 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePri4R: Learning World Dynamics for Vision-Language-Action Models with Privileged 4D Representation
Mar 02, 2026Humans learn not only how their bodies move, but also how the surrounding world responds to their actions. In contrast, while recent Vision-Language-Action (VLA) models exhibit impressive semantic understanding, they often fail to capture the spatiotemporal dynamics governing physical interaction. In this paper, we introduce Pri4R, a simple yet effective approach that endows VLA models with an implicit understanding of world dynamics by leveraging privileged 4D information during training. Specifically, Pri4R augments VLAs with a lightweight point track head that predicts 3D point tracks. By injecting VLA features into this head to jointly predict future 3D trajectories, the model learns to incorporate evolving scene geometry within its shared representation space, enabling more physically aware context for precise control. Due to its architectural simplicity, Pri4R is compatible with dominant VLA design patterns with minimal changes. During inference, we run the model using the original VLA architecture unchanged; Pri4R adds no extra inputs, outputs, or computational overhead. Across simulation and real-world evaluations, Pri4R significantly improves performance on challenging manipulation tasks, including a +10% gain on LIBERO-Long and a +40% gain on RoboCasa. We further show that 3D point track prediction is an effective supervision target for learning action-world dynamics, and validate our design choices through extensive ablations.
DisCoRD: Discrete Tokens to Continuous Motion via Rectified Flow Decoding
Dec 02, 2024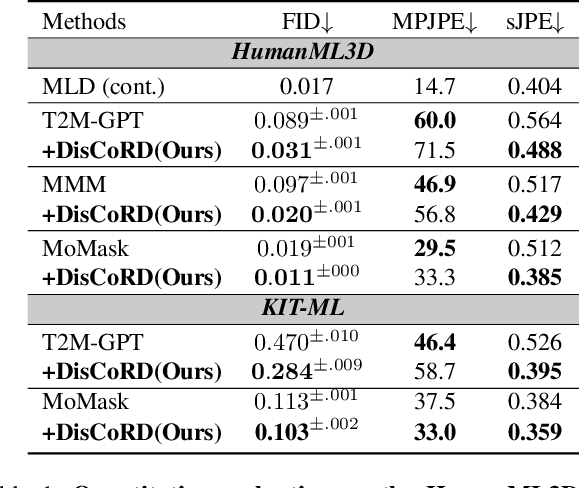
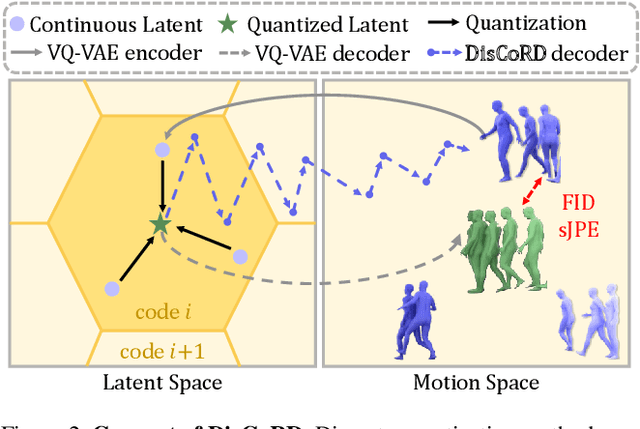
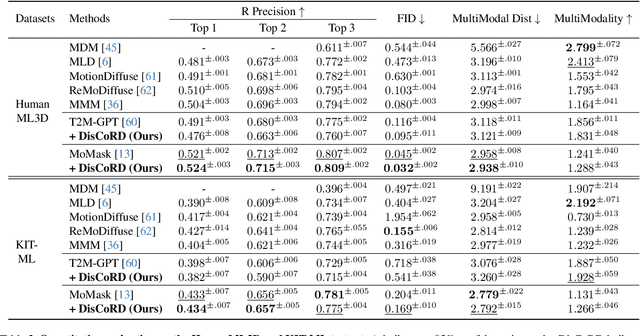
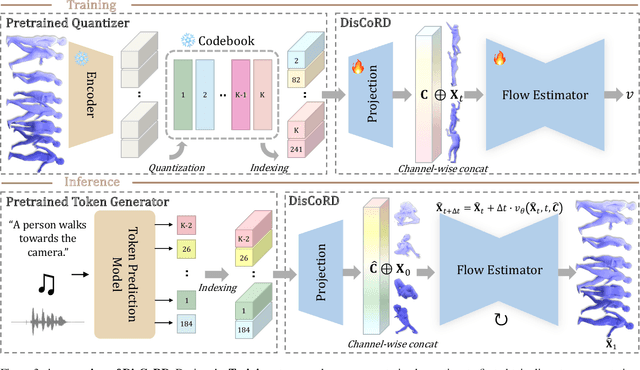
Human motion, inherently continuous and dynamic, presents significant challenges for generative models. Despite their dominance, discrete quantization methods, such as VQ-VAEs, suffer from inherent limitations, including restricted expressiveness and frame-wise noise artifacts. Continuous approaches, while producing smoother and more natural motions, often falter due to high-dimensional complexity and limited training data. To resolve this "discord" between discrete and continuous representations, we introduce DisCoRD: Discrete Tokens to Continuous Motion via Rectified Flow Decoding, a novel method that decodes discrete motion tokens into continuous motion through rectified flow. By employing an iterative refinement process in the continuous space, DisCoRD captures fine-grained dynamics and ensures smoother and more natural motions. Compatible with any discrete-based framework, our method enhances naturalness without compromising faithfulness to the conditioning signals. Extensive evaluations demonstrate that DisCoRD achieves state-of-the-art performance, with FID of 0.032 on HumanML3D and 0.169 on KIT-ML. These results solidify DisCoRD as a robust solution for bridging the divide between discrete efficiency and continuous realism. Our project page is available at: https://whwjdqls.github.io/discord.github.io/.
DEEPTalk: Dynamic Emotion Embedding for Probabilistic Speech-Driven 3D Face Animation
Aug 12, 2024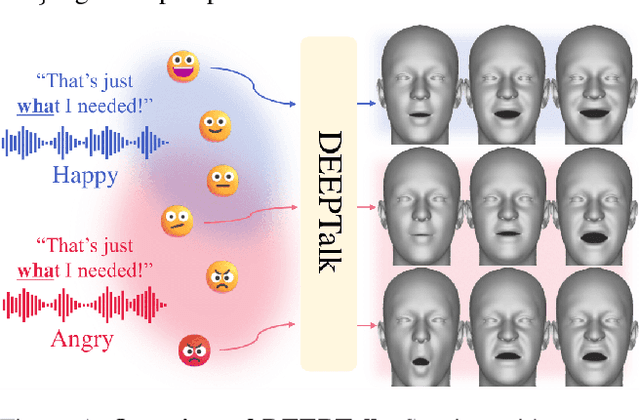

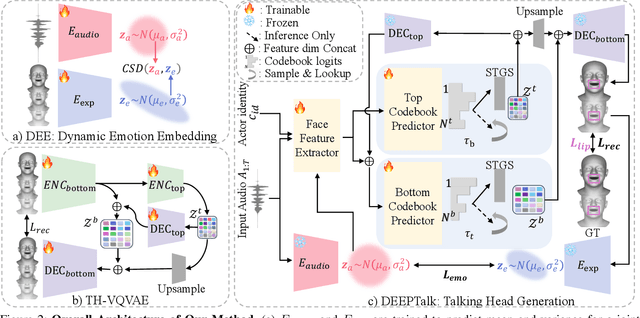
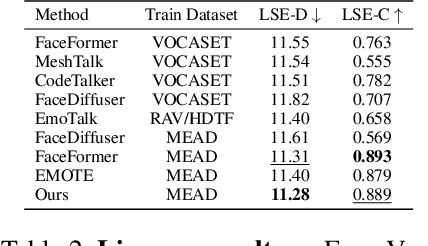
Speech-driven 3D facial animation has garnered lots of attention thanks to its broad range of applications. Despite recent advancements in achieving realistic lip motion, current methods fail to capture the nuanced emotional undertones conveyed through speech and produce monotonous facial motion. These limitations result in blunt and repetitive facial animations, reducing user engagement and hindering their applicability. To address these challenges, we introduce DEEPTalk, a novel approach that generates diverse and emotionally rich 3D facial expressions directly from speech inputs. To achieve this, we first train DEE (Dynamic Emotion Embedding), which employs probabilistic contrastive learning to forge a joint emotion embedding space for both speech and facial motion. This probabilistic framework captures the uncertainty in interpreting emotions from speech and facial motion, enabling the derivation of emotion vectors from its multifaceted space. Moreover, to generate dynamic facial motion, we design TH-VQVAE (Temporally Hierarchical VQ-VAE) as an expressive and robust motion prior overcoming limitations of VAEs and VQ-VAEs. Utilizing these strong priors, we develop DEEPTalk, A talking head generator that non-autoregressively predicts codebook indices to create dynamic facial motion, incorporating a novel emotion consistency loss. Extensive experiments on various datasets demonstrate the effectiveness of our approach in creating diverse, emotionally expressive talking faces that maintain accurate lip-sync. Source code will be made publicly available soon.