 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Learning for Children's ASR: Overcoming Catastrophic Forgetting with Elastic Weight Consolidation and Synaptic Intelligence
May 26, 2025In this work, we present the first study addressing automatic speech recognition (ASR) for children in an online learning setting. This is particularly important for both child-centric applications and the privacy protection of minors, where training models with sequentially arriving data is critical. The conventional approach of model fine-tuning often suffers from catastrophic forgetting. To tackle this issue, we explore two established techniques: elastic weight consolidation (EWC) and synaptic intelligence (SI). Using a custom protocol on the MyST corpus, tailored to the online learning setting, we achieve relative word error rate (WER) reductions of 5.21% with EWC and 4.36% with SI, compared to the fine-tuning baseline.
Search-Based Adversarial Estimates for Improving Sample Efficiency in Off-Policy Reinforcement Learning
Feb 03, 2025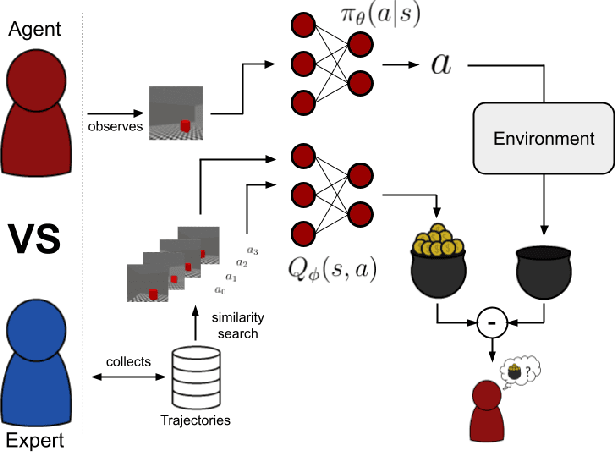
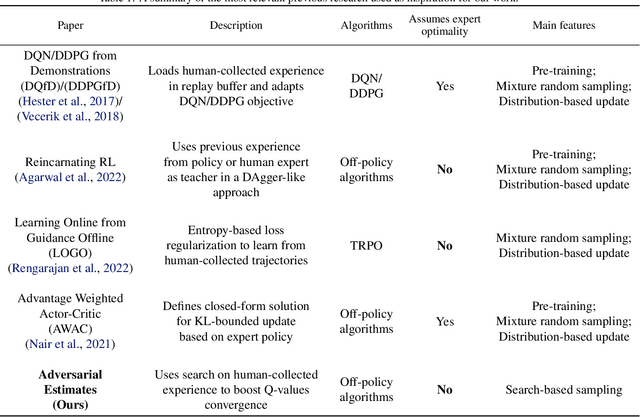
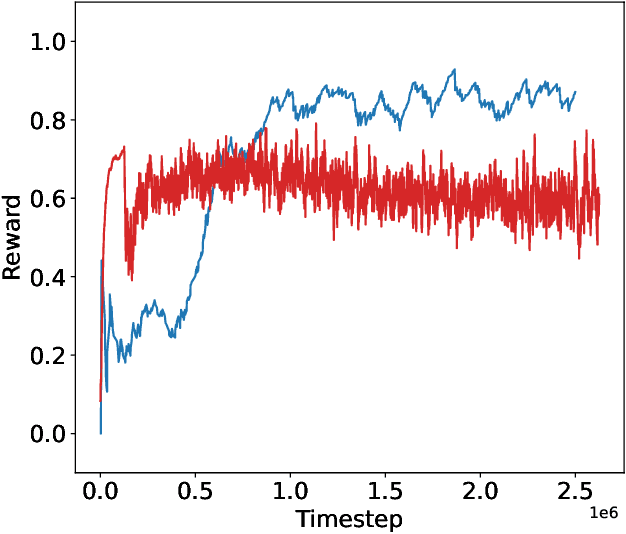
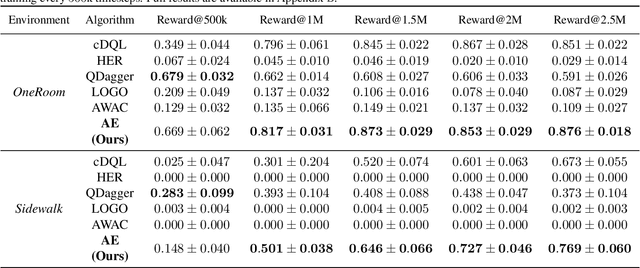
Sample inefficiency is a long-lasting challenge in deep reinforcement learning (DRL). Despite dramatic improvements have been made, the problem is far from being solved and is especially challenging in environments with sparse or delayed rewards. In our work, we propose to use Adversarial Estimates as a new, simple and efficient approach to mitigate this problem for a class of feedback-based DRL algorithms. Our approach leverages latent similarity search from a small set of human-collected trajectories to boost learning, using only five minutes of human-recorded experience. The results of our study show algorithms trained with Adversarial Estimates converge faster than their original version. Moreover, we discuss how our approach could enable learning in feedback-based algorithms in extreme scenarios with very sparse rewards.
ROAR: Reinforcing Original to Augmented Data Ratio Dynamics for Wav2Vec2.0 Based ASR
Jun 14, 2024



While automatic speech recognition (ASR) greatly benefits from data augmentation, the augmentation recipes themselves tend to be heuristic. In this paper, we address one of the heuristic approach associated with balancing the right amount of augmented data in ASR training by introducing a reinforcement learning (RL) based dynamic adjustment of original-to-augmented data ratio (OAR). Unlike the fixed OAR approach in conventional data augmentation, our proposed method employs a deep Q-network (DQN) as the RL mechanism to learn the optimal dynamics of OAR throughout the wav2vec2.0 based ASR training. We conduct experiments using the LibriSpeech dataset with varying amounts of training data, specifically, the 10Min, 1H, 10H, and 100H splits to evaluate the efficacy of the proposed method under different data conditions. Our proposed method, on average, achieves a relative improvement of 4.96% over the open-source wav2vec2.0 base model on standard LibriSpeech test sets.
* Accepted: Interspeech 2024
Online Adaptation for Enhancing Imitation Learning Policies
Jun 07, 2024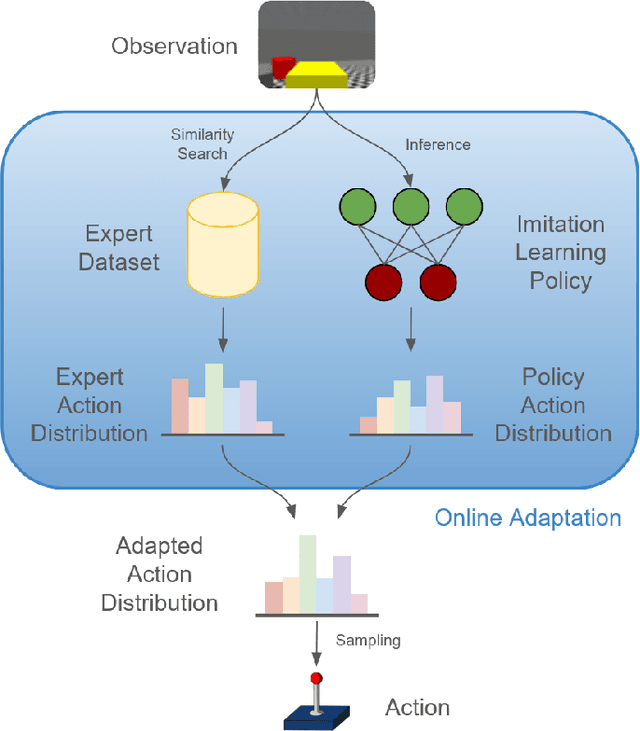

Imitation learning enables autonomous agents to learn from human examples, without the need for a reward signal. Still, if the provided dataset does not encapsulate the task correctly, or when the task is too complex to be modeled, such agents fail to reproduce the expert policy. We propose to recover from these failures through online adaptation. Our approach combines the action proposal coming from a pre-trained policy with relevant experience recorded by an expert. The combination results in an adapted action that closely follows the expert. Our experiments show that an adapted agent performs better than its pure imitation learning counterpart. Notably, adapted agents can achieve reasonable performance even when the base, non-adapted policy catastrophically fails.
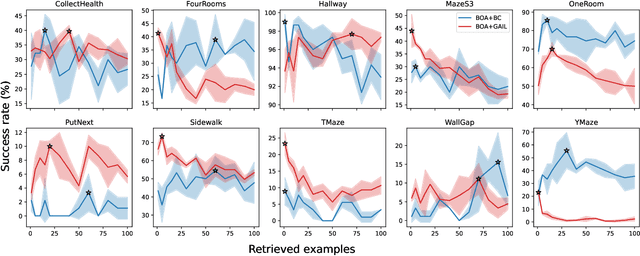
Zero-shot Imitation Policy via Search in Demonstration Dataset
Jan 29, 2024Behavioral cloning uses a dataset of demonstrations to learn a policy. To overcome computationally expensive training procedures and address the policy adaptation problem, we propose to use latent spaces of pre-trained foundation models to index a demonstration dataset, instantly access similar relevant experiences, and copy behavior from these situations. Actions from a selected similar situation can be performed by the agent until representations of the agent's current situation and the selected experience diverge in the latent space. Thus, we formulate our control problem as a dynamic search problem over a dataset of experts' demonstrations. We test our approach on BASALT MineRL-dataset in the latent representation of a Video Pre-Training model. We compare our model to state-of-the-art, Imitation Learning-based Minecraft agents. Our approach can effectively recover meaningful demonstrations and show human-like behavior of an agent in the Minecraft environment in a wide variety of scenarios. Experimental results reveal that performance of our search-based approach clearly wins in terms of accuracy and perceptual evaluation over learning-based models.
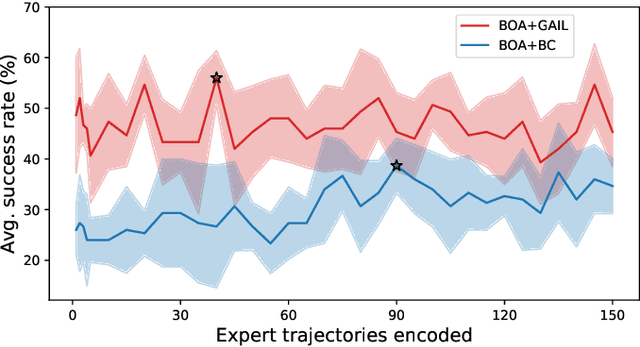
Behavioral Cloning via Search in Embedded Demonstration Dataset
Jun 15, 2023



Behavioural cloning uses a dataset of demonstrations to learn a behavioural policy. To overcome various learning and policy adaptation problems, we propose to use latent space to index a demonstration dataset, instantly access similar relevant experiences, and copy behavior from these situations. Actions from a selected similar situation can be performed by the agent until representations of the agent's current situation and the selected experience diverge in the latent space. Thus, we formulate our control problem as a search problem over a dataset of experts' demonstrations. We test our approach on BASALT MineRL-dataset in the latent representation of a Video PreTraining model. We compare our model to state-of-the-art Minecraft agents. Our approach can effectively recover meaningful demonstrations and show human-like behavior of an agent in the Minecraft environment in a wide variety of scenarios. Experimental results reveal that performance of our search-based approach is comparable to trained models, while allowing zero-shot task adaptation by changing the demonstration examples.
PL-EESR: Perceptual Loss Based END-TO-END Robust Speaker Representation Extraction
Oct 03, 2021


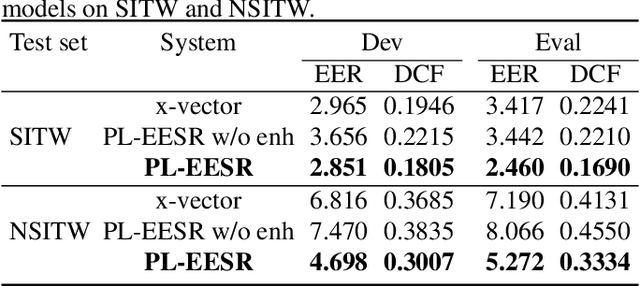
Speech enhancement aims to improve the perceptual quality of the speech signal by suppression of the background noise. However, excessive suppression may lead to speech distortion and speaker information loss, which degrades the performance of speaker embedding extraction. To alleviate this problem, we propose an end-to-end deep learning framework, dubbed PL-EESR, for robust speaker representation extraction. This framework is optimized based on the feedback of the speaker identification task and the high-level perceptual deviation between the raw speech signal and its noisy version. We conducted speaker verification tasks in both noisy and clean environment respectively to evaluate our system. Compared to the baseline, our method shows better performance in both clean and noisy environments, which means our method can not only enhance the speaker relative information but also avoid adding distortions.
VoxCeleb Enrichment for Age and Gender Recognition
Sep 28, 2021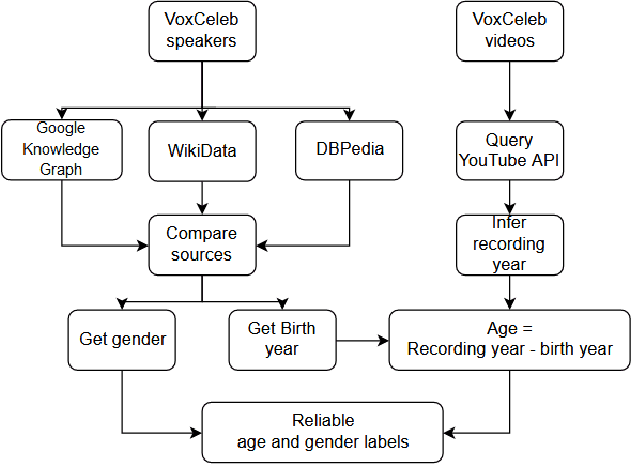
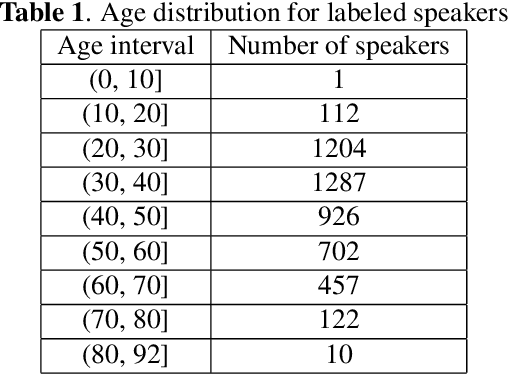
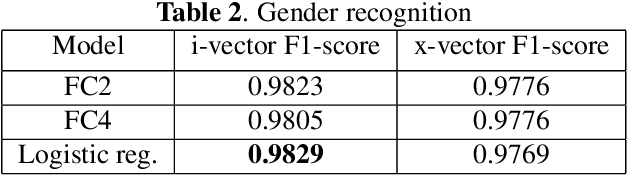
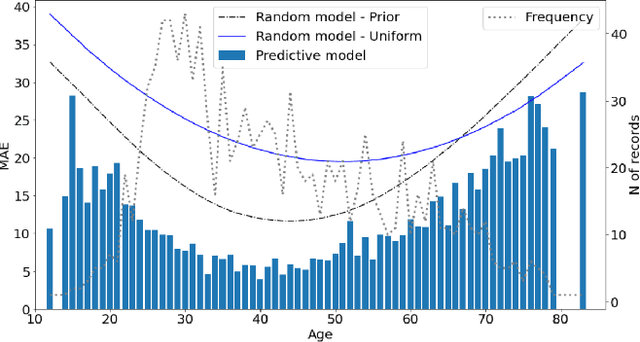
VoxCeleb datasets are widely used in speaker recognition studies. Our work serves two purposes. First, we provide speaker age labels and (an alternative) annotation of speaker gender. Second, we demonstrate the use of this metadata by constructing age and gender recognition models with different features and classifiers. We query different celebrity databases and apply consensus rules to derive age and gender labels. We also compare the original VoxCeleb gender labels with our labels to identify records that might be mislabeled in the original VoxCeleb data. On modeling side, we design a comprehensive study of multiple features and models for recognizing gender and age. Our best system, using i-vector features, achieved an F1-score of 0.9829 for gender recognition task using logistic regression, and the lowest mean absolute error (MAE) in age regression, 9.443 years, is obtained with ridge regression. This indicates challenge in age estimation from in-the-wild style speech data.
Transferring Monolingual Model to Low-Resource Language: The Case of Tigrinya
Jun 19, 2020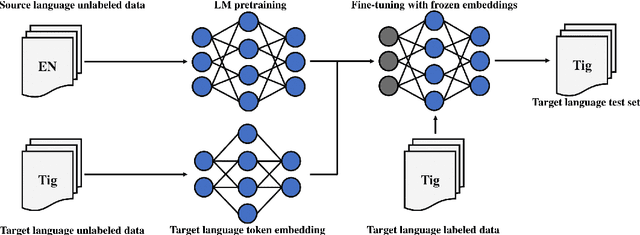


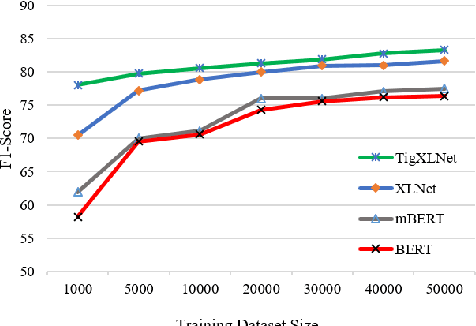
In recent years, transformer models have achieved great success in natural language processing (NLP) tasks. Most of the current state-of-the-art NLP results are achieved by using monolingual transformer models, where the model is pre-trained using a single language unlabelled text corpus. Then, the model is fine-tuned to the specific downstream task. However, the cost of pre-training a new transformer model is high for most languages. In this work, we propose a cost-effective transfer learning method to adopt a strong source language model, trained from a large monolingual corpus to a low-resource language. Thus, using XLNet language model, we demonstrate competitive performance with mBERT and a pre-trained target language model on the cross-lingual sentiment (CLS) dataset and on a new sentiment analysis dataset for low-resourced language Tigrinya. With only 10k examples of the given Tigrinya sentiment analysis dataset, English XLNet has achieved 78.88% F1-Score outperforming BERT and mBERT by 10% and 7%, respectively. More interestingly, fine-tuning (English) XLNet model on the CLS dataset has promising results compared to mBERT and even outperformed mBERT for one dataset of the Japanese language.
Do Autonomous Agents Benefit from Hearing?
May 10, 2019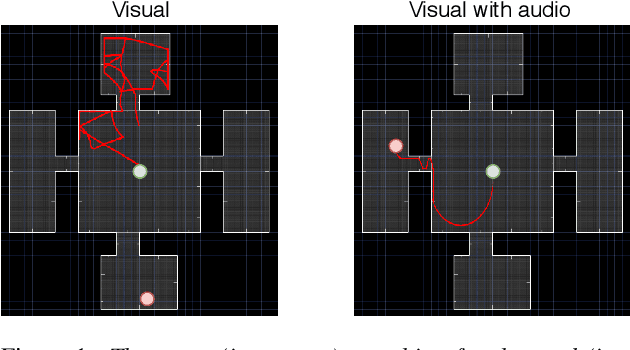

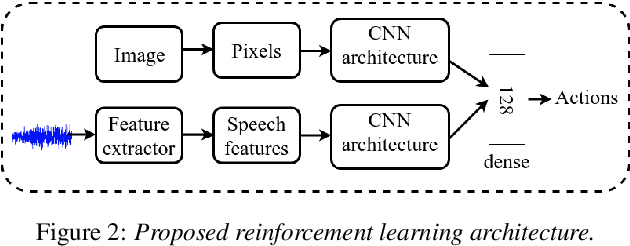
Mapping states to actions in deep reinforcement learning is mainly based on visual information. The commonly used approach for dealing with visual information is to extract pixels from images and use them as state representation for reinforcement learning agent. But, any vision only agent is handicapped by not being able to sense audible cues. Using hearing, animals are able to sense targets that are outside of their visual range. In this work, we propose the use of audio as complementary information to visual only in state representation. We assess the impact of such multi-modal setup in reach-the-goal tasks in ViZDoom environment. Results show that the agent improves its behavior when visual information is accompanied with audio features.