 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Block-wise PTQ and Distillation-based QAT for Progressive Quantization toward 2-bit Instruction-Tuned LLMs
Jun 10, 2025As the rapid scaling of large language models (LLMs) poses significant challenges for deployment on resource-constrained devices, there is growing interest in extremely low-bit quantization, such as 2-bit. Although prior works have shown that 2-bit large models are pareto-optimal over their 4-bit smaller counterparts in both accuracy and latency, these advancements have been limited to pre-trained LLMs and have not yet been extended to instruction-tuned models. To bridge this gap, we propose Unified Progressive Quantization (UPQ)$-$a novel progressive quantization framework (FP16$\rightarrow$INT4$\rightarrow$INT2) that unifies block-wise post-training quantization (PTQ) with distillation-based quantization-aware training (Distill-QAT) for INT2 instruction-tuned LLM quantization. UPQ first quantizes FP16 instruction-tuned models to INT4 using block-wise PTQ to significantly reduce the quantization error introduced by subsequent INT2 quantization. Next, UPQ applies Distill-QAT to enable INT2 instruction-tuned LLMs to generate responses consistent with their original FP16 counterparts by minimizing the generalized Jensen-Shannon divergence (JSD) between the two. To the best of our knowledge, we are the first to demonstrate that UPQ can quantize open-source instruction-tuned LLMs to INT2 without relying on proprietary post-training data, while achieving state-of-the-art performances on MMLU and IFEval$-$two of the most representative benchmarks for evaluating instruction-tuned LLMs.
LRQ: Optimizing Post-Training Quantization for Large Language Models by Learning Low-Rank Weight-Scaling Matrices
Jul 16, 2024



With the commercialization of large language models (LLMs), weight-activation quantization has emerged to compress and accelerate LLMs, achieving high throughput while reducing inference costs. However, existing post-training quantization (PTQ) techniques for quantizing weights and activations of LLMs still suffer from non-negligible accuracy drops, especially on massive multitask language understanding. To address this issue, we propose Low-Rank Quantization (LRQ) $-$ a simple yet effective post-training weight quantization method for LLMs that reconstructs the outputs of an intermediate Transformer block by leveraging low-rank weight-scaling matrices, replacing the conventional full weight-scaling matrices that entail as many learnable scales as their associated weights. Thanks to parameter sharing via low-rank structure, LRQ only needs to learn significantly fewer parameters while enabling the individual scaling of weights, thus boosting the generalization capability of quantized LLMs. We show the superiority of LRQ over prior LLM PTQ works under (i) $8$-bit weight and per-tensor activation quantization, (ii) $4$-bit weight and $8$-bit per-token activation quantization, and (iii) low-bit weight-only quantization schemes. Our code is available at \url{https://github.com/onliwad101/FlexRound_LRQ} to inspire LLM researchers and engineers.
Token-Supervised Value Models for Enhancing Mathematical Reasoning Capabilities of Large Language Models
Jul 12, 2024Large Language Models (LLMs) have demonstrated impressive problem-solving capabilities in mathematics through step-by-step reasoning chains. However, they are susceptible to reasoning errors that impact the quality of subsequent reasoning chains and the final answer due to language models' autoregressive token-by-token generating nature. Recent works have proposed adopting external verifiers to guide the generation of reasoning paths, but existing works utilize models that have been trained with step-by-step labels to assess the correctness of token-by-token reasoning chains. Consequently, they struggle to recognize discriminative details of tokens within a reasoning path and lack the ability to evaluate whether an intermediate reasoning path is on a promising track toward the correct final answer. To amend the lack of sound and token-grained math-verification signals, we devise a novel training scheme for verifiers that apply token-level supervision with the expected cumulative reward (i.e., value). Furthermore, we propose a practical formulation of the cumulative reward by reducing it to finding the probability of future correctness of the final answer and thereby enabling the empirical estimation of the value. Experimental results on mathematical reasoning benchmarks show that Token-Supervised Value Model (TVM) can outperform step-by-step verifiers on GSM8K and MATH with Mistral and Llama.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Label-Noise Robust Diffusion Models
Feb 27, 2024Conditional diffusion models have shown remarkable performance in various generative tasks, but training them requires large-scale datasets that often contain noise in conditional inputs, a.k.a. noisy labels. This noise leads to condition mismatch and quality degradation of generated data. This paper proposes Transition-aware weighted Denoising Score Matching (TDSM) for training conditional diffusion models with noisy labels, which is the first study in the line of diffusion models. The TDSM objective contains a weighted sum of score networks, incorporating instance-wise and time-dependent label transition probabilities. We introduce a transition-aware weight estimator, which leverages a time-dependent noisy-label classifier distinctively customized to the diffusion process. Through experiments across various datasets and noisy label settings, TDSM improves the quality of generated samples aligned with given conditions. Furthermore, our method improves generation performance even on prevalent benchmark datasets, which implies the potential noisy labels and their risk of generative model learning. Finally, we show the improved performance of TDSM on top of conventional noisy label corrections, which empirically proving its contribution as a part of label-noise robust generative models. Our code is available at: https://github.com/byeonghu-na/tdsm.
FlexRound: Learnable Rounding based on Element-wise Division for Post-Training Quantization
Jun 01, 2023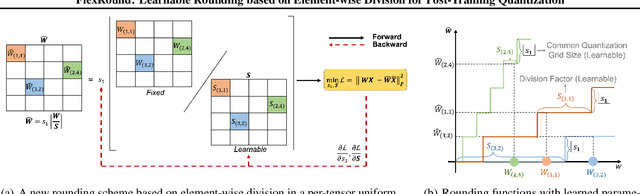
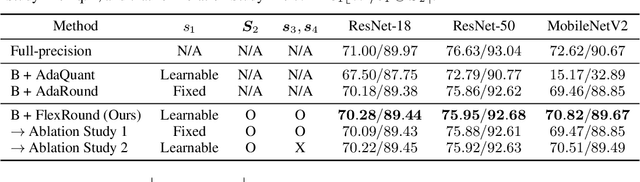
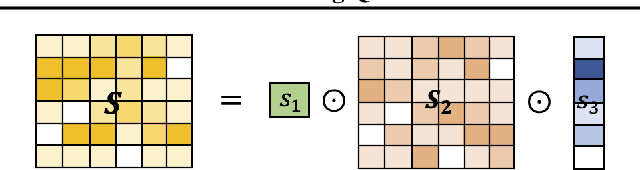
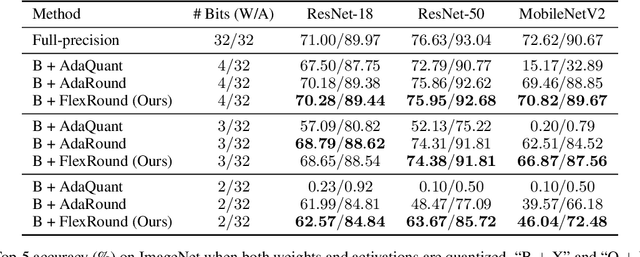
Post-training quantization (PTQ) has been gaining popularity for the deployment of deep neural networks on resource-limited devices since unlike quantization-aware training, neither a full training dataset nor end-to-end training is required at all. As PTQ schemes based on reconstructing each layer or block output turn out to be effective to enhance quantized model performance, recent works have developed algorithms to devise and learn a new weight-rounding scheme so as to better reconstruct each layer or block output. In this work, we propose a simple yet effective new weight-rounding mechanism for PTQ, coined FlexRound, based on element-wise division instead of typical element-wise addition such that FlexRound enables jointly learning a common quantization grid size as well as a different scale for each pre-trained weight. Thanks to the reciprocal rule of derivatives induced by element-wise division, FlexRound is inherently able to exploit pre-trained weights when updating their corresponding scales, and thus, flexibly quantize pre-trained weights depending on their magnitudes. We empirically validate the efficacy of FlexRound on a wide range of models and tasks. To the best of our knowledge, our work is the first to carry out comprehensive experiments on not only image classification and natural language understanding but also natural language generation, assuming a per-tensor uniform PTQ setting. Moreover, we demonstrate, for the first time, that large language models can be efficiently quantized, with only a negligible impact on performance compared to half-precision baselines, achieved by reconstructing the output in a block-by-block manner.
Memory-Efficient Fine-Tuning of Compressed Large Language Models via sub-4-bit Integer Quantization
May 23, 2023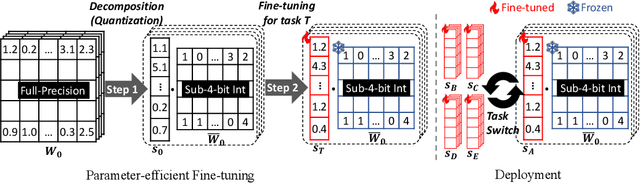

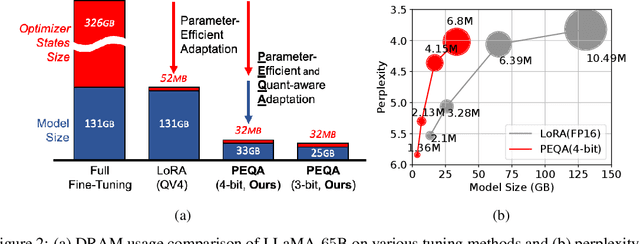
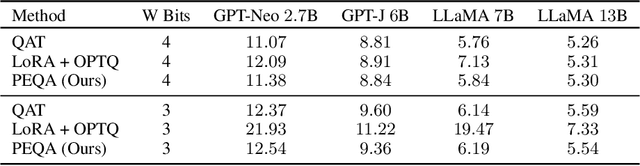
Parameter-efficient fine-tuning (PEFT) methods have emerged to mitigate the prohibitive cost of full fine-tuning large language models (LLMs). Nonetheless, the enormous size of LLMs impedes routine deployment. To address the issue, we present Parameter-Efficient and Quantization-aware Adaptation (PEQA), a novel quantization-aware PEFT technique that facilitates model compression and accelerates inference. PEQA operates through a dual-stage process: initially, the parameter matrix of each fully-connected layer undergoes quantization into a matrix of low-bit integers and a scalar vector; subsequently, fine-tuning occurs on the scalar vector for each downstream task. Such a strategy compresses the size of the model considerably, leading to a lower inference latency upon deployment and a reduction in the overall memory required. At the same time, fast fine-tuning and efficient task switching becomes possible. In this way, PEQA offers the benefits of quantization, while inheriting the advantages of PEFT. We compare PEQA with competitive baselines in comprehensive experiments ranging from natural language understanding to generation benchmarks. This is done using large language models of up to $65$ billion parameters, demonstrating PEQA's scalability, task-specific adaptation performance, and ability to follow instructions, even in extremely low-bit settings.
Cluster-Promoting Quantization with Bit-Drop for Minimizing Network Quantization Loss
Sep 05, 2021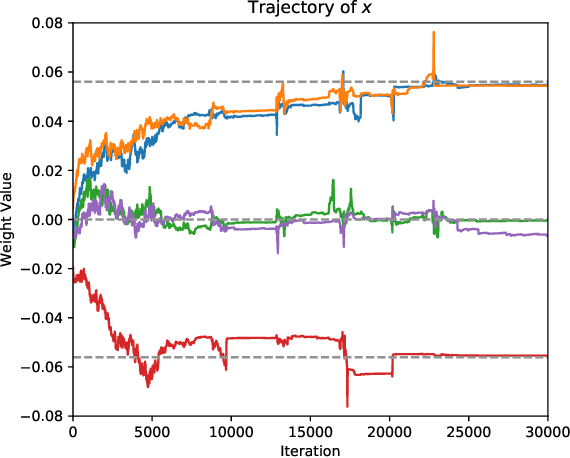
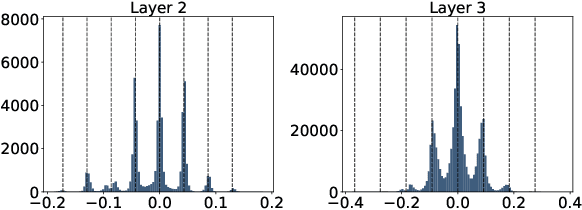
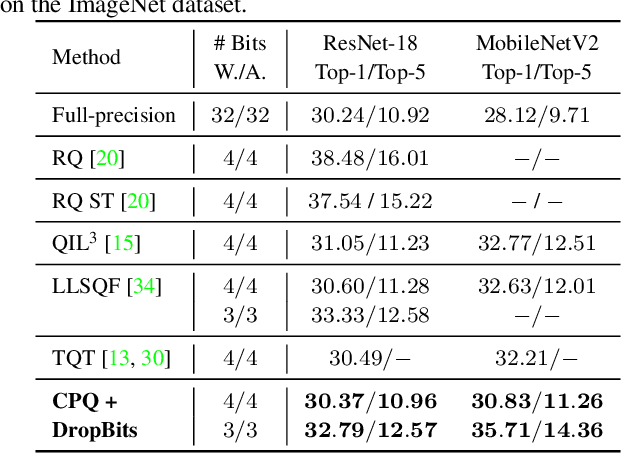
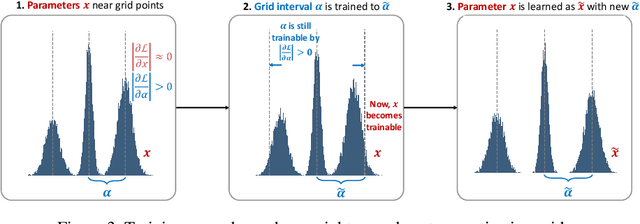
Network quantization, which aims to reduce the bit-lengths of the network weights and activations, has emerged for their deployments to resource-limited devices. Although recent studies have successfully discretized a full-precision network, they still incur large quantization errors after training, thus giving rise to a significant performance gap between a full-precision network and its quantized counterpart. In this work, we propose a novel quantization method for neural networks, Cluster-Promoting Quantization (CPQ) that finds the optimal quantization grids while naturally encouraging the underlying full-precision weights to gather around those quantization grids cohesively during training. This property of CPQ is thanks to our two main ingredients that enable differentiable quantization: i) the use of the categorical distribution designed by a specific probabilistic parametrization in the forward pass and ii) our proposed multi-class straight-through estimator (STE) in the backward pass. Since our second component, multi-class STE, is intrinsically biased, we additionally propose a new bit-drop technique, DropBits, that revises the standard dropout regularization to randomly drop bits instead of neurons. As a natural extension of DropBits, we further introduce the way of learning heterogeneous quantization levels to find proper bit-length for each layer by imposing an additional regularization on DropBits. We experimentally validate our method on various benchmark datasets and network architectures, and also support a new hypothesis for quantization: learning heterogeneous quantization levels outperforms the case using the same but fixed quantization levels from scratch.
Compressed Sensing via Measurement-Conditional Generative Models
Jul 02, 2020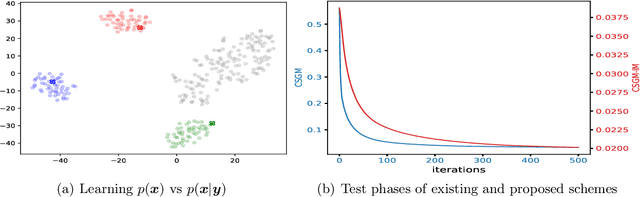
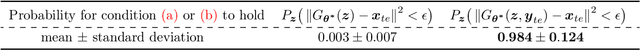
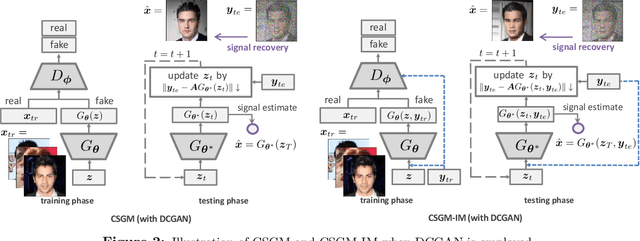
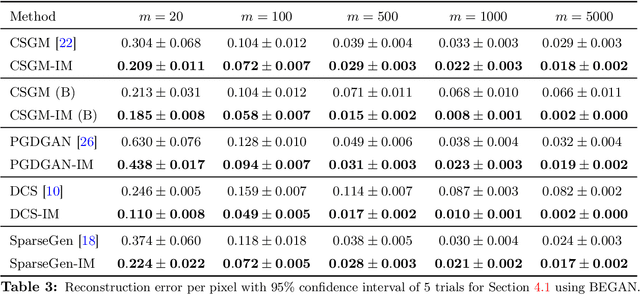
A pre-trained generator has been frequently adopted in compressed sensing (CS) due to its ability to effectively estimate signals with the prior of NNs. In order to further refine the NN-based prior, we propose a framework that allows the generator to learn measurement-specific prior distribution, yielding more accurate prediction on a measurement. Our framework has a simple form that only utilizes additional information from a given measurement for prior learning, so it can be easily applied to existing methods. Despite its simplicity, we demonstrate through extensive experiments that our framework exhibits uniformly superior performances by large margin and can reduce the reconstruction error up to an order of magnitude for some applications. We also explain the experimental success in theory by showing that our framework can slightly relax the stringent signal presence condition, which is required to guarantee the success of signal recovery.
Semi-Relaxed Quantization with DropBits: Training Low-Bit Neural Networks via Bit-wise Regularization
Nov 29, 2019
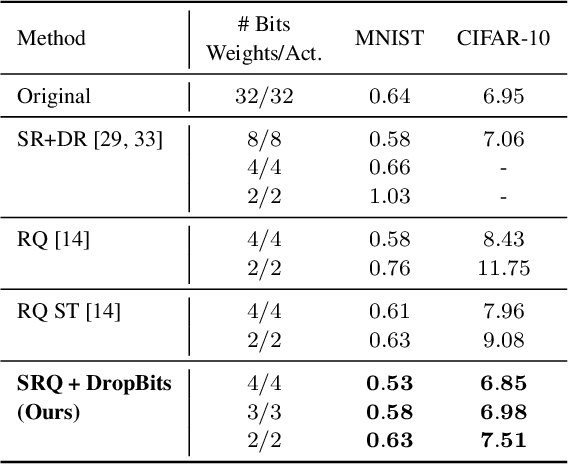
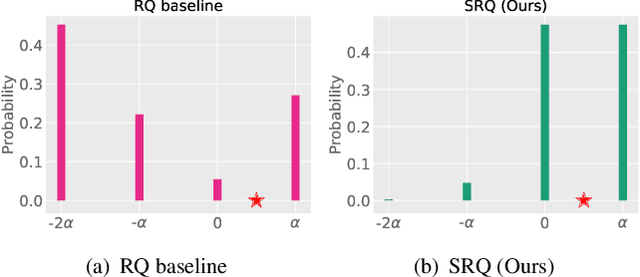
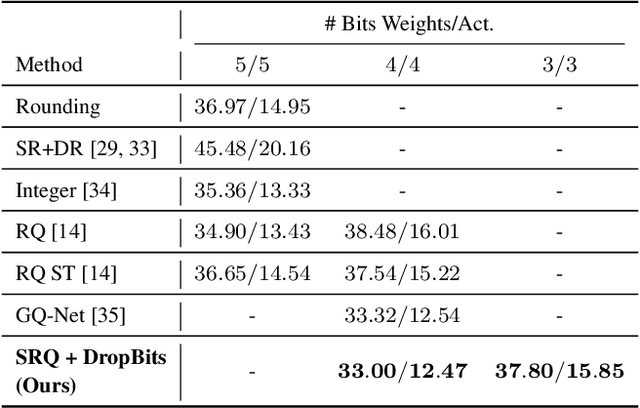
Neural Network quantization, which aims to reduce bit-lengths of the network weights and activations, is one of the key ingredients to reduce the size of neural networks for their deployments to resource-limited devices. However, compressing to low bit-lengths may incur large loss of information and preserving the performance of the full-precision networks under these settings is extremely challenging even with the state-of-the-art quantization approaches. To tackle this problem of low-bit quantization, we propose a novel Semi-Relaxed Quantization (SRQ) that can effectively reduce the quantization error, along with a new regularization technique, DropBits which replaces dropout regularization to randomly drop the bits instead of neurons to minimize information loss while improving generalization on low-bit networks. Moreover, we show the possibility of learning heterogeneous quantization levels, that finds proper bit-lengths for each layer using DropBits. We experimentally validate our method on various benchmark datasets and network architectures, whose results show that our method largely outperforms recent quantization approaches. To the best of our knowledge, we are the first in obtaining competitive performance on 3-bit quantization of ResNet-18 on ImageNet dataset with both weights and activations quantized, across all layers. Last but not the least, we show promising results on heterogeneous quantization, which we believe will open the door to new research directions in neural network quantization.