 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI4U Submission to NIST SRE 2018: Leveraging from a Decade of Shared Experiences
Apr 16, 2019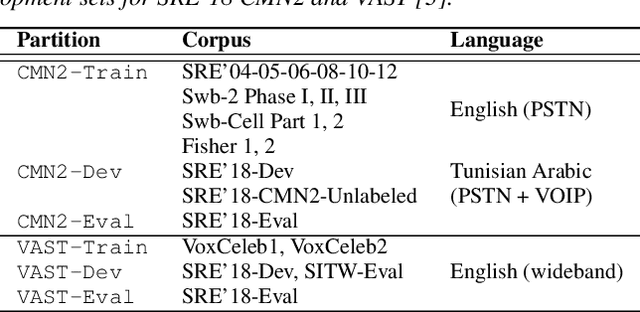
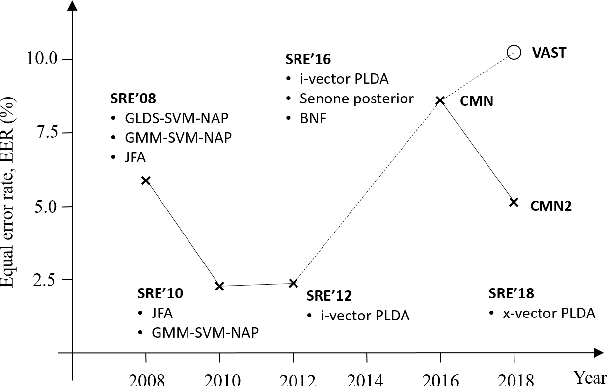
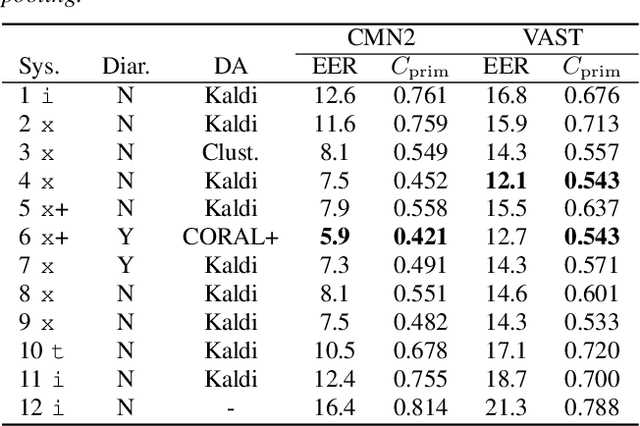
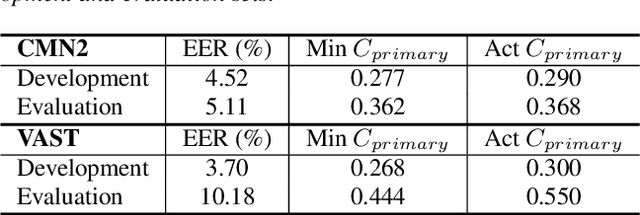
The I4U consortium was established to facilitate a joint entry to NIST speaker recognition evaluations (SRE). The latest edition of such joint submission was in SRE 2018, in which the I4U submission was among the best-performing systems. SRE'18 also marks the 10-year anniversary of I4U consortium into NIST SRE series of evaluation. The primary objective of the current paper is to summarize the results and lessons learned based on the twelve sub-systems and their fusion submitted to SRE'18. It is also our intention to present a shared view on the advancements, progresses, and major paradigm shifts that we have witnessed as an SRE participant in the past decade from SRE'08 to SRE'18. In this regard, we have seen, among others, a paradigm shift from supervector representation to deep speaker embedding, and a switch of research challenge from channel compensation to domain adaptation.
Deep Speaker Embedding Learning with Multi-Level Pooling for Text-Independent Speaker Verification
Feb 21, 2019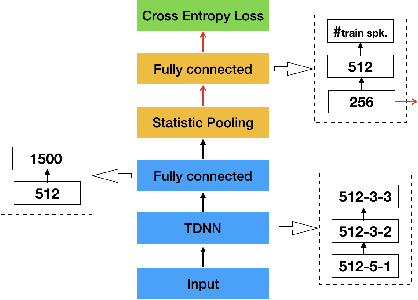

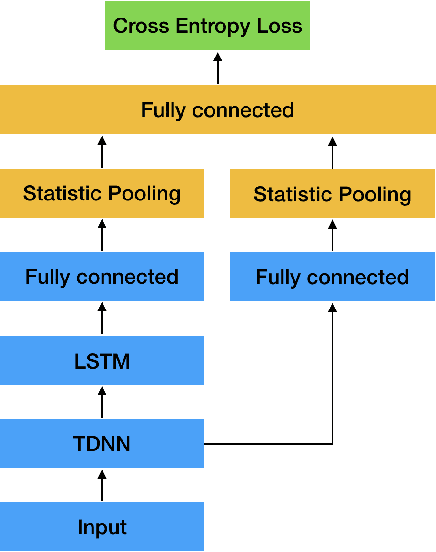
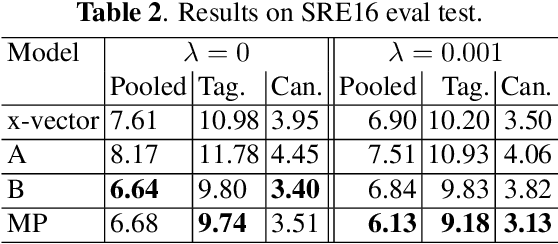
This paper aims to improve the widely used deep speaker embedding x-vector model. We propose the following improvements: (1) a hybrid neural network structure using both time delay neural network (TDNN) and long short-term memory neural networks (LSTM) to generate complementary speaker information at different levels; (2) a multi-level pooling strategy to collect speaker information from both TDNN and LSTM layers; (3) a regularization scheme on the speaker embedding extraction layer to make the extracted embeddings suitable for the following fusion step. The synergy of these improvements are shown on the NIST SRE 2016 eval test (with a 19% EER reduction) and SRE 2018 dev test (with a 9% EER reduction), as well as more than 10% DCF scores reduction on these two test sets over the x-vector baseline.