 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePri4R: Learning World Dynamics for Vision-Language-Action Models with Privileged 4D Representation
Mar 02, 2026Humans learn not only how their bodies move, but also how the surrounding world responds to their actions. In contrast, while recent Vision-Language-Action (VLA) models exhibit impressive semantic understanding, they often fail to capture the spatiotemporal dynamics governing physical interaction. In this paper, we introduce Pri4R, a simple yet effective approach that endows VLA models with an implicit understanding of world dynamics by leveraging privileged 4D information during training. Specifically, Pri4R augments VLAs with a lightweight point track head that predicts 3D point tracks. By injecting VLA features into this head to jointly predict future 3D trajectories, the model learns to incorporate evolving scene geometry within its shared representation space, enabling more physically aware context for precise control. Due to its architectural simplicity, Pri4R is compatible with dominant VLA design patterns with minimal changes. During inference, we run the model using the original VLA architecture unchanged; Pri4R adds no extra inputs, outputs, or computational overhead. Across simulation and real-world evaluations, Pri4R significantly improves performance on challenging manipulation tasks, including a +10% gain on LIBERO-Long and a +40% gain on RoboCasa. We further show that 3D point track prediction is an effective supervision target for learning action-world dynamics, and validate our design choices through extensive ablations.
MASH-VLM: Mitigating Action-Scene Hallucination in Video-LLMs through Disentangled Spatial-Temporal Representations
Mar 20, 2025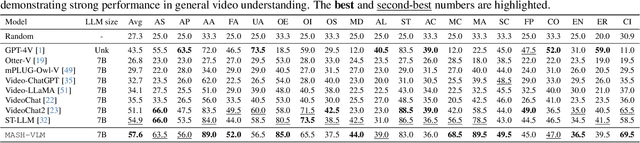
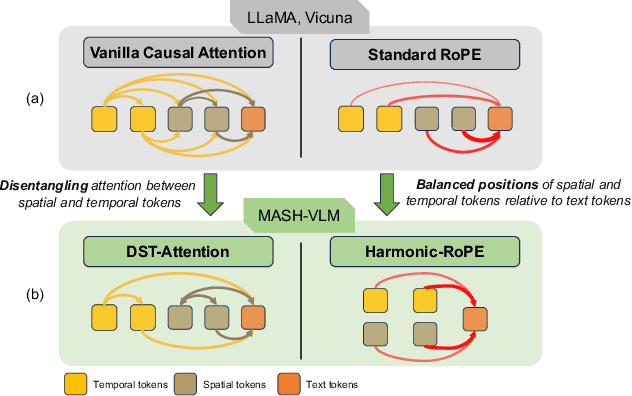
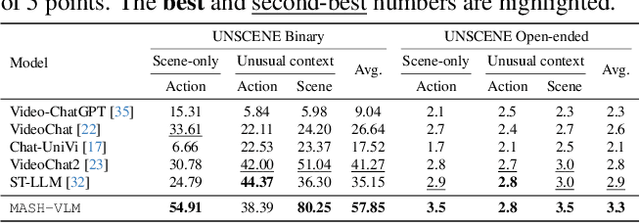
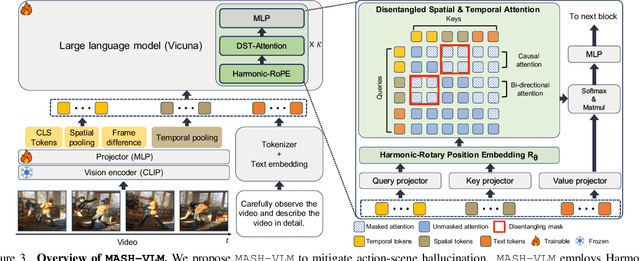
In this work, we tackle action-scene hallucination in Video Large Language Models (Video-LLMs), where models incorrectly predict actions based on the scene context or scenes based on observed actions. We observe that existing Video-LLMs often suffer from action-scene hallucination due to two main factors. First, existing Video-LLMs intermingle spatial and temporal features by applying an attention operation across all tokens. Second, they use the standard Rotary Position Embedding (RoPE), which causes the text tokens to overemphasize certain types of tokens depending on their sequential orders. To address these issues, we introduce MASH-VLM, Mitigating Action-Scene Hallucination in Video-LLMs through disentangled spatial-temporal representations. Our approach includes two key innovations: (1) DST-attention, a novel attention mechanism that disentangles the spatial and temporal tokens within the LLM by using masked attention to restrict direct interactions between the spatial and temporal tokens; (2) Harmonic-RoPE, which extends the dimensionality of the positional IDs, allowing the spatial and temporal tokens to maintain balanced positions relative to the text tokens. To evaluate the action-scene hallucination in Video-LLMs, we introduce the UNSCENE benchmark with 1,320 videos and 4,078 QA pairs. Extensive experiments demonstrate that MASH-VLM achieves state-of-the-art results on the UNSCENE benchmark, as well as on existing video understanding benchmarks.
Enhancing Whole Slide Pathology Foundation Models through Stain Normalization
Aug 05, 2024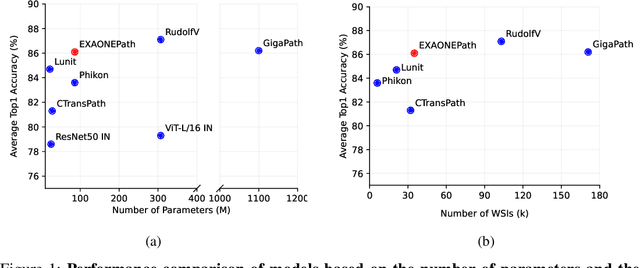
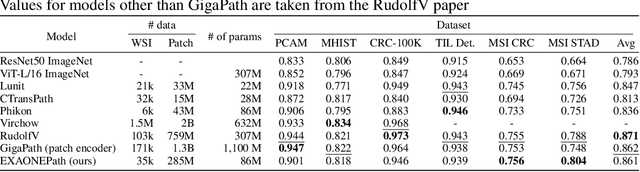
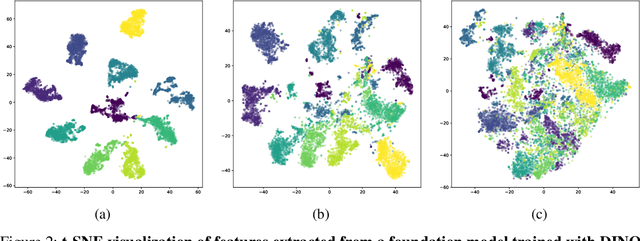
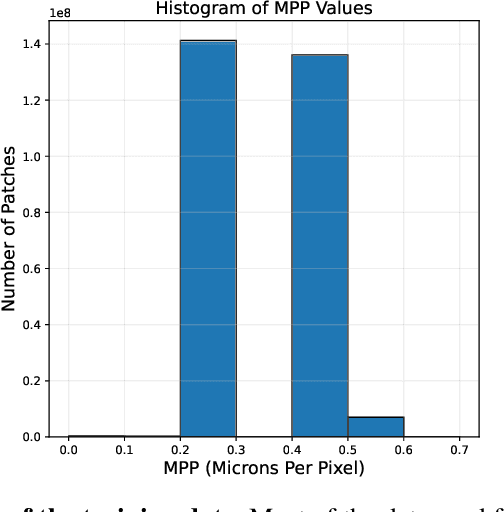
Recent advancements in digital pathology have led to the development of numerous foundational models that utilize self-supervised learning on patches extracted from gigapixel whole slide images (WSIs). While this approach leverages vast amounts of unlabeled data, we have discovered a significant issue: features extracted from these self-supervised models tend to cluster by individual WSIs, a phenomenon we term WSI-specific feature collapse. This problem can potentially limit the model's generalization ability and performance on various downstream tasks. To address this issue, we introduce Stain Normalized Pathology Foundational Model, a novel foundational model trained on patches that have undergone stain normalization. Stain normalization helps reduce color variability arising from different laboratories and scanners, enabling the model to learn more consistent features. Stain Normalized Pathology Foundational Model is trained using 285,153,903 patches extracted from a total of 34,795 WSIs, combining data from The Cancer Genome Atlas (TCGA) and the Genotype-Tissue Expression (GTEx) project. Our experiments demonstrate that Stain Normalized Pathology Foundational Model significantly mitigates the feature collapse problem, indicating that the model has learned more generalized features rather than overfitting to individual WSI characteristics. We compared Stain Normalized Pathology Foundational Model with state-of-the-art models across six downstream task datasets, and our results show that Stain Normalized Pathology Foundational Model achieves excellent performance relative to the number of WSIs used and the model's parameter count. This suggests that the application of stain normalization has substantially improved the model's efficiency and generalization capabilities.
Exploring the Spectrum of Visio-Linguistic Compositionality and Recognition
Jun 13, 2024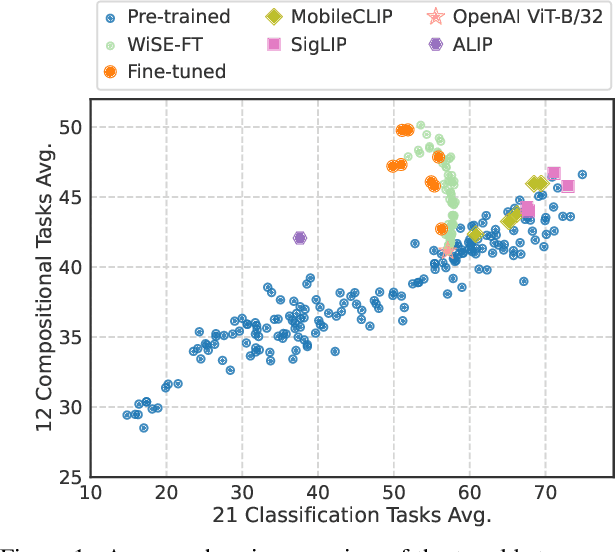
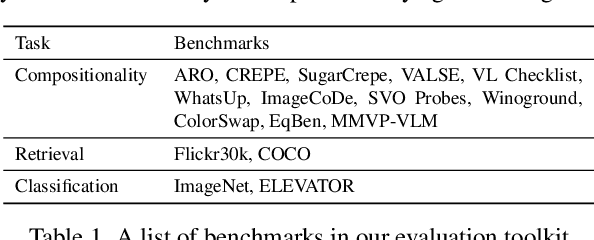
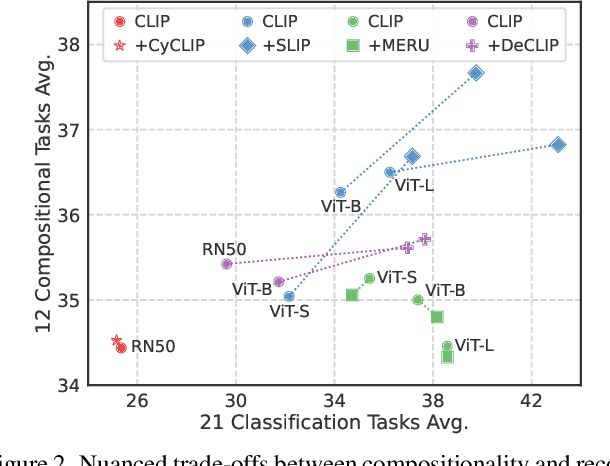
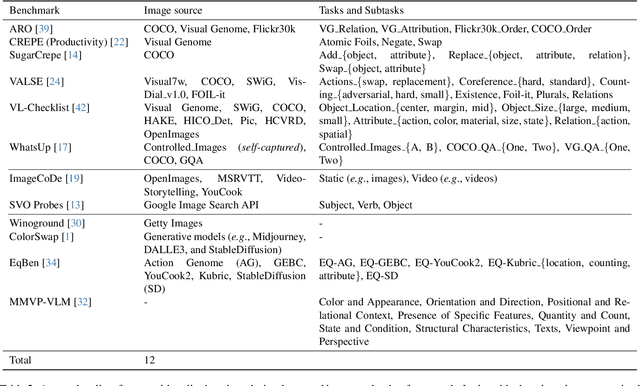
Vision and language models (VLMs) such as CLIP have showcased remarkable zero-shot recognition abilities yet face challenges in visio-linguistic compositionality, particularly in linguistic comprehension and fine-grained image-text alignment. This paper explores the intricate relationship between compositionality and recognition -- two pivotal aspects of VLM capability. We conduct a comprehensive evaluation of existing VLMs, covering both pre-training approaches aimed at recognition and the fine-tuning methods designed to improve compositionality. Our evaluation employs 12 benchmarks for compositionality, along with 21 zero-shot classification and two retrieval benchmarks for recognition. In our analysis from 274 CLIP model checkpoints, we reveal patterns and trade-offs that emerge between compositional understanding and recognition accuracy. Ultimately, this necessitates strategic efforts towards developing models that improve both capabilities, as well as the meticulous formulation of benchmarks for compositionality. We open our evaluation framework at https://github.com/ytaek-oh/vl_compo.
Misalign, Contrast then Distill: Rethinking Misalignments in Language-Image Pretraining
Dec 19, 2023Contrastive Language-Image Pretraining has emerged as a prominent approach for training vision and text encoders with uncurated image-text pairs from the web. To enhance data-efficiency, recent efforts have introduced additional supervision terms that involve random-augmented views of the image. However, since the image augmentation process is unaware of its text counterpart, this procedure could cause various degrees of image-text misalignments during training. Prior methods either disregarded this discrepancy or introduced external models to mitigate the impact of misalignments during training. In contrast, we propose a novel metric learning approach that capitalizes on these misalignments as an additional training source, which we term "Misalign, Contrast then Distill (MCD)". Unlike previous methods that treat augmented images and their text counterparts as simple positive pairs, MCD predicts the continuous scales of misalignment caused by the augmentation. Our extensive experimental results show that our proposed MCD achieves state-of-the-art transferability in multiple classification and retrieval downstream datasets.
Expediting Contrastive Language-Image Pretraining via Self-distilled Encoders
Dec 19, 2023Recent advances in vision language pretraining (VLP) have been largely attributed to the large-scale data collected from the web. However, uncurated dataset contains weakly correlated image-text pairs, causing data inefficiency. To address the issue, knowledge distillation have been explored at the expense of extra image and text momentum encoders to generate teaching signals for misaligned image-text pairs. In this paper, our goal is to resolve the misalignment problem with an efficient distillation framework. To this end, we propose ECLIPSE: Expediting Contrastive Language-Image Pretraining with Self-distilled Encoders. ECLIPSE features a distinctive distillation architecture wherein a shared text encoder is utilized between an online image encoder and a momentum image encoder. This strategic design choice enables the distillation to operate within a unified projected space of text embedding, resulting in better performance. Based on the unified text embedding space, ECLIPSE compensates for the additional computational cost of the momentum image encoder by expediting the online image encoder. Through our extensive experiments, we validate that there is a sweet spot between expedition and distillation where the partial view from the expedited online image encoder interacts complementarily with the momentum teacher. As a result, ECLIPSE outperforms its counterparts while achieving substantial acceleration in inference speed.
Masked Autoencoder for Unsupervised Video Summarization
Jun 02, 2023



Summarizing a video requires a diverse understanding of the video, ranging from recognizing scenes to evaluating how much each frame is essential enough to be selected as a summary. Self-supervised learning (SSL) is acknowledged for its robustness and flexibility to multiple downstream tasks, but the video SSL has not shown its value for dense understanding tasks like video summarization. We claim an unsupervised autoencoder with sufficient self-supervised learning does not need any extra downstream architecture design or fine-tuning weights to be utilized as a video summarization model. The proposed method to evaluate the importance score of each frame takes advantage of the reconstruction score of the autoencoder's decoder. We evaluate the method in major unsupervised video summarization benchmarks to show its effectiveness under various experimental settings.
Exploring Temporally Dynamic Data Augmentation for Video Recognition
Jun 30, 2022
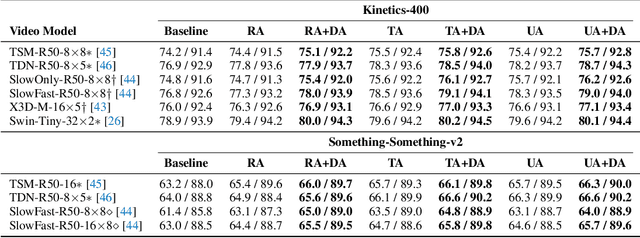
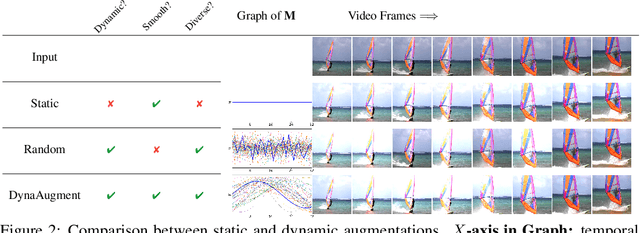

Data augmentation has recently emerged as an essential component of modern training recipes for visual recognition tasks. However, data augmentation for video recognition has been rarely explored despite its effectiveness. Few existing augmentation recipes for video recognition naively extend the image augmentation methods by applying the same operations to the whole video frames. Our main idea is that the magnitude of augmentation operations for each frame needs to be changed over time to capture the real-world video's temporal variations. These variations should be generated as diverse as possible using fewer additional hyper-parameters during training. Through this motivation, we propose a simple yet effective video data augmentation framework, DynaAugment. The magnitude of augmentation operations on each frame is changed by an effective mechanism, Fourier Sampling that parameterizes diverse, smooth, and realistic temporal variations. DynaAugment also includes an extended search space suitable for video for automatic data augmentation methods. DynaAugment experimentally demonstrates that there are additional performance rooms to be improved from static augmentations on diverse video models. Specifically, we show the effectiveness of DynaAugment on various video datasets and tasks: large-scale video recognition (Kinetics-400 and Something-Something-v2), small-scale video recognition (UCF- 101 and HMDB-51), fine-grained video recognition (Diving-48 and FineGym), video action segmentation on Breakfast, video action localization on THUMOS'14, and video object detection on MOT17Det. DynaAugment also enables video models to learn more generalized representation to improve the model robustness on the corrupted videos.
Spatiotemporal Augmentation on Selective Frequencies for Video Representation Learning
Apr 08, 2022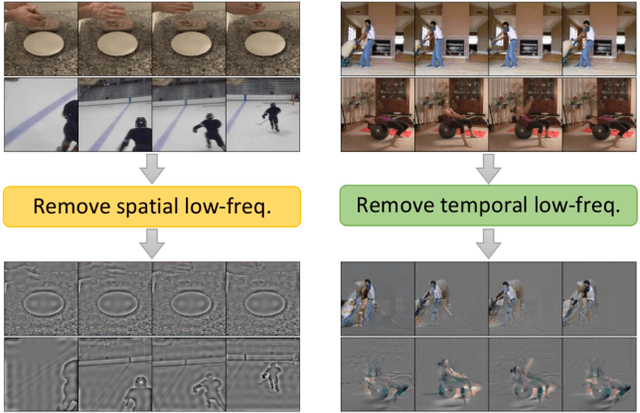
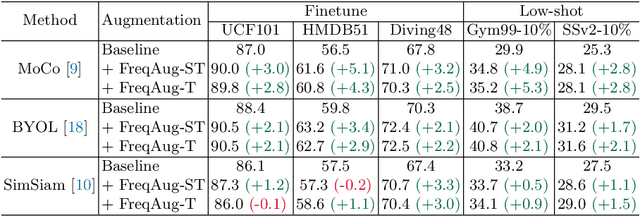
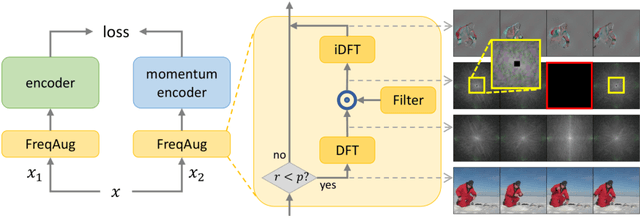
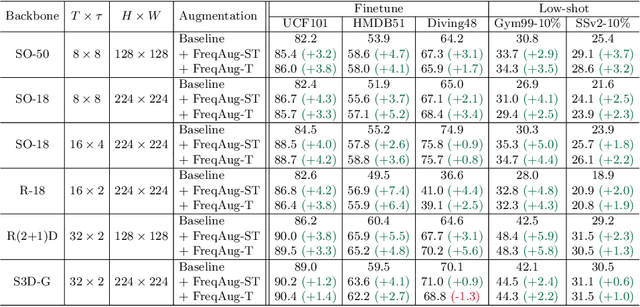
Recent self-supervised video representation learning methods focus on maximizing the similarity between multiple augmented views from the same video and largely rely on the quality of generated views. In this paper, we propose frequency augmentation (FreqAug), a spatio-temporal data augmentation method in the frequency domain for video representation learning. FreqAug stochastically removes undesirable information from the video by filtering out specific frequency components so that learned representation captures essential features of the video for various downstream tasks. Specifically, FreqAug pushes the model to focus more on dynamic features rather than static features in the video via dropping spatial or temporal low-frequency components. In other words, learning invariance between remaining frequency components results in high-frequency enhanced representation with less static bias. To verify the generality of the proposed method, we experiment with FreqAug on multiple self-supervised learning frameworks along with standard augmentations. Transferring the improved representation to five video action recognition and two temporal action localization downstream tasks shows consistent improvements over baselines.
VideoMix: Rethinking Data Augmentation for Video Classification
Dec 07, 2020
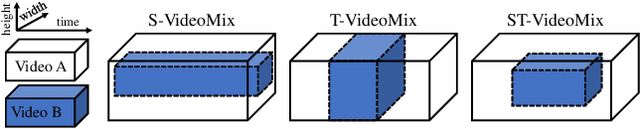
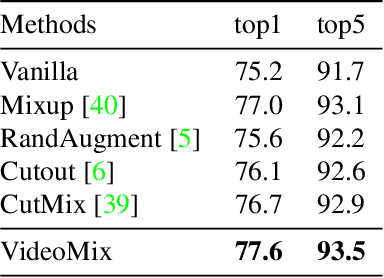
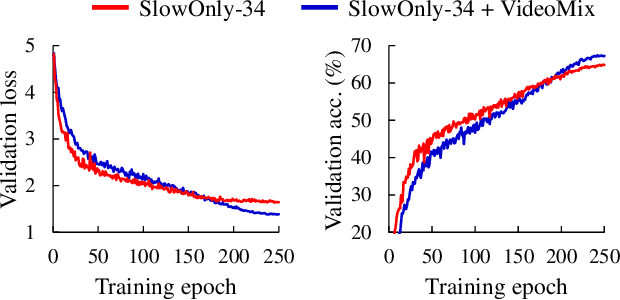
State-of-the-art video action classifiers often suffer from overfitting. They tend to be biased towards specific objects and scene cues, rather than the foreground action content, leading to sub-optimal generalization performances. Recent data augmentation strategies have been reported to address the overfitting problems in static image classifiers. Despite the effectiveness on the static image classifiers, data augmentation has rarely been studied for videos. For the first time in the field, we systematically analyze the efficacy of various data augmentation strategies on the video classification task. We then propose a powerful augmentation strategy VideoMix. VideoMix creates a new training video by inserting a video cuboid into another video. The ground truth labels are mixed proportionally to the number of voxels from each video. We show that VideoMix lets a model learn beyond the object and scene biases and extract more robust cues for action recognition. VideoMix consistently outperforms other augmentation baselines on Kinetics and the challenging Something-Something-V2 benchmarks. It also improves the weakly-supervised action localization performance on THUMOS'14. VideoMix pretrained models exhibit improved accuracies on the video detection task (AVA).