 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEAL: Towards Safe Autonomous Driving via Skill-Enabled Adversary Learning for Closed-Loop Scenario Generation
Sep 16, 2024



Verification and validation of autonomous driving (AD) systems and components is of increasing importance, as such technology increases in real-world prevalence. Safety-critical scenario generation is a key approach to robustify AD policies through closed-loop training. However, existing approaches for scenario generation rely on simplistic objectives, resulting in overly-aggressive or non-reactive adversarial behaviors. To generate diverse adversarial yet realistic scenarios, we propose SEAL, a scenario perturbation approach which leverages learned scoring functions and adversarial, human-like skills. SEAL-perturbed scenarios are more realistic than SOTA baselines, leading to improved ego task success across real-world, in-distribution, and out-of-distribution scenarios, of more than 20%. To facilitate future research, we release our code and tools: https://github.com/cmubig/SEAL
Amelia: A Large Model and Dataset for Airport Surface Movement Forecasting
Jul 30, 2024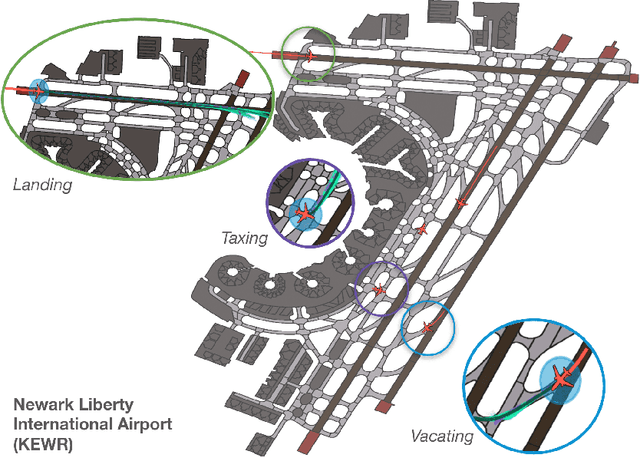

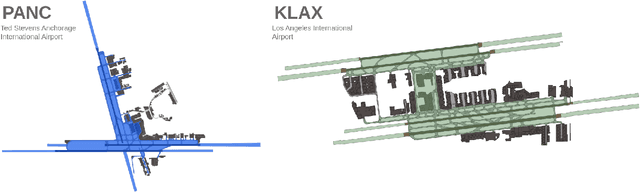
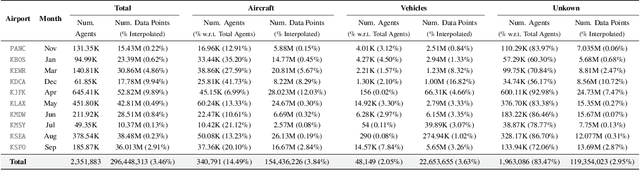
The growing demand for air travel requires technological advancements in air traffic management as well as mechanisms for monitoring and ensuring safe and efficient operations. In terminal airspaces, predictive models of future movements and traffic flows can help with proactive planning and efficient coordination; however, varying airport topologies, and interactions with other agents, among other factors, make accurate predictions challenging. Data-driven predictive models have shown promise for handling numerous variables to enable various downstream tasks, including collision risk assessment, taxi-out time prediction, departure metering, and emission estimations. While data-driven methods have shown improvements in these tasks, prior works lack large-scale curated surface movement datasets within the public domain and the development of generalizable trajectory forecasting models. In response to this, we propose two contributions: (1) Amelia-48, a large surface movement dataset collected using the System Wide Information Management (SWIM) Surface Movement Event Service (SMES). With data collection beginning in Dec 2022, the dataset provides more than a year's worth of SMES data (~30TB) and covers 48 airports within the US National Airspace System. In addition to releasing this data in the public domain, we also provide post-processing scripts and associated airport maps to enable research in the forecasting domain and beyond. (2) Amelia-TF model, a transformer-based next-token-prediction large multi-agent multi-airport trajectory forecasting model trained on 292 days or 9.4 billion tokens of position data encompassing 10 different airports with varying topology. The open-sourced model is validated on unseen airports with experiments showcasing the different prediction horizon lengths, ego-agent selection strategies, and training recipes to demonstrate the generalization capabilities.
SoRTS: Learned Tree Search for Long Horizon Social Robot Navigation
Sep 22, 2023



The fast-growing demand for fully autonomous robots in shared spaces calls for the development of trustworthy agents that can safely and seamlessly navigate in crowded environments. Recent models for motion prediction show promise in characterizing social interactions in such environments. Still, adapting them for navigation is challenging as they often suffer from generalization failures. Prompted by this, we propose Social Robot Tree Search (SoRTS), an algorithm for safe robot navigation in social domains. SoRTS aims to augment existing socially aware motion prediction models for long-horizon navigation using Monte Carlo Tree Search. We use social navigation in general aviation as a case study to evaluate our approach and further the research in full-scale aerial autonomy. In doing so, we introduce XPlaneROS, a high-fidelity aerial simulator that enables human-robot interaction. We use XPlaneROS to conduct a first-of-its-kind user study where 26 FAA-certified pilots interact with a human pilot, our algorithm, and its ablation. Our results, supported by statistical evidence, show that SoRTS exhibits a comparable performance to competent human pilots, significantly outperforming its ablation. Finally, we complement these results with a broad set of self-play experiments to showcase our algorithm's performance in scenarios with increasing complexity.
SafeShift: Safety-Informed Distribution Shifts for Robust Trajectory Prediction in Autonomous Driving
Sep 16, 2023As autonomous driving technology matures, safety and robustness of its key components, including trajectory prediction, is vital. Though real-world datasets, such as Waymo Open Motion, provide realistic recorded scenarios for model development, they often lack truly safety-critical situations. Rather than utilizing unrealistic simulation or dangerous real-world testing, we instead propose a framework to characterize such datasets and find hidden safety-relevant scenarios within. Our approach expands the spectrum of safety-relevance, allowing us to study trajectory prediction models under a safety-informed, distribution shift setting. We contribute a generalized scenario characterization method, a novel scoring scheme to find subtly-avoided risky scenarios, and an evaluation of trajectory prediction models in this setting. We further contribute a remediation strategy, achieving a 10% average reduction in prediction collision rates. To facilitate future research, we release our code to the public: github.com/cmubig/SafeShift
Core Challenges in Embodied Vision-Language Planning
Apr 05, 2023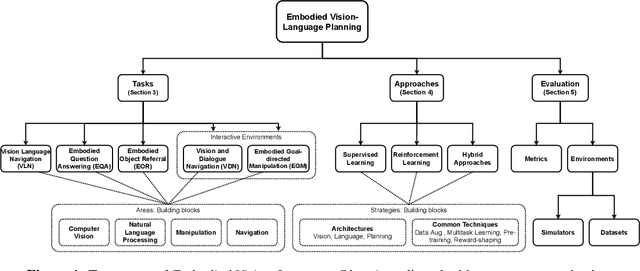
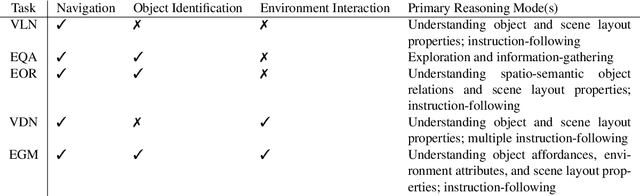
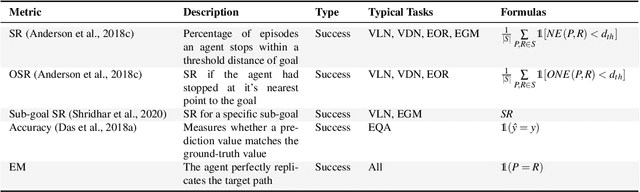

Recent advances in the areas of Multimodal Machine Learning and Artificial Intelligence (AI) have led to the development of challenging tasks at the intersection of Computer Vision, Natural Language Processing, and Robotics. Whereas many approaches and previous survey pursuits have characterised one or two of these dimensions, there has not been a holistic analysis at the center of all three. Moreover, even when combinations of these topics are considered, more focus is placed on describing, e.g., current architectural methods, as opposed to also illustrating high-level challenges and opportunities for the field. In this survey paper, we discuss Embodied Vision-Language Planning (EVLP) tasks, a family of prominent embodied navigation and manipulation problems that jointly leverage computer vision and natural language for interaction in physical environments. We propose a taxonomy to unify these tasks and provide an in-depth analysis and comparison of the current and new algorithmic approaches, metrics, simulators, and datasets used for EVLP tasks. Finally, we present the core challenges that we believe new EVLP works should seek to address, and we advocate for task construction that enables model generalisability and furthers real-world deployment.
Learned Tree Search for Long-Horizon Social Robot Navigation in Shared Airspace
Apr 04, 2023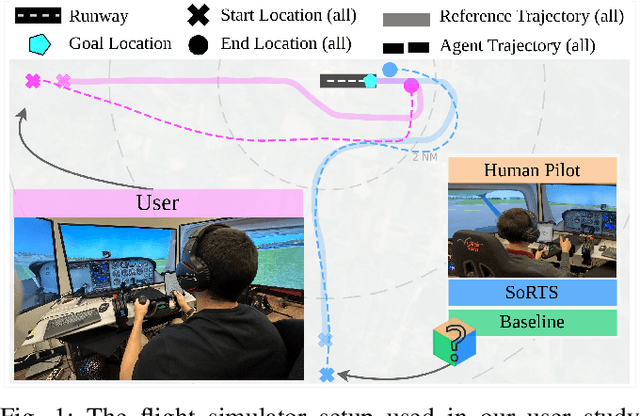
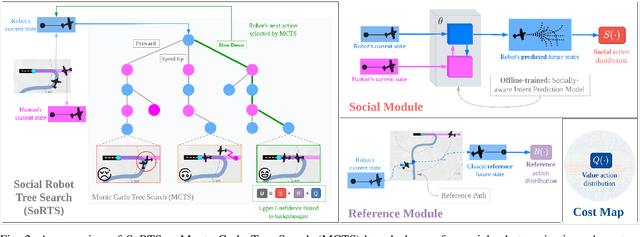
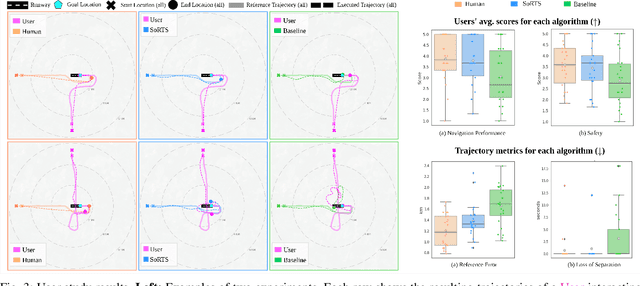
The fast-growing demand for fully autonomous aerial operations in shared spaces necessitates developing trustworthy agents that can safely and seamlessly navigate in crowded, dynamic spaces. In this work, we propose Social Robot Tree Search (SoRTS), an algorithm for the safe navigation of mobile robots in social domains. SoRTS aims to augment existing socially-aware trajectory prediction policies with a Monte Carlo Tree Search planner for improved downstream navigation of mobile robots. To evaluate the performance of our method, we choose the use case of social navigation for general aviation. To aid this evaluation, within this work, we also introduce X-PlaneROS, a high-fidelity aerial simulator, to enable more research in full-scale aerial autonomy. By conducting a user study based on the assessments of 26 FAA certified pilots, we show that SoRTS performs comparably to a competent human pilot, significantly outperforming our baseline algorithm. We further complement these results with self-play experiments in scenarios with increasing complexity.
Knowledge-driven Scene Priors for Semantic Audio-Visual Embodied Navigation
Dec 21, 2022



Generalisation to unseen contexts remains a challenge for embodied navigation agents. In the context of semantic audio-visual navigation (SAVi) tasks, the notion of generalisation should include both generalising to unseen indoor visual scenes as well as generalising to unheard sounding objects. However, previous SAVi task definitions do not include evaluation conditions on truly novel sounding objects, resorting instead to evaluating agents on unheard sound clips of known objects; meanwhile, previous SAVi methods do not include explicit mechanisms for incorporating domain knowledge about object and region semantics. These weaknesses limit the development and assessment of models' abilities to generalise their learned experience. In this work, we introduce the use of knowledge-driven scene priors in the semantic audio-visual embodied navigation task: we combine semantic information from our novel knowledge graph that encodes object-region relations, spatial knowledge from dual Graph Encoder Networks, and background knowledge from a series of pre-training tasks -- all within a reinforcement learning framework for audio-visual navigation. We also define a new audio-visual navigation sub-task, where agents are evaluated on novel sounding objects, as opposed to unheard clips of known objects. We show improvements over strong baselines in generalisation to unseen regions and novel sounding objects, within the Habitat-Matterport3D simulation environment, under the SoundSpaces task.
Challenges in Close-Proximity Safe and Seamless Operation of Manned and Unmanned Aircraft in Shared Airspace
Nov 13, 2022
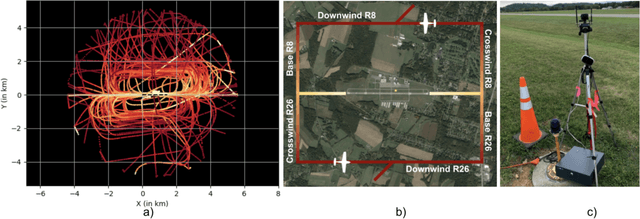


We propose developing an integrated system to keep autonomous unmanned aircraft safely separated and behave as expected in conjunction with manned traffic. The main goal is to achieve safe manned-unmanned vehicle teaming to improve system performance, have each (robot/human) teammate learn from each other in various aircraft operations, and reduce the manning needs of manned aircraft. The proposed system anticipates and reacts to other aircraft using natural language instructions and can serve as a co-pilot or operate entirely autonomously. We point out the main technical challenges where improvements on current state-of-the-art are needed to enable Visual Flight Rules to fully autonomous aerial operations, bringing insights to these critical areas. Furthermore, we present an interactive demonstration in a prototypical scenario with one AI pilot and one human pilot sharing the same terminal airspace, interacting with each other using language, and landing safely on the same runway. We also show a demonstration of a vision-only aircraft detection system.
Social-PatteRNN: Socially-Aware Trajectory Prediction Guided by Motion Patterns
Sep 12, 2022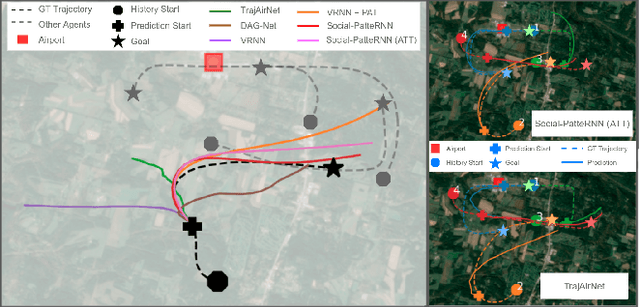
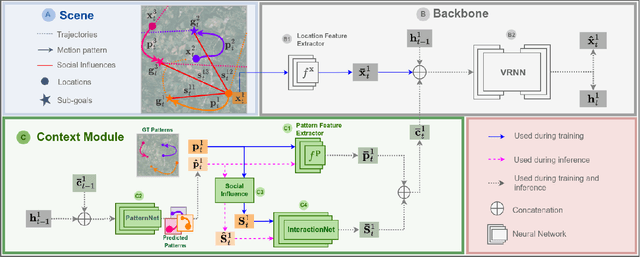

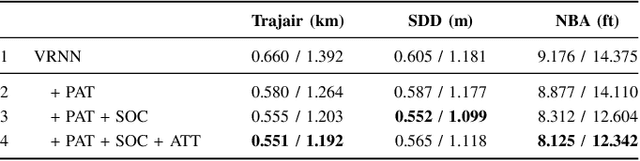
As robots across domains start collaborating with humans in shared environments, algorithms that enable them to reason over human intent are important to achieve safe interplay. In our work, we study human intent through the problem of predicting trajectories in dynamic environments. We explore domains where navigation guidelines are relatively strictly defined but not clearly marked in their physical environments. We hypothesize that within these domains, agents tend to exhibit short-term motion patterns that reveal context information related to the agent's general direction, intermediate goals and rules of motion, e.g., social behavior. From this intuition, we propose Social-PatteRNN, an algorithm for recurrent, multi-modal trajectory prediction that exploits motion patterns to encode the aforesaid contexts. Our approach guides long-term trajectory prediction by learning to predict short-term motion patterns. It then extracts sub-goal information from the patterns and aggregates it as social context. We assess our approach across three domains: humans crowds, humans in sports and manned aircraft in terminal airspace, achieving state-of-the-art performance.