 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoSceneGraph: Geometric Scene Graph Diffusion Model for Text-guided 3D Indoor Scene Synthesis
Nov 18, 2025Methods that synthesize indoor 3D scenes from text prompts have wide-ranging applications in film production, interior design, video games, virtual reality, and synthetic data generation for training embodied agents. Existing approaches typically either train generative models from scratch or leverage vision-language models (VLMs). While VLMs achieve strong performance, particularly for complex or open-ended prompts, smaller task-specific models remain necessary for deployment on resource-constrained devices such as extended reality (XR) glasses or mobile phones. However, many generative approaches that train from scratch overlook the inherent graph structure of indoor scenes, which can limit scene coherence and realism. Conversely, methods that incorporate scene graphs either demand a user-provided semantic graph, which is generally inconvenient and restrictive, or rely on ground-truth relationship annotations, limiting their capacity to capture more varied object interactions. To address these challenges, we introduce GeoSceneGraph, a method that synthesizes 3D scenes from text prompts by leveraging the graph structure and geometric symmetries of 3D scenes, without relying on predefined relationship classes. Despite not using ground-truth relationships, GeoSceneGraph achieves performance comparable to methods that do. Our model is built on equivariant graph neural networks (EGNNs), but existing EGNN approaches are typically limited to low-dimensional conditioning and are not designed to handle complex modalities such as text. We propose a simple and effective strategy for conditioning EGNNs on text features, and we validate our design through ablation studies.
GRIM: Task-Oriented Grasping with Conditioning on Generative Examples
Jun 18, 2025Task-Oriented Grasping (TOG) presents a significant challenge, requiring a nuanced understanding of task semantics, object affordances, and the functional constraints dictating how an object should be grasped for a specific task. To address these challenges, we introduce GRIM (Grasp Re-alignment via Iterative Matching), a novel training-free framework for task-oriented grasping. Initially, a coarse alignment strategy is developed using a combination of geometric cues and principal component analysis (PCA)-reduced DINO features for similarity scoring. Subsequently, the full grasp pose associated with the retrieved memory instance is transferred to the aligned scene object and further refined against a set of task-agnostic, geometrically stable grasps generated for the scene object, prioritizing task compatibility. In contrast to existing learning-based methods, GRIM demonstrates strong generalization capabilities, achieving robust performance with only a small number of conditioning examples.
Digital Twin Generation from Visual Data: A Survey
Apr 17, 2025This survey explores recent developments in generating digital twins from videos. Such digital twins can be used for robotics application, media content creation, or design and construction works. We analyze various approaches, including 3D Gaussian Splatting, generative in-painting, semantic segmentation, and foundation models highlighting their advantages and limitations. Additionally, we discuss challenges such as occlusions, lighting variations, and scalability, as well as potential future research directions. This survey aims to provide a comprehensive overview of state-of-the-art methodologies and their implications for real-world applications. Awesome list: https://github.com/ndrwmlnk/awesome-digital-twins
STEVE-Audio: Expanding the Goal Conditioning Modalities of Embodied Agents in Minecraft
Dec 01, 2024



Recently, the STEVE-1 approach has been introduced as a method for training generative agents to follow instructions in the form of latent CLIP embeddings. In this work, we present a methodology to extend the control modalities by learning a mapping from new input modalities to the latent goal space of the agent. We apply our approach to the challenging Minecraft domain, and extend the goal conditioning to include the audio modality. The resulting audio-conditioned agent is able to perform on a comparable level to the original text-conditioned and visual-conditioned agents. Specifically, we create an Audio-Video CLIP foundation model for Minecraft and an audio prior network which together map audio samples to the latent goal space of the STEVE-1 policy. Additionally, we highlight the tradeoffs that occur when conditioning on different modalities. Our training code, evaluation code, and Audio-Video CLIP foundation model for Minecraft are made open-source to help foster further research into multi-modal generalist sequential decision-making agents.
SplatR : Experience Goal Visual Rearrangement with 3D Gaussian Splatting and Dense Feature Matching
Nov 21, 2024



Experience Goal Visual Rearrangement task stands as a foundational challenge within Embodied AI, requiring an agent to construct a robust world model that accurately captures the goal state. The agent uses this world model to restore a shuffled scene to its original configuration, making an accurate representation of the world essential for successfully completing the task. In this work, we present a novel framework that leverages on 3D Gaussian Splatting as a 3D scene representation for experience goal visual rearrangement task. Recent advances in volumetric scene representation like 3D Gaussian Splatting, offer fast rendering of high quality and photo-realistic novel views. Our approach enables the agent to have consistent views of the current and the goal setting of the rearrangement task, which enables the agent to directly compare the goal state and the shuffled state of the world in image space. To compare these views, we propose to use a dense feature matching method with visual features extracted from a foundation model, leveraging its advantages of a more universal feature representation, which facilitates robustness, and generalization. We validate our approach on the AI2-THOR rearrangement challenge benchmark and demonstrate improvements over the current state of the art methods
Object and Contact Point Tracking in Demonstrations Using 3D Gaussian Splatting
Nov 05, 2024This paper introduces a method to enhance Interactive Imitation Learning (IIL) by extracting touch interaction points and tracking object movement from video demonstrations. The approach extends current IIL systems by providing robots with detailed knowledge of both where and how to interact with objects, particularly complex articulated ones like doors and drawers. By leveraging cutting-edge techniques such as 3D Gaussian Splatting and FoundationPose for tracking, this method allows robots to better understand and manipulate objects in dynamic environments. The research lays the foundation for more effective task learning and execution in autonomous robotic systems.
Towards Open-World Mobile Manipulation in Homes: Lessons from the Neurips 2023 HomeRobot Open Vocabulary Mobile Manipulation Challenge
Jul 09, 2024



In order to develop robots that can effectively serve as versatile and capable home assistants, it is crucial for them to reliably perceive and interact with a wide variety of objects across diverse environments. To this end, we proposed Open Vocabulary Mobile Manipulation as a key benchmark task for robotics: finding any object in a novel environment and placing it on any receptacle surface within that environment. We organized a NeurIPS 2023 competition featuring both simulation and real-world components to evaluate solutions to this task. Our baselines on the most challenging version of this task, using real perception in simulation, achieved only an 0.8% success rate; by the end of the competition, the best participants achieved an 10.8\% success rate, a 13x improvement. We observed that the most successful teams employed a variety of methods, yet two common threads emerged among the best solutions: enhancing error detection and recovery, and improving the integration of perception with decision-making processes. In this paper, we detail the results and methodologies used, both in simulation and real-world settings. We discuss the lessons learned and their implications for future research. Additionally, we compare performance in real and simulated environments, emphasizing the necessity for robust generalization to novel settings.
Video Diffusion Models: A Survey
May 06, 2024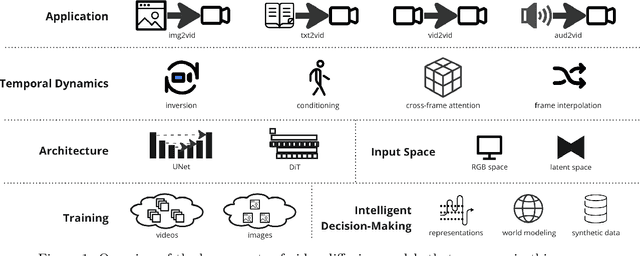
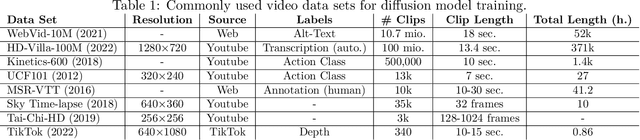
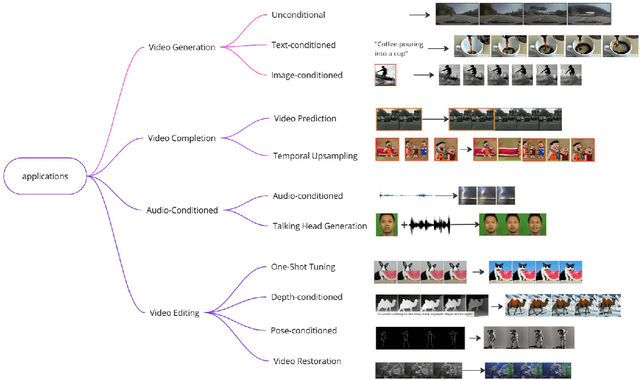

Diffusion generative models have recently become a robust technique for producing and modifying coherent, high-quality video. This survey offers a systematic overview of critical elements of diffusion models for video generation, covering applications, architectural choices, and the modeling of temporal dynamics. Recent advancements in the field are summarized and grouped into development trends. The survey concludes with an overview of remaining challenges and an outlook on the future of the field. Website: https://github.com/ndrwmlnk/Awesome-Video-Diffusion-Models
Lane Segmentation Refinement with Diffusion Models
May 01, 2024



The lane graph is a key component for building high-definition (HD) maps and crucial for downstream tasks such as autonomous driving or navigation planning. Previously, He et al. (2022) explored the extraction of the lane-level graph from aerial imagery utilizing a segmentation based approach. However, segmentation networks struggle to achieve perfect segmentation masks resulting in inaccurate lane graph extraction. We explore additional enhancements to refine this segmentation-based approach and extend it with a diffusion probabilistic model (DPM) component. This combination further improves the GEO F1 and TOPO F1 scores, which are crucial indicators of the quality of a lane graph, in the undirected graph in non-intersection areas. We conduct experiments on a publicly available dataset, demonstrating that our method outperforms the previous approach, particularly in enhancing the connectivity of such a graph, as measured by the TOPO F1 score. Moreover, we perform ablation studies on the individual components of our method to understand their contribution and evaluate their effectiveness.
Exploring Unseen Environments with Robots using Large Language and Vision Models through a Procedurally Generated 3D Scene Representation
Mar 30, 2024



Recent advancements in Generative Artificial Intelligence, particularly in the realm of Large Language Models (LLMs) and Large Vision Language Models (LVLMs), have enabled the prospect of leveraging cognitive planners within robotic systems. This work focuses on solving the object goal navigation problem by mimicking human cognition to attend, perceive and store task specific information and generate plans with the same. We introduce a comprehensive framework capable of exploring an unfamiliar environment in search of an object by leveraging the capabilities of Large Language Models(LLMs) and Large Vision Language Models (LVLMs) in understanding the underlying semantics of our world. A challenging task in using LLMs to generate high level sub-goals is to efficiently represent the environment around the robot. We propose to use a 3D scene modular representation, with semantically rich descriptions of the object, to provide the LLM with task relevant information. But providing the LLM with a mass of contextual information (rich 3D scene semantic representation), can lead to redundant and inefficient plans. We propose to use an LLM based pruner that leverages the capabilities of in-context learning to prune out irrelevant goal specific information.