 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePri4R: Learning World Dynamics for Vision-Language-Action Models with Privileged 4D Representation
Mar 02, 2026Humans learn not only how their bodies move, but also how the surrounding world responds to their actions. In contrast, while recent Vision-Language-Action (VLA) models exhibit impressive semantic understanding, they often fail to capture the spatiotemporal dynamics governing physical interaction. In this paper, we introduce Pri4R, a simple yet effective approach that endows VLA models with an implicit understanding of world dynamics by leveraging privileged 4D information during training. Specifically, Pri4R augments VLAs with a lightweight point track head that predicts 3D point tracks. By injecting VLA features into this head to jointly predict future 3D trajectories, the model learns to incorporate evolving scene geometry within its shared representation space, enabling more physically aware context for precise control. Due to its architectural simplicity, Pri4R is compatible with dominant VLA design patterns with minimal changes. During inference, we run the model using the original VLA architecture unchanged; Pri4R adds no extra inputs, outputs, or computational overhead. Across simulation and real-world evaluations, Pri4R significantly improves performance on challenging manipulation tasks, including a +10% gain on LIBERO-Long and a +40% gain on RoboCasa. We further show that 3D point track prediction is an effective supervision target for learning action-world dynamics, and validate our design choices through extensive ablations.
ReSpec: Relevance and Specificity Grounded Online Filtering for Learning on Video-Text Data Streams
Apr 21, 2025The rapid growth of video-text data presents challenges in storage and computation during training. Online learning, which processes streaming data in real-time, offers a promising solution to these issues while also allowing swift adaptations in scenarios demanding real-time responsiveness. One strategy to enhance the efficiency and effectiveness of learning involves identifying and prioritizing data that enhances performance on target downstream tasks. We propose Relevance and Specificity-based online filtering framework (ReSpec) that selects data based on four criteria: (i) modality alignment for clean data, (ii) task relevance for target focused data, (iii) specificity for informative and detailed data, and (iv) efficiency for low-latency processing. Relevance is determined by the probabilistic alignment of incoming data with downstream tasks, while specificity employs the distance to a root embedding representing the least specific data as an efficient proxy for informativeness. By establishing reference points from target task data, ReSpec filters incoming data in real-time, eliminating the need for extensive storage and compute. Evaluating on large-scale datasets WebVid2M and VideoCC3M, ReSpec attains state-of-the-art performance on five zeroshot video retrieval tasks, using as little as 5% of the data while incurring minimal compute. The source code is available at https://github.com/cdjkim/ReSpec.
MASH-VLM: Mitigating Action-Scene Hallucination in Video-LLMs through Disentangled Spatial-Temporal Representations
Mar 20, 2025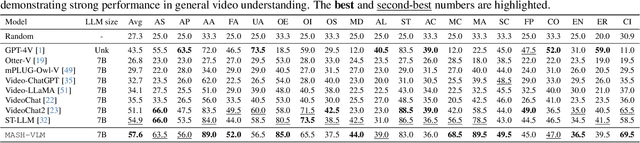
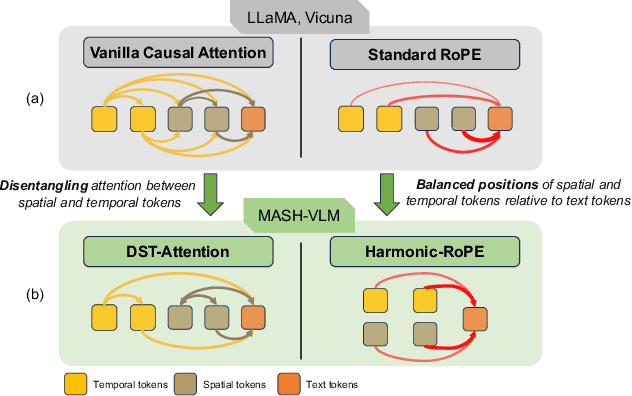
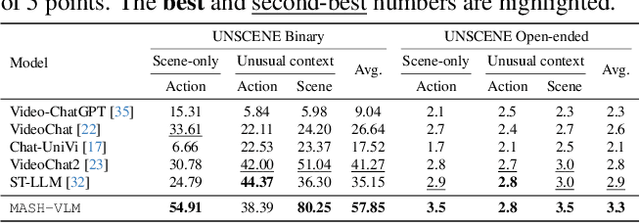
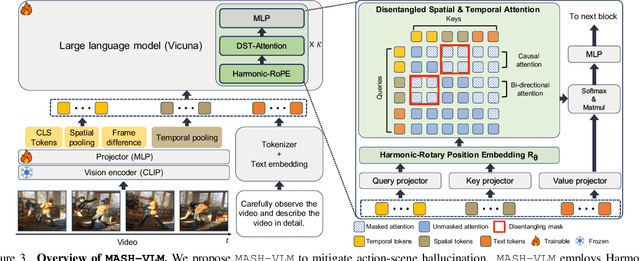
In this work, we tackle action-scene hallucination in Video Large Language Models (Video-LLMs), where models incorrectly predict actions based on the scene context or scenes based on observed actions. We observe that existing Video-LLMs often suffer from action-scene hallucination due to two main factors. First, existing Video-LLMs intermingle spatial and temporal features by applying an attention operation across all tokens. Second, they use the standard Rotary Position Embedding (RoPE), which causes the text tokens to overemphasize certain types of tokens depending on their sequential orders. To address these issues, we introduce MASH-VLM, Mitigating Action-Scene Hallucination in Video-LLMs through disentangled spatial-temporal representations. Our approach includes two key innovations: (1) DST-attention, a novel attention mechanism that disentangles the spatial and temporal tokens within the LLM by using masked attention to restrict direct interactions between the spatial and temporal tokens; (2) Harmonic-RoPE, which extends the dimensionality of the positional IDs, allowing the spatial and temporal tokens to maintain balanced positions relative to the text tokens. To evaluate the action-scene hallucination in Video-LLMs, we introduce the UNSCENE benchmark with 1,320 videos and 4,078 QA pairs. Extensive experiments demonstrate that MASH-VLM achieves state-of-the-art results on the UNSCENE benchmark, as well as on existing video understanding benchmarks.
NICE: CVPR 2023 Challenge on Zero-shot Image Captioning
Sep 11, 2023



In this report, we introduce NICE (New frontiers for zero-shot Image Captioning Evaluation) project and share the results and outcomes of 2023 challenge. This project is designed to challenge the computer vision community to develop robust image captioning models that advance the state-of-the-art both in terms of accuracy and fairness. Through the challenge, the image captioning models were tested using a new evaluation dataset that includes a large variety of visual concepts from many domains. There was no specific training data provided for the challenge, and therefore the challenge entries were required to adapt to new types of image descriptions that had not been seen during training. This report includes information on the newly proposed NICE dataset, evaluation methods, challenge results, and technical details of top-ranking entries. We expect that the outcomes of the challenge will contribute to the improvement of AI models on various vision-language tasks.
Large-Scale Bidirectional Training for Zero-Shot Image Captioning
Nov 15, 2022
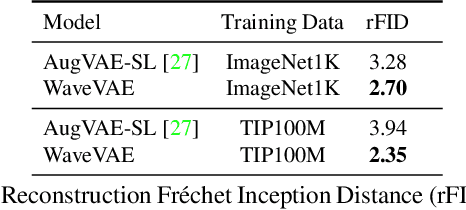
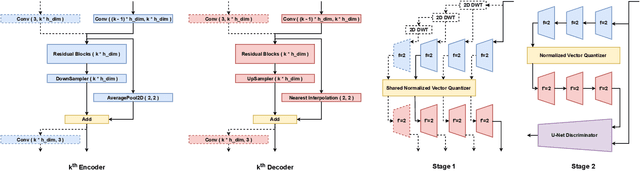
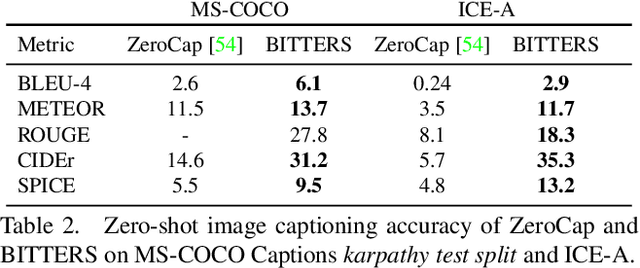
When trained on large-scale datasets, image captioning models can understand the content of images from a general domain but often fail to generate accurate, detailed captions. To improve performance, pretraining-and-finetuning has been a key strategy for image captioning. However, we find that large-scale bidirectional training between image and text enables zero-shot image captioning. In this paper, we introduce Bidirectional Image Text Training in largER Scale, BITTERS, an efficient training and inference framework for zero-shot image captioning. We also propose a new evaluation benchmark which comprises of high quality datasets and an extensive set of metrics to properly evaluate zero-shot captioning accuracy and societal bias. We additionally provide an efficient finetuning approach for keyword extraction. We show that careful selection of large-scale training set and model architecture is the key to achieving zero-shot image captioning.
Rich CNN-Transformer Feature Aggregation Networks for Super-Resolution
Mar 16, 2022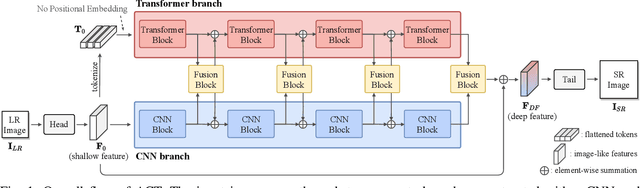


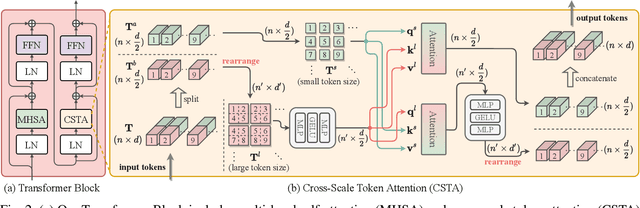
Recent vision transformers along with self-attention have achieved promising results on various computer vision tasks. In particular, a pure transformer-based image restoration architecture surpasses the existing CNN-based methods using multi-task pre-training with a large number of trainable parameters. In this paper, we introduce an effective hybrid architecture for super-resolution (SR) tasks, which leverages local features from CNNs and long-range dependencies captured by transformers to further improve the SR results. Specifically, our architecture comprises of transformer and convolution branches, and we substantially elevate the performance by mutually fusing two branches to complement each representation. Furthermore, we propose a cross-scale token attention module, which allows the transformer to efficiently exploit the informative relationships among tokens across different scales. Our proposed method achieves state-of-the-art SR results on numerous benchmark datasets.
L-Verse: Bidirectional Generation Between Image and Text
Dec 03, 2021
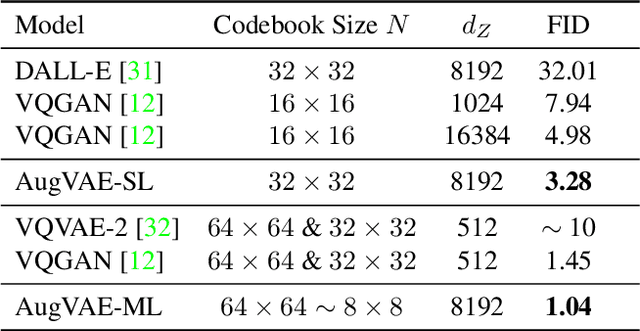
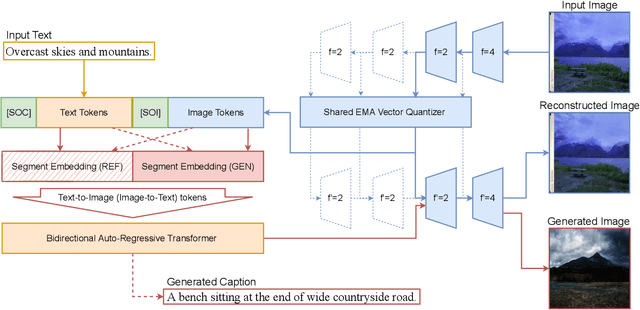
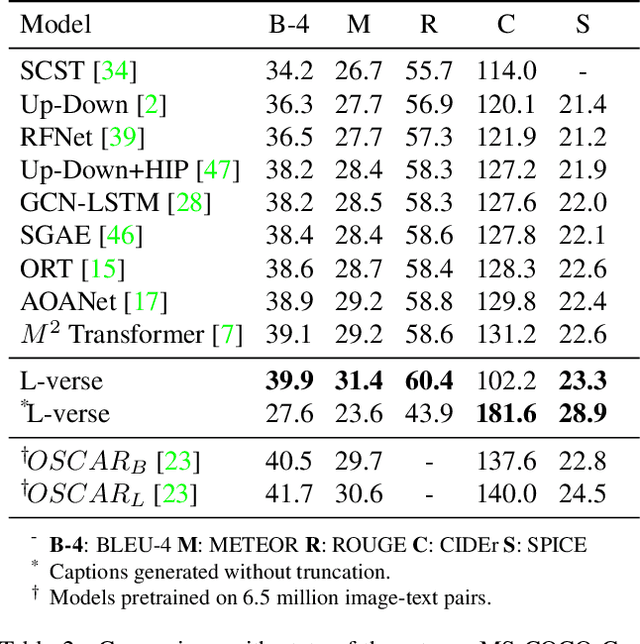
Far beyond learning long-range interactions of natural language, transformers are becoming the de-facto standard for many vision tasks with their power and scalabilty. Especially with cross-modal tasks between image and text, vector quantized variational autoencoders (VQ-VAEs) are widely used to make a raw RGB image into a sequence of feature vectors. To better leverage the correlation between image and text, we propose L-Verse, a novel architecture consisting of feature-augmented variational autoencoder (AugVAE) and bidirectional auto-regressive transformer (BiART) for text-to-image and image-to-text generation. Our AugVAE shows the state-of-the-art reconstruction performance on ImageNet1K validation set, along with the robustness to unseen images in the wild. Unlike other models, BiART can distinguish between image (or text) as a conditional reference and a generation target. L-Verse can be directly used for image-to-text or text-to-image generation tasks without any finetuning or extra object detection frameworks. In quantitative and qualitative experiments, L-Verse shows impressive results against previous methods in both image-to-text and text-to-image generation on MS-COCO Captions. We furthermore assess the scalability of L-Verse architecture on Conceptual Captions and present the initial results of bidirectional vision-language representation learning on general domain.
TricubeNet: 2D Kernel-Based Object Representation for Weakly-Occluded Oriented Object Detection
Apr 23, 2021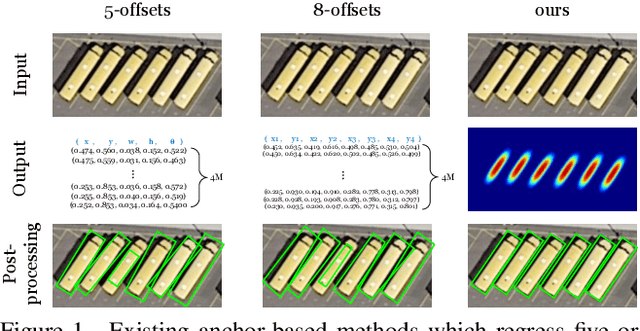
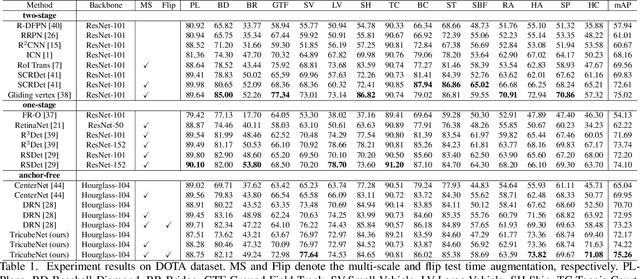
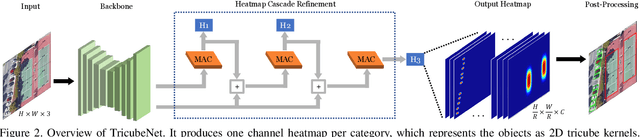
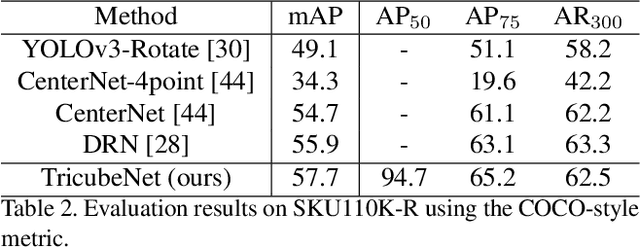
We present a new approach for oriented object detection, an anchor-free one-stage detector. This approach, named TricubeNet, represents each object as a 2D Tricube kernel and extracts bounding boxes using appearance-based post-processing. Unlike existing anchor-based oriented object detectors, we can save the computational complexity and the number of hyperparameters by eliminating the anchor box in the network design. In addition, by adopting a heatmap-based detection process instead of the box offset regression, we simply and effectively solve the angle discontinuity problem, which is one of the important problems for oriented object detection. To further boost the performance, we propose some effective techniques for the loss balancing, extracting the rotation-invariant feature, and heatmap refinement. To demonstrate the effectiveness of our TricueNet, we experiment on various tasks for the weakly-occluded oriented object detection. The extensive experimental results show that our TricueNet is highly effective and competitive for oriented object detection. The code is available at https://github.com/qjadud1994/TricubeNet.
Deep Temporal Appearance-Geometry Network for Facial Expression Recognition
Mar 05, 2015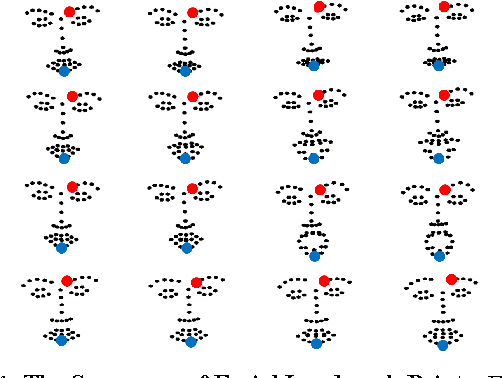

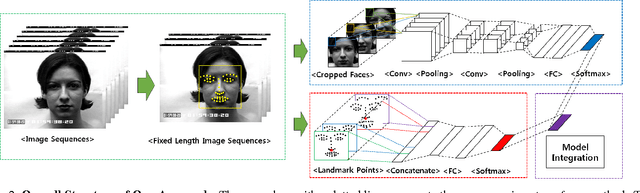

Temporal information can provide useful features for recognizing facial expressions. However, to manually design useful features requires a lot of effort. In this paper, to reduce this effort, a deep learning technique which is regarded as a tool to automatically extract useful features from raw data, is adopted. Our deep network is based on two different models. The first deep network extracts temporal geometry features from temporal facial landmark points, while the other deep network extracts temporal appearance features from image sequences . These two models are combined in order to boost the performance of the facial expression recognition. Through several experiments, we showed that the two models cooperate with each other. As a result, we achieved superior performance to other state-of-the-art methods in CK+ and Oulu-CASIA databases. Furthermore, one of the main contributions of this paper is that our deep network catches the facial action points automatically.