a large collection of labeled training data. In practice, it is common that the domains (e.g., language, demographic) in which the system are deployed differs from that we trained the system. To close the gap due to the domain mismatch, we propose an unsupervised PLDA adaptation algorithm to learn from a small amount of unlabeled in-domain data. The proposed method was inspired by a prior work on feature-based domain adaptation technique known as the correlation alignment (CORAL). We refer to the model-based adaptation technique proposed in this paper as CORAL+. The efficacy of the proposed technique is experimentally validated on the recent NIST 2016 and 2018 Speaker Recognition Evaluation (SRE'16, SRE'18) datasets.