 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoMix: Rethinking Data Augmentation for Video Classification
Paper and Code

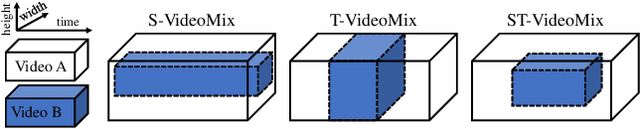
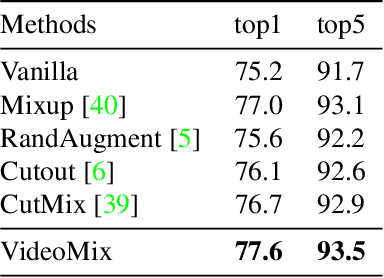
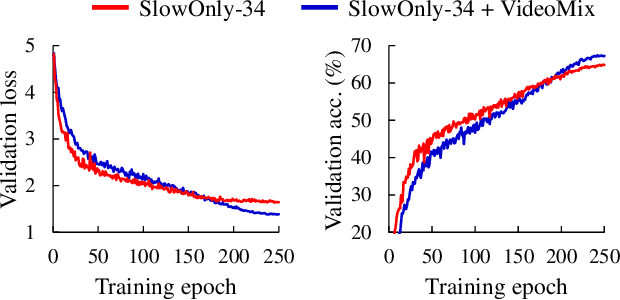
State-of-the-art video action classifiers often suffer from overfitting. They tend to be biased towards specific objects and scene cues, rather than the foreground action content, leading to sub-optimal generalization performances. Recent data augmentation strategies have been reported to address the overfitting problems in static image classifiers. Despite the effectiveness on the static image classifiers, data augmentation has rarely been studied for videos. For the first time in the field, we systematically analyze the efficacy of various data augmentation strategies on the video classification task. We then propose a powerful augmentation strategy VideoMix. VideoMix creates a new training video by inserting a video cuboid into another video. The ground truth labels are mixed proportionally to the number of voxels from each video. We show that VideoMix lets a model learn beyond the object and scene biases and extract more robust cues for action recognition. VideoMix consistently outperforms other augmentation baselines on Kinetics and the challenging Something-Something-V2 benchmarks. It also improves the weakly-supervised action localization performance on THUMOS'14. VideoMix pretrained models exhibit improved accuracies on the video detection task (AVA).