 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Versatile Humanoid Manipulation with Touch Dreaming
Apr 14, 2026Humanoid robots promise general-purpose assistance, yet real-world humanoid loco-manipulation remains challenging because it requires whole-body stability, dexterous hands, and contact-aware perception under frequent contact changes. In this work, we study dexterous, contact-rich humanoid loco-manipulation. We first develop an RL-based whole-body controller that provides stable lower-body and torso execution during complex manipulation. Built on this controller, we develop a whole-body humanoid data collection system that combines VR-based teleoperation with human-to-humanoid motion mapping, enabling efficient collection of real-world demonstrations. We then propose Humanoid Transformer with Touch Dreaming (HTD), a multimodal encoder--decoder Transformer that models touch as a core modality alongside multi-view vision and proprioception. HTD is trained in a single stage with behavioral cloning augmented by touch dreaming: in addition to predicting action chunks, the policy predicts future hand-joint forces and future tactile latents, encouraging the shared Transformer trunk to learn contact-aware representations for dexterous interaction. Across five contact-rich tasks, Insert-T, Book Organization, Towel Folding, Cat Litter Scooping, and Tea Serving, HTD achieves a 90.9% relative improvement in average success rate over the stronger baseline. Ablation results further show that latent-space tactile prediction is more effective than raw tactile prediction, yielding a 30% relative gain in success rate. These results demonstrate that combining robust whole-body execution, scalable humanoid data collection, and predictive touch-centered learning enables versatile, high-dexterity humanoid manipulation in the real world. Project webpage: humanoid-touch-dream.github.io.
SOFTMAP: Sim2Real Soft Robot Forward Modeling via Topological Mesh Alignment and Physics Prior
Mar 19, 2026While soft robot manipulators offer compelling advantages over rigid counterparts, including inherent compliance, safe human-robot interaction, and the ability to conform to complex geometries, accurate forward modeling from low-dimensional actuation commands remains an open challenge due to nonlinear material phenomena such as hysteresis and manufacturing variability. We present SOFTMAP, a sim-to-real learning framework for real-time 3D forward modeling of tendon-actuated soft finger manipulators. SOFTMAP combines four components: (1) As-Rigid-As-Possible (ARAP)-based topological alignment that projects simulated and real point clouds into a shared, topologically consistent vertex space; (2) a lightweight MLP forward model pretrained on simulation data to map servo commands to full 3D finger geometry; (3) a residual correction network trained on a small set of real observations to predict per-vertex displacement fields that compensate for sim-to-real discrepancies; and (4) a closed-form linear actuation calibration layer enabling real-time inference at 30 FPS. We evaluate SOFTMAP on both simulated and physical hardware, achieving state-of-the-art shape prediction accuracy with a Chamfer distance of 0.389 mm in simulation and 3.786 mm on hardware, millimeter-level fingertip trajectory tracking across multiple target paths, and a 36.5% improvement in teleoperation task success over the baseline. Our results show that SOFTMAP provides a data-efficient approach for 3D forward modeling and control of soft manipulators.
APEX: Learning Adaptive High-Platform Traversal for Humanoid Robots
Feb 11, 2026Humanoid locomotion has advanced rapidly with deep reinforcement learning (DRL), enabling robust feet-based traversal over uneven terrain. Yet platforms beyond leg length remain largely out of reach because current RL training paradigms often converge to jumping-like solutions that are high-impact, torque-limited, and unsafe for real-world deployment. To address this gap, we propose APEX, a system for perceptive, climbing-based high-platform traversal that composes terrain-conditioned behaviors: climb-up and climb-down at vertical edges, walking or crawling on the platform, and stand-up and lie-down for posture reconfiguration. Central to our approach is a generalized ratchet progress reward for learning contact-rich, goal-reaching maneuvers. It tracks the best-so-far task progress and penalizes non-improving steps, providing dense yet velocity-free supervision that enables efficient exploration under strong safety regularization. Based on this formulation, we train LiDAR-based full-body maneuver policies and reduce the sim-to-real perception gap through a dual strategy: modeling mapping artifacts during training and applying filtering and inpainting to elevation maps during deployment. Finally, we distill all six skills into a single policy that autonomously selects behaviors and transitions based on local geometry and commands. Experiments on a 29-DoF Unitree G1 humanoid demonstrate zero-shot sim-to-real traversal of 0.8 meter platforms (approximately 114% of leg length), with robust adaptation to platform height and initial pose, as well as smooth and stable multi-skill transitions.
LightTact: A Visual-Tactile Fingertip Sensor for Deformation-Independent Contact Sensing
Dec 23, 2025Contact often occurs without macroscopic surface deformation, such as during interaction with liquids, semi-liquids, or ultra-soft materials. Most existing tactile sensors rely on deformation to infer contact, making such light-contact interactions difficult to perceive robustly. To address this, we present LightTact, a visual-tactile fingertip sensor that makes contact directly visible via a deformation-independent, optics-based principle. LightTact uses an ambient-blocking optical configuration that suppresses both external light and internal illumination at non-contact regions, while transmitting only the diffuse light generated at true contacts. As a result, LightTact produces high-contrast raw images in which non-contact pixels remain near-black (mean gray value < 3) and contact pixels preserve the natural appearance of the contacting surface. Built on this, LightTact achieves accurate pixel-level contact segmentation that is robust to material properties, contact force, surface appearance, and environmental lighting. We further integrate LightTact on a robotic arm and demonstrate manipulation behaviors driven by extremely light contact, including water spreading, facial-cream dipping, and thin-film interaction. Finally, we show that LightTact's spatially aligned visual-tactile images can be directly interpreted by existing vision-language models, enabling resistor value reasoning for robotic sorting.
LongComp: Long-Tail Compositional Zero-Shot Generalization for Robust Trajectory Prediction
Nov 13, 2025Methods for trajectory prediction in Autonomous Driving must contend with rare, safety-critical scenarios that make reliance on real-world data collection alone infeasible. To assess robustness under such conditions, we propose new long-tail evaluation settings that repartition datasets to create challenging out-of-distribution (OOD) test sets. We first introduce a safety-informed scenario factorization framework, which disentangles scenarios into discrete ego and social contexts. Building on analogies to compositional zero-shot image-labeling in Computer Vision, we then hold out novel context combinations to construct challenging closed-world and open-world settings. This process induces OOD performance gaps in future motion prediction of 5.0% and 14.7% in closed-world and open-world settings, respectively, relative to in-distribution performance for a state-of-the-art baseline. To improve generalization, we extend task-modular gating networks to operate within trajectory prediction models, and develop an auxiliary, difficulty-prediction head to refine internal representations. Our strategies jointly reduce the OOD performance gaps to 2.8% and 11.5% in the two settings, respectively, while still improving in-distribution performance.
STRIVE: Structured Representation Integrating VLM Reasoning for Efficient Object Navigation
May 10, 2025



Vision-Language Models (VLMs) have been increasingly integrated into object navigation tasks for their rich prior knowledge and strong reasoning abilities. However, applying VLMs to navigation poses two key challenges: effectively representing complex environment information and determining \textit{when and how} to query VLMs. Insufficient environment understanding and over-reliance on VLMs (e.g. querying at every step) can lead to unnecessary backtracking and reduced navigation efficiency, especially in continuous environments. To address these challenges, we propose a novel framework that constructs a multi-layer representation of the environment during navigation. This representation consists of viewpoint, object nodes, and room nodes. Viewpoints and object nodes facilitate intra-room exploration and accurate target localization, while room nodes support efficient inter-room planning. Building on this representation, we propose a novel two-stage navigation policy, integrating high-level planning guided by VLM reasoning with low-level VLM-assisted exploration to efficiently locate a goal object. We evaluated our approach on three simulated benchmarks (HM3D, RoboTHOR, and MP3D), and achieved state-of-the-art performance on both the success rate ($\mathord{\uparrow}\, 7.1\%$) and navigation efficiency ($\mathord{\uparrow}\, 12.5\%$). We further validate our method on a real robot platform, demonstrating strong robustness across 15 object navigation tasks in 10 different indoor environments. Project page is available at https://zwandering.github.io/STRIVE.github.io/ .
MOSAIC: Generating Consistent, Privacy-Preserving Scenes from Multiple Depth Views in Multi-Room Environments
Mar 18, 2025We introduce a novel diffusion-based approach for generating privacy-preserving digital twins of multi-room indoor environments from depth images only. Central to our approach is a novel Multi-view Overlapped Scene Alignment with Implicit Consistency (MOSAIC) model that explicitly considers cross-view dependencies within the same scene in the probabilistic sense. MOSAIC operates through a novel inference-time optimization that avoids error accumulation common in sequential or single-room constraint in panorama-based approaches. MOSAIC scales to complex scenes with zero extra training and provably reduces the variance during denoising processes when more overlapping views are added, leading to improved generation quality. Experiments show that MOSAIC outperforms state-of-the-art baselines on image fidelity metrics in reconstructing complex multi-room environments. Project page is available at: https://mosaic-cmubig.github.io
KineSoft: Learning Proprioceptive Manipulation Policies with Soft Robot Hands
Mar 03, 2025
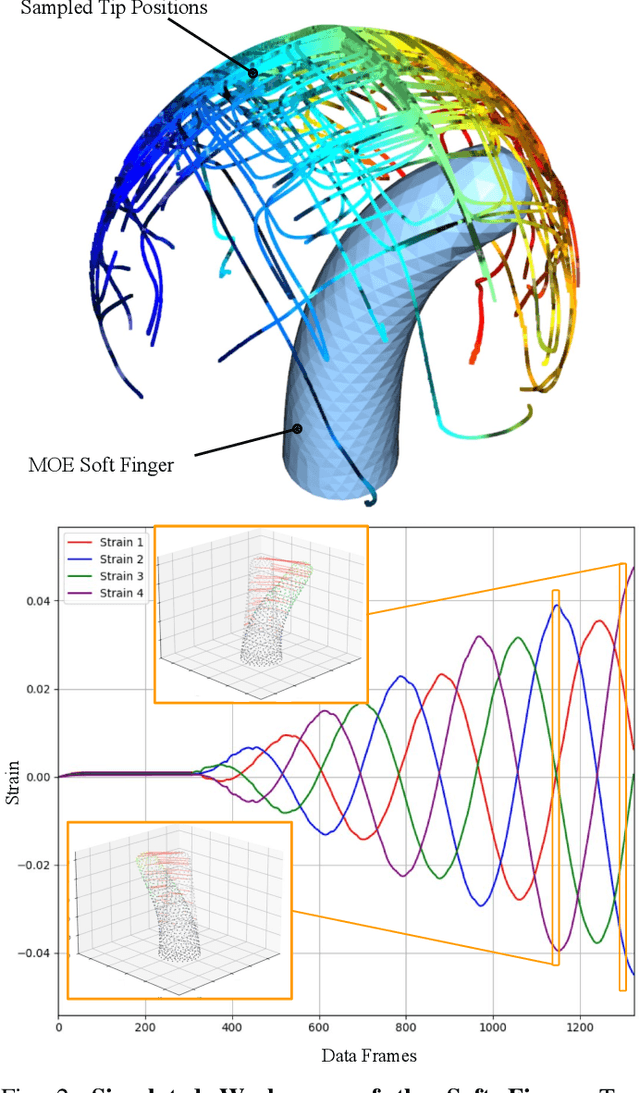
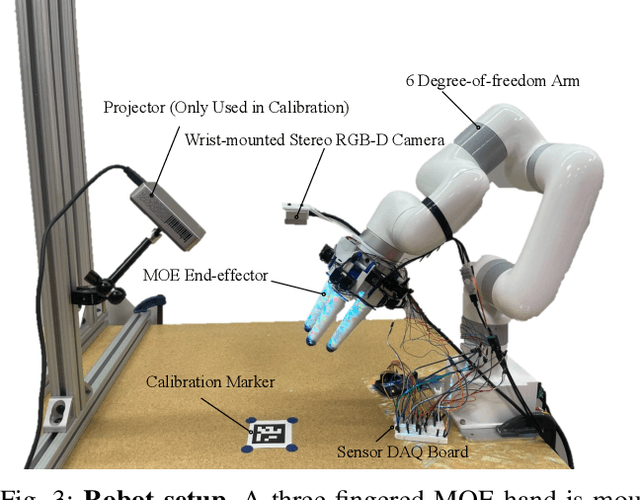
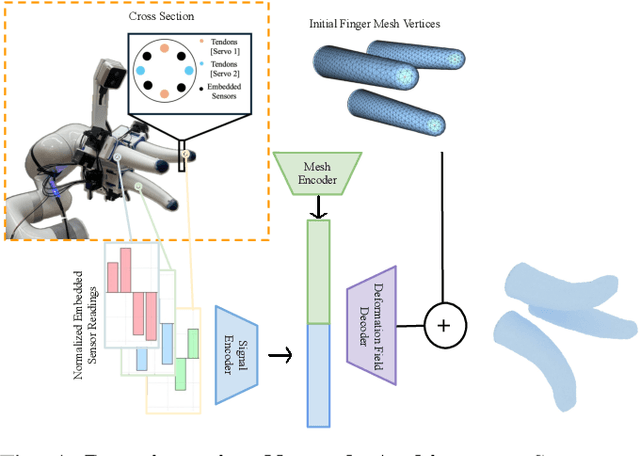
Underactuated soft robot hands offer inherent safety and adaptability advantages over rigid systems, but developing dexterous manipulation skills remains challenging. While imitation learning shows promise for complex manipulation tasks, traditional approaches struggle with soft systems due to demonstration collection challenges and ineffective state representations. We present KineSoft, a framework enabling direct kinesthetic teaching of soft robotic hands by leveraging their natural compliance as a skill teaching advantage rather than only as a control challenge. KineSoft makes two key contributions: (1) an internal strain sensing array providing occlusion-free proprioceptive shape estimation, and (2) a shape-based imitation learning framework that uses proprioceptive feedback with a low-level shape-conditioned controller to ground diffusion-based policies. This enables human demonstrators to physically guide the robot while the system learns to associate proprioceptive patterns with successful manipulation strategies. We validate KineSoft through physical experiments, demonstrating superior shape estimation accuracy compared to baseline methods, precise shape-trajectory tracking, and higher task success rates compared to baseline imitation learning approaches.
Your Learned Constraint is Secretly a Backward Reachable Tube
Jan 26, 2025Inverse Constraint Learning (ICL) is the problem of inferring constraints from safe (i.e., constraint-satisfying) demonstrations. The hope is that these inferred constraints can then be used downstream to search for safe policies for new tasks and, potentially, under different dynamics. Our paper explores the question of what mathematical entity ICL recovers. Somewhat surprisingly, we show that both in theory and in practice, ICL recovers the set of states where failure is inevitable, rather than the set of states where failure has already happened. In the language of safe control, this means we recover a backwards reachable tube (BRT) rather than a failure set. In contrast to the failure set, the BRT depends on the dynamics of the data collection system. We discuss the implications of the dynamics-conditionedness of the recovered constraint on both the sample-efficiency of policy search and the transferability of learned constraints.
STRAP: Robot Sub-Trajectory Retrieval for Augmented Policy Learning
Dec 19, 2024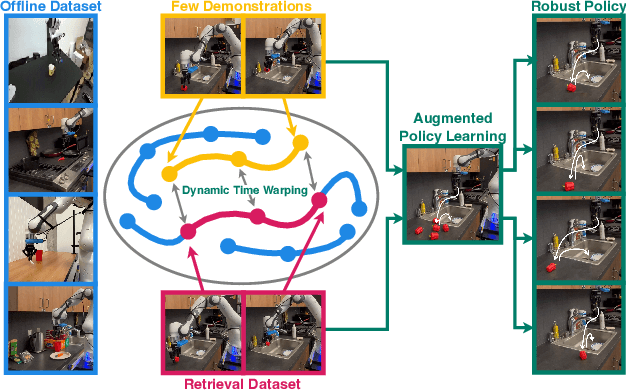
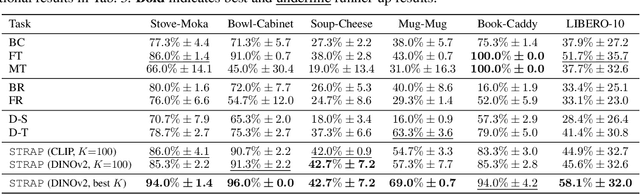
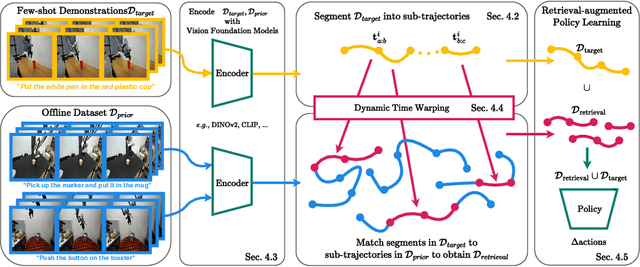
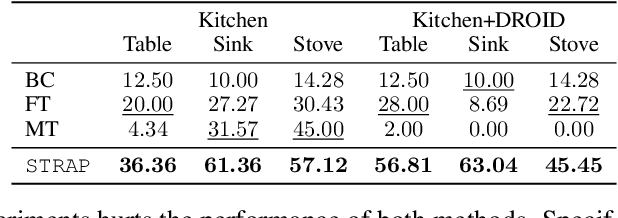
Robot learning is witnessing a significant increase in the size, diversity, and complexity of pre-collected datasets, mirroring trends in domains such as natural language processing and computer vision. Many robot learning methods treat such datasets as multi-task expert data and learn a multi-task, generalist policy by training broadly across them. Notably, while these generalist policies can improve the average performance across many tasks, the performance of generalist policies on any one task is often suboptimal due to negative transfer between partitions of the data, compared to task-specific specialist policies. In this work, we argue for the paradigm of training policies during deployment given the scenarios they encounter: rather than deploying pre-trained policies to unseen problems in a zero-shot manner, we non-parametrically retrieve and train models directly on relevant data at test time. Furthermore, we show that many robotics tasks share considerable amounts of low-level behaviors and that retrieval at the "sub"-trajectory granularity enables significantly improved data utilization, generalization, and robustness in adapting policies to novel problems. In contrast, existing full-trajectory retrieval methods tend to underutilize the data and miss out on shared cross-task content. This work proposes STRAP, a technique for leveraging pre-trained vision foundation models and dynamic time warping to retrieve sub-sequences of trajectories from large training corpora in a robust fashion. STRAP outperforms both prior retrieval algorithms and multi-task learning methods in simulated and real experiments, showing the ability to scale to much larger offline datasets in the real world as well as the ability to learn robust control policies with just a handful of real-world demonstrations.