 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to See What You Need: Gaze Attention for Multimodal Large Language Models
May 13, 2026When humans describe a visual scene, they do not process the entire image uniformly; instead, they selectively fixate on regions relevant to their intended description. In contrast, current multimodal large language models (MLLMs) attend to all visual tokens at each generation step, leading to diluted focus and unnecessary computational overhead. In this work, we introduce Gaze Attention, a novel mechanism that enables MLLMs to selectively attend to task-relevant visual regions during generation. Specifically, we spatially group visual embeddings-stored as key-value caches-into compact gaze regions, each represented by a lightweight descriptor. At each decoding step, the model dynamically selects the most relevant regions and restricts attention to them, reducing redundant computation while enhancing focus. To mitigate the loss of global context caused by localized attention, we further propose learnable context tokens appended to each image or frame, allowing the model to maintain holistic visual awareness. Extensive experiments on image and video understanding benchmarks demonstrate that Gaze Attention matches or surpasses dense-attention baselines, while using up to 90% fewer visual KV entries in the attention computation.
StoryCoder: Narrative Reformulation for Structured Reasoning in LLM Code Generation
Apr 16, 2026Effective code generation requires both model capability and a problem representation that carefully structures how models reason and plan. Existing approaches augment reasoning steps or inject specific structure into how models think, but leave scattered problem conditions unchanged. Inspired by the way humans organize fragmented information into coherent explanations, we propose StoryCoder, a narrative reformulation framework that transforms code generation questions into coherent natural language narratives, providing richer contextual structure than simple rephrasings. Each narrative consists of three components: a task overview, constraints, and example test cases, guided by the selected algorithm and genre. Experiments across 11 models on HumanEval, LiveCodeBench, and CodeForces demonstrate consistent improvements, with an average gain of 18.7% in zero-shot pass@10. Beyond accuracy, our analyses reveal that narrative reformulation guides models toward correct algorithmic strategies, reduces implementation errors, and induces a more modular code structure. The analyses further show that these benefits depend on narrative coherence and genre alignment, suggesting that structured problem representation is important for code generation regardless of model scale or architecture. Our code is available at https://github.com/gu-ni/StoryCoder.
Which Concepts to Forget and How to Refuse? Decomposing Concepts for Continual Unlearning in Large Vision-Language Models
Mar 23, 2026Continual unlearning poses the challenge of enabling large vision-language models to selectively refuse specific image-instruction pairs in response to sequential deletion requests, while preserving general utility. However, sequential unlearning updates distort shared representations, creating spurious associations between vision-language pairs and refusal behaviors that hinder precise identification of refusal targets, resulting in inappropriate refusals. To address this challenge, we propose a novel continual unlearning framework that grounds refusal behavior in fine-grained descriptions of visual and textual concepts decomposed from deletion targets. We first identify which visual-linguistic concept combinations characterize each forget category through a concept modulator, then determine how to generate appropriate refusal responses via a mixture of refusal experts, termed refusers, each specialized for concept-aligned refusal generation. To generate concept-specific refusal responses across sequential tasks, we introduce a multimodal, concept-driven routing scheme that reuses refusers for tasks sharing similar concepts and adapts underutilized ones for novel concepts. Extensive experiments on vision-language benchmarks demonstrate that the proposed framework outperforms existing methods by generating concept-grounded refusal responses and preserving the general utility across unlearning sequences.
Grounding World Simulation Models in a Real-World Metropolis
Mar 16, 2026What if a world simulation model could render not an imagined environment but a city that actually exists? Prior generative world models synthesize visually plausible yet artificial environments by imagining all content. We present Seoul World Model (SWM), a city-scale world model grounded in the real city of Seoul. SWM anchors autoregressive video generation through retrieval-augmented conditioning on nearby street-view images. However, this design introduces several challenges, including temporal misalignment between retrieved references and the dynamic target scene, limited trajectory diversity and data sparsity from vehicle-mounted captures at sparse intervals. We address these challenges through cross-temporal pairing, a large-scale synthetic dataset enabling diverse camera trajectories, and a view interpolation pipeline that synthesizes coherent training videos from sparse street-view images. We further introduce a Virtual Lookahead Sink to stabilize long-horizon generation by continuously re-grounding each chunk to a retrieved image at a future location. We evaluate SWM against recent video world models across three cities: Seoul, Busan, and Ann Arbor. SWM outperforms existing methods in generating spatially faithful, temporally consistent, long-horizon videos grounded in actual urban environments over trajectories reaching hundreds of meters, while supporting diverse camera movements and text-prompted scenario variations.
On the Reliability of Cue Conflict and Beyond
Mar 12, 2026Understanding how neural networks rely on visual cues offers a human-interpretable view of their internal decision processes. The cue-conflict benchmark has been influential in probing shape-texture preference and in motivating the insight that stronger, human-like shape bias is often associated with improved in-domain performance. However, we find that the current stylization-based instantiation can yield unstable and ambiguous bias estimates. Specifically, stylization may not reliably instantiate perceptually valid and separable cues nor control their relative informativeness, ratio-based bias can obscure absolute cue sensitivity, and restricting evaluation to preselected classes can distort model predictions by ignoring the full decision space. Together, these factors can confound preference with cue validity, cue balance, and recognizability artifacts. We introduce REFINED-BIAS, an integrated dataset and evaluation framework for reliable and interpretable shape-texture bias diagnosis. REFINED-BIAS constructs balanced, human- and model- recognizable cue pairs using explicit definitions of shape and texture, and measures cue-specific sensitivity over the full label space via a ranking-based metric, enabling fairer cross-model comparisons. Across diverse training regimes and architectures, REFINED-BIAS enables fairer cross-model comparison, more faithful diagnosis of shape and texture biases, and clearer empirical conclusions, resolving inconsistencies that prior cue-conflict evaluations could not reliably disambiguate.
MuCo: Multi-turn Contrastive Learning for Multimodal Embedding Model
Feb 06, 2026Universal Multimodal embedding models built on Multimodal Large Language Models (MLLMs) have traditionally employed contrastive learning, which aligns representations of query-target pairs across different modalities. Yet, despite its empirical success, they are primarily built on a "single-turn" formulation where each query-target pair is treated as an independent data point. This paradigm leads to computational inefficiency when scaling, as it requires a separate forward pass for each pair and overlooks potential contextual relationships between multiple queries that can relate to the same context. In this work, we introduce Multi-Turn Contrastive Learning (MuCo), a dialogue-inspired framework that revisits this process. MuCo leverages the conversational nature of MLLMs to process multiple, related query-target pairs associated with a single image within a single forward pass. This allows us to extract a set of multiple query and target embeddings simultaneously, conditioned on a shared context representation, amplifying the effective batch size and overall training efficiency. Experiments exhibit MuCo with a newly curated 5M multimodal multi-turn dataset (M3T), which yields state-of-the-art retrieval performance on MMEB and M-BEIR benchmarks, while markedly enhancing both training efficiency and representation coherence across modalities. Code and M3T are available at https://github.com/naver-ai/muco
Fast KVzip: Efficient and Accurate LLM Inference with Gated KV Eviction
Jan 25, 2026Efficient key-value (KV) cache management is crucial for the practical deployment of large language models (LLMs), yet existing compression techniques often incur a trade-off between performance degradation and computational overhead. We propose a novel gating-based KV cache eviction method for frozen-weight LLMs that achieves high compression ratios with negligible computational cost. Our approach introduces lightweight sink-attention gating modules to identify and retain critical KV pairs, and integrates seamlessly into both the prefill and decoding stages. The proposed gate training algorithm relies on forward passes of an LLM, avoiding expensive backpropagation, while achieving strong task generalization through a task-agnostic reconstruction objective. Extensive experiments across the Qwen2.5-1M, Qwen3, and Gemma3 families show that our method maintains near-lossless performance while evicting up to 70% of the KV cache. The results are consistent across a wide range of tasks, including long-context understanding, code comprehension, and mathematical reasoning, demonstrating the generality of our approach.
Oops, Wait: Token-Level Signals as a Lens into LLM Reasoning
Jan 24, 2026The emergence of discourse-like tokens such as "wait" and "therefore" in large language models (LLMs) has offered a unique window into their reasoning processes. However, systematic analyses of how such signals vary across training strategies and model scales remain lacking. In this paper, we analyze token-level signals through token probabilities across various models. We find that specific tokens strongly correlate with reasoning correctness, varying with training strategies while remaining stable across model scales. A closer look at the "wait" token in relation to answer probability demonstrates that models fine-tuned on small-scale datasets acquire reasoning ability through such signals but exploit them only partially. This work provides a systematic lens to observe and understand the dynamics of LLM reasoning.
What Defines Good Reasoning in LLMs? Dissecting Reasoning Steps with Multi-Aspect Evaluation
Oct 23, 2025
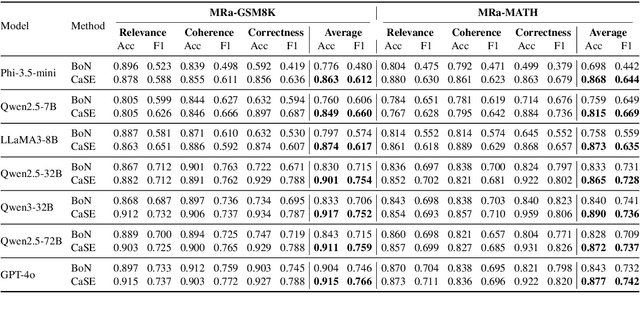
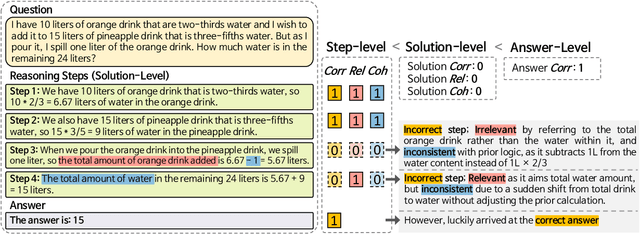
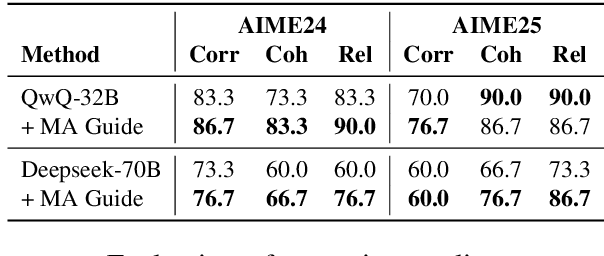
Evaluating large language models (LLMs) on final-answer correctness is the dominant paradigm. This approach, however, provides a coarse signal for model improvement and overlooks the quality of the underlying reasoning process. We argue that a more granular evaluation of reasoning offers a more effective path to building robust models. We decompose reasoning quality into two dimensions: relevance and coherence. Relevance measures if a step is grounded in the problem; coherence measures if it follows logically from prior steps. To measure these aspects reliably, we introduce causal stepwise evaluation (CaSE). This method assesses each reasoning step using only its preceding context, which avoids hindsight bias. We validate CaSE against human judgments on our new expert-annotated benchmarks, MRa-GSM8K and MRa-MATH. More importantly, we show that curating training data with CaSE-evaluated relevance and coherence directly improves final task performance. Our work provides a scalable framework for analyzing, debugging, and improving LLM reasoning, demonstrating the practical value of moving beyond validity checks.
Revisiting Reliability in the Reasoning-based Pose Estimation Benchmark
Jul 17, 2025The reasoning-based pose estimation (RPE) benchmark has emerged as a widely adopted evaluation standard for pose-aware multimodal large language models (MLLMs). Despite its significance, we identified critical reproducibility and benchmark-quality issues that hinder fair and consistent quantitative evaluations. Most notably, the benchmark utilizes different image indices from those of the original 3DPW dataset, forcing researchers into tedious and error-prone manual matching processes to obtain accurate ground-truth (GT) annotations for quantitative metrics (\eg, MPJPE, PA-MPJPE). Furthermore, our analysis reveals several inherent benchmark-quality limitations, including significant image redundancy, scenario imbalance, overly simplistic poses, and ambiguous textual descriptions, collectively undermining reliable evaluations across diverse scenarios. To alleviate manual effort and enhance reproducibility, we carefully refined the GT annotations through meticulous visual matching and publicly release these refined annotations as an open-source resource, thereby promoting consistent quantitative evaluations and facilitating future advancements in human pose-aware multimodal reasoning.