 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized domain adaptation framework for parametric back-end in speaker recognition
May 24, 2023



State-of-the-art speaker recognition systems comprise a speaker embedding front-end followed by a probabilistic linear discriminant analysis (PLDA) back-end. The effectiveness of these components relies on the availability of a large amount of labeled training data. In practice, it is common for domains (e.g., language, channel, demographic) in which a system is deployed to differ from that in which a system has been trained. To close the resulting gap, domain adaptation is often essential for PLDA models. Among two of its variants are Heavy-tailed PLDA (HT-PLDA) and Gaussian PLDA (G-PLDA). Though the former better fits real feature spaces than does the latter, its popularity has been severely limited by its computational complexity and, especially, by the difficulty, it presents in domain adaptation, which results from its non-Gaussian property. Various domain adaptation methods have been proposed for G-PLDA. This paper proposes a generalized framework for domain adaptation that can be applied to both of the above variants of PLDA for speaker recognition. It not only includes several existing supervised and unsupervised domain adaptation methods but also makes possible more flexible usage of available data in different domains. In particular, we introduce here two new techniques: (1) correlation-alignment in the model level, and (2) covariance regularization. To the best of our knowledge, this is the first proposed application of such techniques for domain adaptation w.r.t. HT-PLDA. The efficacy of the proposed techniques has been experimentally validated on NIST 2016, 2018, and 2019 Speaker Recognition Evaluation (SRE'16, SRE'18, and SRE'19) datasets.
I4U System Description for NIST SRE'20 CTS Challenge
Nov 02, 2022



This manuscript describes the I4U submission to the 2020 NIST Speaker Recognition Evaluation (SRE'20) Conversational Telephone Speech (CTS) Challenge. The I4U's submission was resulted from active collaboration among researchers across eight research teams - I$^2$R (Singapore), UEF (Finland), VALPT (Italy, Spain), NEC (Japan), THUEE (China), LIA (France), NUS (Singapore), INRIA (France) and TJU (China). The submission was based on the fusion of top performing sub-systems and sub-fusion systems contributed by individual teams. Efforts have been spent on the use of common development and validation sets, submission schedule and milestone, minimizing inconsistency in trial list and score file format across sites.
Task-aware Warping Factors in Mask-based Speech Enhancement
Aug 27, 2021
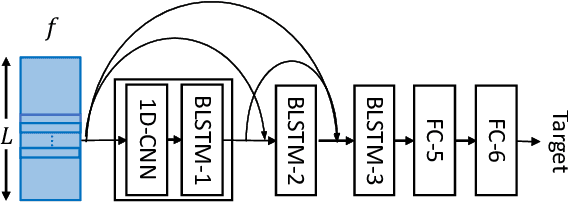
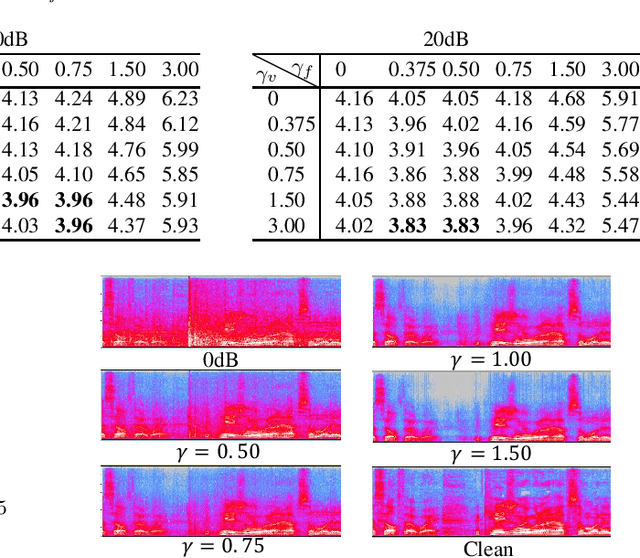
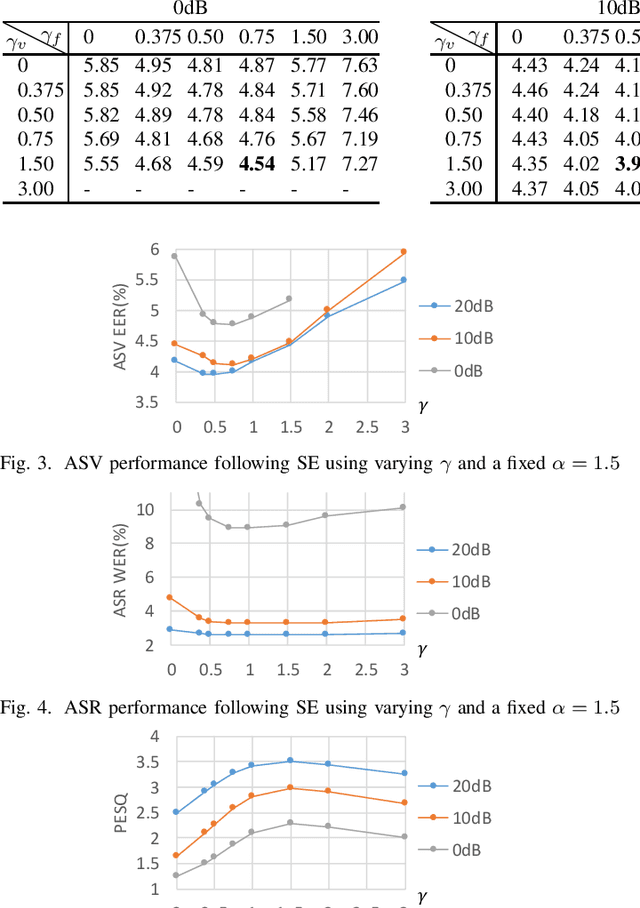
This paper proposes the use of two task-aware warping factors in mask-based speech enhancement (SE). One controls the balance between speech-maintenance and noise-removal in training phases, while the other controls SE power applied to specific downstream tasks in testing phases. Our intention is to alleviate the problem that SE systems trained to improve speech quality often fail to improve other downstream tasks, such as automatic speaker verification (ASV) and automatic speech recognition (ASR), because they do not share the same objects. It is easy to apply the proposed dual-warping factors approach to any mask-based SE method, and it allows a single SE system to handle multiple tasks without task-dependent training. The effectiveness of our proposed approach has been confirmed on the SITW dataset for ASV evaluation and the LibriSpeech dataset for ASR and speech quality evaluations of 0-20dB. We show that different warping values are necessary for a single SE to achieve optimal performance w.r.t. the three tasks. With the use of task-dependent warping factors, speech quality was improved by an 84.7% PESQ increase, ASV had a 22.4% EER reduction, and ASR had a 52.2% WER reduction, on 0dB speech. The effectiveness of the task-dependent warping factors were also cross-validated on VoxCeleb-1 test set for ASV and LibriSpeech dev-clean set for ASV and quality evaluations. The proposed method is highly effective and easy to apply in practice.
I4U Submission to NIST SRE 2018: Leveraging from a Decade of Shared Experiences
Apr 16, 2019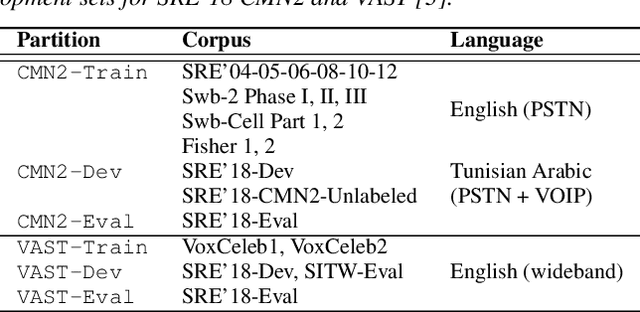
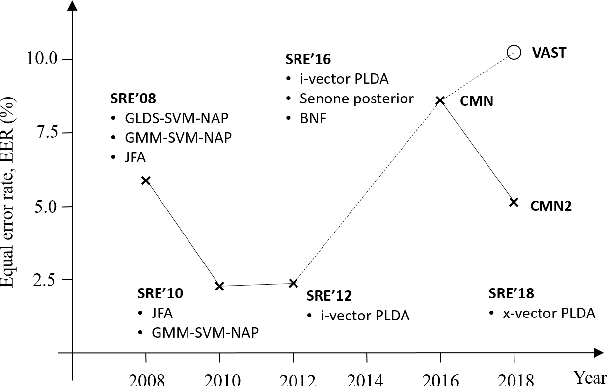
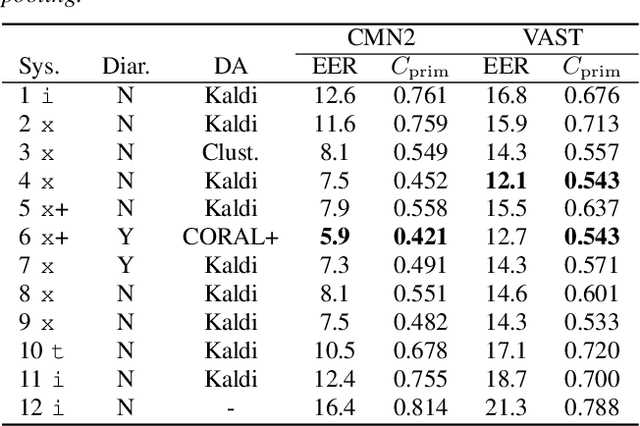
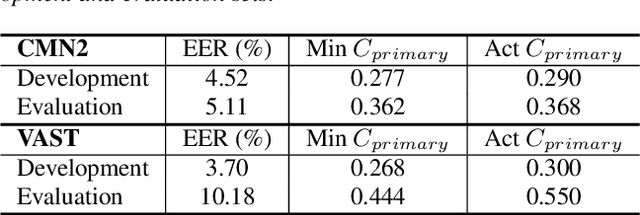
The I4U consortium was established to facilitate a joint entry to NIST speaker recognition evaluations (SRE). The latest edition of such joint submission was in SRE 2018, in which the I4U submission was among the best-performing systems. SRE'18 also marks the 10-year anniversary of I4U consortium into NIST SRE series of evaluation. The primary objective of the current paper is to summarize the results and lessons learned based on the twelve sub-systems and their fusion submitted to SRE'18. It is also our intention to present a shared view on the advancements, progresses, and major paradigm shifts that we have witnessed as an SRE participant in the past decade from SRE'08 to SRE'18. In this regard, we have seen, among others, a paradigm shift from supervector representation to deep speaker embedding, and a switch of research challenge from channel compensation to domain adaptation.