 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Cross-spectral Unsupervised Domain Adaptation for Thermal Semantic Segmentation
May 11, 2025In autonomous driving, thermal image semantic segmentation has emerged as a critical research area, owing to its ability to provide robust scene understanding under adverse visual conditions. In particular, unsupervised domain adaptation (UDA) for thermal image segmentation can be an efficient solution to address the lack of labeled thermal datasets. Nevertheless, since these methods do not effectively utilize the complementary information between RGB and thermal images, they significantly decrease performance during domain adaptation. In this paper, we present a comprehensive study on cross-spectral UDA for thermal image semantic segmentation. We first propose a novel masked mutual learning strategy that promotes complementary information exchange by selectively transferring results between each spectral model while masking out uncertain regions. Additionally, we introduce a novel prototypical self-supervised loss designed to enhance the performance of the thermal segmentation model in nighttime scenarios. This approach addresses the limitations of RGB pre-trained networks, which cannot effectively transfer knowledge under low illumination due to the inherent constraints of RGB sensors. In experiments, our method achieves higher performance over previous UDA methods and comparable performance to state-of-the-art supervised methods.
MOSAIC: Generating Consistent, Privacy-Preserving Scenes from Multiple Depth Views in Multi-Room Environments
Mar 18, 2025We introduce a novel diffusion-based approach for generating privacy-preserving digital twins of multi-room indoor environments from depth images only. Central to our approach is a novel Multi-view Overlapped Scene Alignment with Implicit Consistency (MOSAIC) model that explicitly considers cross-view dependencies within the same scene in the probabilistic sense. MOSAIC operates through a novel inference-time optimization that avoids error accumulation common in sequential or single-room constraint in panorama-based approaches. MOSAIC scales to complex scenes with zero extra training and provably reduces the variance during denoising processes when more overlapping views are added, leading to improved generation quality. Experiments show that MOSAIC outperforms state-of-the-art baselines on image fidelity metrics in reconstructing complex multi-room environments. Project page is available at: https://mosaic-cmubig.github.io
DEEPTalk: Dynamic Emotion Embedding for Probabilistic Speech-Driven 3D Face Animation
Aug 12, 2024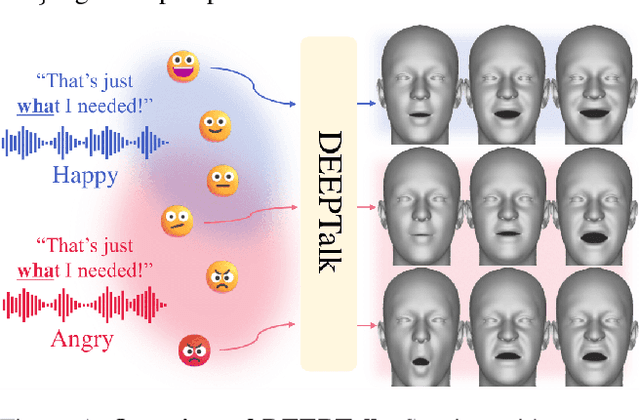

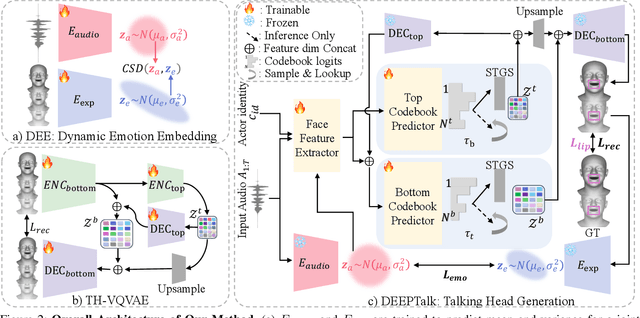
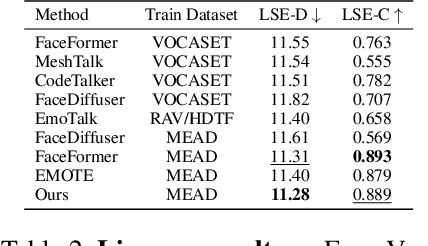
Speech-driven 3D facial animation has garnered lots of attention thanks to its broad range of applications. Despite recent advancements in achieving realistic lip motion, current methods fail to capture the nuanced emotional undertones conveyed through speech and produce monotonous facial motion. These limitations result in blunt and repetitive facial animations, reducing user engagement and hindering their applicability. To address these challenges, we introduce DEEPTalk, a novel approach that generates diverse and emotionally rich 3D facial expressions directly from speech inputs. To achieve this, we first train DEE (Dynamic Emotion Embedding), which employs probabilistic contrastive learning to forge a joint emotion embedding space for both speech and facial motion. This probabilistic framework captures the uncertainty in interpreting emotions from speech and facial motion, enabling the derivation of emotion vectors from its multifaceted space. Moreover, to generate dynamic facial motion, we design TH-VQVAE (Temporally Hierarchical VQ-VAE) as an expressive and robust motion prior overcoming limitations of VAEs and VQ-VAEs. Utilizing these strong priors, we develop DEEPTalk, A talking head generator that non-autoregressively predicts codebook indices to create dynamic facial motion, incorporating a novel emotion consistency loss. Extensive experiments on various datasets demonstrate the effectiveness of our approach in creating diverse, emotionally expressive talking faces that maintain accurate lip-sync. Source code will be made publicly available soon.
SafeShift: Safety-Informed Distribution Shifts for Robust Trajectory Prediction in Autonomous Driving
Sep 16, 2023As autonomous driving technology matures, safety and robustness of its key components, including trajectory prediction, is vital. Though real-world datasets, such as Waymo Open Motion, provide realistic recorded scenarios for model development, they often lack truly safety-critical situations. Rather than utilizing unrealistic simulation or dangerous real-world testing, we instead propose a framework to characterize such datasets and find hidden safety-relevant scenarios within. Our approach expands the spectrum of safety-relevance, allowing us to study trajectory prediction models under a safety-informed, distribution shift setting. We contribute a generalized scenario characterization method, a novel scoring scheme to find subtly-avoided risky scenarios, and an evaluation of trajectory prediction models in this setting. We further contribute a remediation strategy, achieving a 10% average reduction in prediction collision rates. To facilitate future research, we release our code to the public: github.com/cmubig/SafeShift
Instant Domain Augmentation for LiDAR Semantic Segmentation
Mar 25, 2023Despite the increasing popularity of LiDAR sensors, perception algorithms using 3D LiDAR data struggle with the 'sensor-bias problem'. Specifically, the performance of perception algorithms significantly drops when an unseen specification of LiDAR sensor is applied at test time due to the domain discrepancy. This paper presents a fast and flexible LiDAR augmentation method for the semantic segmentation task, called 'LiDomAug'. It aggregates raw LiDAR scans and creates a LiDAR scan of any configurations with the consideration of dynamic distortion and occlusion, resulting in instant domain augmentation. Our on-demand augmentation module runs at 330 FPS, so it can be seamlessly integrated into the data loader in the learning framework. In our experiments, learning-based approaches aided with the proposed LiDomAug are less affected by the sensor-bias issue and achieve new state-of-the-art domain adaptation performances on SemanticKITTI and nuScenes dataset without the use of the target domain data. We also present a sensor-agnostic model that faithfully works on the various LiDAR configurations.
T2FPV: Constructing High-Fidelity First-Person View Datasets From Real-World Pedestrian Trajectories
Sep 22, 2022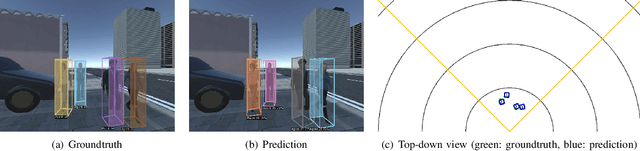
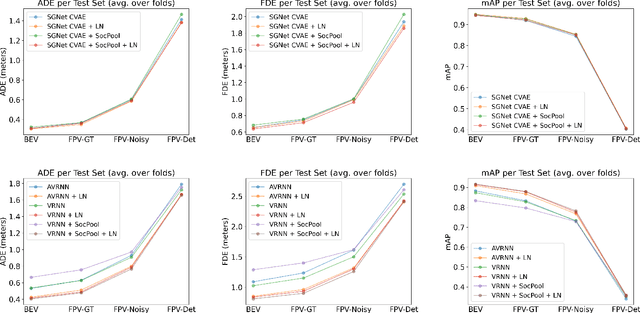
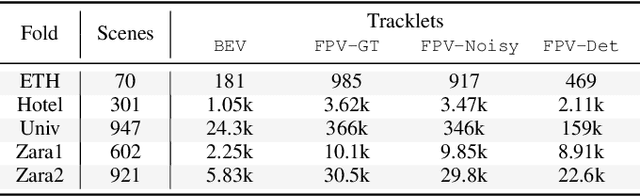
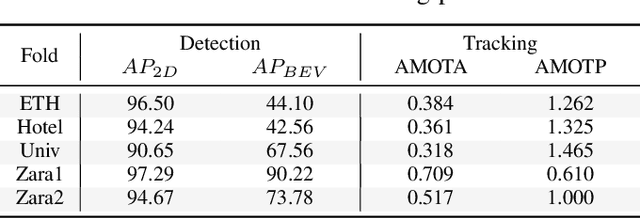
Predicting pedestrian motion is essential for developing socially-aware robots that interact in a crowded environment. While the natural visual perspective for a social interaction setting is an egocentric view, the majority of existing work in trajectory prediction has been investigated purely in the top-down trajectory space. To support first-person view trajectory prediction research, we present T2FPV, a method for constructing high-fidelity first-person view datasets given a real-world, top-down trajectory dataset; we showcase our approach on the ETH/UCY pedestrian dataset to generate the egocentric visual data of all interacting pedestrians. We report that the bird's-eye view assumption used in the original ETH/UCY dataset, i.e., an agent can observe everyone in the scene with perfect information, does not hold in the first-person views; only a fraction of agents are fully visible during each 20-timestep scene used commonly in existing work. We evaluate existing trajectory prediction approaches under varying levels of realistic perception -- displacement errors suffer a 356% increase compared to the top-down, perfect information setting. To promote research in first-person view trajectory prediction, we release our T2FPV-ETH dataset and software tools.
StairNet: Top-Down Semantic Aggregation for Accurate One Shot Detection
Sep 18, 2017

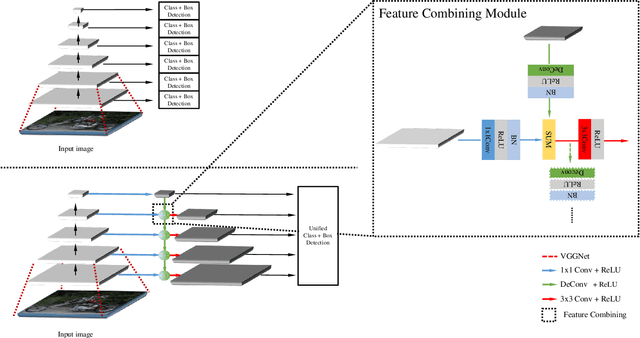

One-stage object detectors such as SSD or YOLO already have shown promising accuracy with small memory footprint and fast speed. However, it is widely recognized that one-stage detectors have difficulty in detecting small objects while they are competitive with two-stage methods on large objects. In this paper, we investigate how to alleviate this problem starting from the SSD framework. Due to their pyramidal design, the lower layer that is responsible for small objects lacks strong semantics(e.g contextual information). We address this problem by introducing a feature combining module that spreads out the strong semantics in a top-down manner. Our final model StairNet detector unifies the multi-scale representations and semantic distribution effectively. Experiments on PASCAL VOC 2007 and PASCAL VOC 2012 datasets demonstrate that StairNet significantly improves the weakness of SSD and outperforms the other state-of-the-art one-stage detectors.