 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning and Distilling Mixture-of-Experts into Dense Language Models
May 27, 2026Mixture-of-Experts (MoE) is now the dominant architecture for frontier language models, yet it requires all expert parameters to be loaded in memory, making it less preferable for memory-constrained deployment. Existing compression methods reduce the number of experts but the output remains an MoE model with the same fundamental limitation. We present the first systematic framework for converting a trained MoE into a standard fully dense architecture: experts are scored, selected, and grouped, then concatenated into a dense FFN and refined by knowledge distillation from the MoE teacher. We evaluate 7 scoring, 5 grouping, and 2 magnitude scaling methods across a range of selected expert counts on Qwen3-30B-A3B, yielding 350 configurations. We find that the choice of scoring method is the most impactful, with our novel diversity-aware scoring consistently outperforming prior methods on Qwen3-30B-A3B, DeepSeek-V2-Lite, and GPT-OSS-20B. Under a controlled comparison at matched parameter count, MoE-to-dense outperforms dense-to-dense pruning by +6.3 pp in average downstream accuracy after ~4B-token distillation at 1.6x faster training wall-clock speed.
AMUSE: Anytime Muon with Stable Gradient Evaluation
May 21, 2026Modern deep learning commonly relies on AdamW with prescribed learning rate schedules, but recent works challenge both components: Schedule-Free optimization removes explicit schedules via iterate averaging, and Muon improves the update geometry by orthogonalizing momentum for matrix parameters. Despite Muon's strong empirical performance, its underlying mechanism remains partially understood. We study Muon through the river-valley loss landscape, where useful training progress occurs along a flat, low-curvature bulk subspace (the river), while high-curvature dominant directions form steep valley walls that induce oscillations. We empirically show that while Muon's orthogonalization accelerates river progress by increasing the bulk component, it also amplifies dominant-direction noise, causing oscillatory trajectories. Building on this, we propose Anytime MUon with Stable gradient Evaluation (AMUSE), which integrates Muon's rapid bulk progress with the stabilizing effect of Schedule-Free averaging. AMUSE uses a time-varying interpolation coefficient that initially evaluates gradients near the fast Muon sequence for rapid adaptation, then gradually shifts toward the stable averaged sequence to suppress valley-wall oscillations. As a result, AMUSE requires no learning rate schedules and supports anytime training. Across vision tasks and large language model pretraining, AMUSE consistently improves the performance-iteration Pareto frontier over (Schedule-Free) AdamW and Muon.
Uniform Spectral Growth and Convergence of Muon in LoRA-Style Matrix Factorization
Feb 06, 2026Spectral gradient descent (SpecGD) orthogonalizes the matrix parameter updates and has inspired practical optimizers such as Muon. They often perform well in large language model (LLM) training, but their dynamics remain poorly understood. In the low-rank adaptation (LoRA) setting, where weight updates are parameterized as a product of two low-rank factors, we find a distinctive spectral phenomenon under Muon in LoRA fine-tuning of LLMs: singular values of the LoRA product show near-uniform growth across the spectrum, despite orthogonalization being performed on the two factors separately. Motivated by this observation, we analyze spectral gradient flow (SpecGF)-a continuous-time analogue of SpecGD-in a simplified LoRA-style matrix factorization setting and prove "equal-rate" dynamics: all singular values grow at equal rates up to small deviations. Consequently, smaller singular values attain their target values earlier than larger ones, sharply contrasting with the largest-first stepwise learning observed in standard gradient flow. Moreover, we prove that SpecGF in our setting converges to global minima from almost all initializations, provided the factor norms remain bounded; with $\ell_2$ regularization, we obtain global convergence. Lastly, we corroborate our theory with experiments in the same setting.
THINKSAFE: Self-Generated Safety Alignment for Reasoning Models
Jan 30, 2026Large reasoning models (LRMs) achieve remarkable performance by leveraging reinforcement learning (RL) on reasoning tasks to generate long chain-of-thought (CoT) reasoning. However, this over-optimization often prioritizes compliance, making models vulnerable to harmful prompts. To mitigate this safety degradation, recent approaches rely on external teacher distillation, yet this introduces a distributional discrepancy that degrades native reasoning. We propose ThinkSafe, a self-generated alignment framework that restores safety alignment without external teachers. Our key insight is that while compliance suppresses safety mechanisms, models often retain latent knowledge to identify harm. ThinkSafe unlocks this via lightweight refusal steering, guiding the model to generate in-distribution safety reasoning traces. Fine-tuning on these self-generated responses effectively realigns the model while minimizing distribution shift. Experiments on DeepSeek-R1-Distill and Qwen3 show ThinkSafe significantly improves safety while preserving reasoning proficiency. Notably, it achieves superior safety and comparable reasoning to GRPO, with significantly reduced computational cost. Code, models, and datasets are available at https://github.com/seanie12/ThinkSafe.git.
Coverage Improvement and Fast Convergence of On-policy Preference Learning
Jan 13, 2026Online on-policy preference learning algorithms for language model alignment such as online direct policy optimization (DPO) can significantly outperform their offline counterparts. We provide a theoretical explanation for this phenomenon by analyzing how the sampling policy's coverage evolves throughout on-policy training. We propose and rigorously justify the \emph{coverage improvement principle}: with sufficient batch size, each update moves into a region around the target where coverage is uniformly better, making subsequent data increasingly informative and enabling rapid convergence. In the contextual bandit setting with Bradley-Terry preferences and linear softmax policy class, we show that on-policy DPO converges exponentially in the number of iterations for batch size exceeding a generalized coverage threshold. In contrast, any learner restricted to offline samples from the initial policy suffers a slower minimax rate, leading to a sharp separation in total sample complexity. Motivated by this analysis, we further propose a simple hybrid sampler based on a novel \emph{preferential} G-optimal design, which removes dependence on coverage and guarantees convergence in just two rounds. Finally, we develop principled on-policy schemes for reward distillation in the general function class setting, and show faster noiseless rates under an alternative deviation-based notion of coverage. Experimentally, we confirm that on-policy DPO and our proposed reward distillation algorithms outperform their off-policy counterparts and enjoy stable, monotonic performance gains across iterations.
Unraveling Zeroth-Order Optimization through the Lens of Low-Dimensional Structured Perturbations
Jan 31, 2025Zeroth-order (ZO) optimization has emerged as a promising alternative to gradient-based backpropagation methods, particularly for black-box optimization and large language model (LLM) fine-tuning. However, ZO methods suffer from slow convergence due to high-variance stochastic gradient estimators. While structured perturbations, such as sparsity and low-rank constraints, have been explored to mitigate these issues, their effectiveness remains highly under-explored. In this work, we develop a unified theoretical framework that analyzes both the convergence and generalization properties of ZO optimization under structured perturbations. We show that high dimensionality is the primary bottleneck and introduce the notions of \textit{stable rank} and \textit{effective overlap} to explain how structured perturbations reduce gradient noise and accelerate convergence. Using the uniform stability under our framework, we then provide the first theoretical justification for why these perturbations enhance generalization. Additionally, through empirical analysis, we identify that \textbf{block coordinate descent} (BCD) to be an effective structured perturbation method. Extensive experiments show that, compared to existing alternatives, memory-efficient ZO (MeZO) with BCD (\textit{MeZO-BCD}) can provide improved converge with a faster wall-clock time/iteration by up to $\times\textbf{2.09}$ while yielding similar or better accuracy.
LANTERN: Accelerating Visual Autoregressive Models with Relaxed Speculative Decoding
Oct 04, 2024


Auto-Regressive (AR) models have recently gained prominence in image generation, often matching or even surpassing the performance of diffusion models. However, one major limitation of AR models is their sequential nature, which processes tokens one at a time, slowing down generation compared to models like GANs or diffusion-based methods that operate more efficiently. While speculative decoding has proven effective for accelerating LLMs by generating multiple tokens in a single forward, its application in visual AR models remains largely unexplored. In this work, we identify a challenge in this setting, which we term \textit{token selection ambiguity}, wherein visual AR models frequently assign uniformly low probabilities to tokens, hampering the performance of speculative decoding. To overcome this challenge, we propose a relaxed acceptance condition referred to as LANTERN that leverages the interchangeability of tokens in latent space. This relaxation restores the effectiveness of speculative decoding in visual AR models by enabling more flexible use of candidate tokens that would otherwise be prematurely rejected. Furthermore, by incorporating a total variation distance bound, we ensure that these speed gains are achieved without significantly compromising image quality or semantic coherence. Experimental results demonstrate the efficacy of our method in providing a substantial speed-up over speculative decoding. In specific, compared to a na\"ive application of the state-of-the-art speculative decoding, LANTERN increases speed-ups by $\mathbf{1.75}\times$ and $\mathbf{1.76}\times$, as compared to greedy decoding and random sampling, respectively, when applied to LlamaGen, a contemporary visual AR model.
TEDDY: Trimming Edges with Degree-based Discrimination strategY
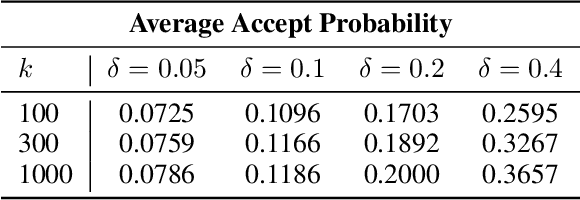
Feb 02, 2024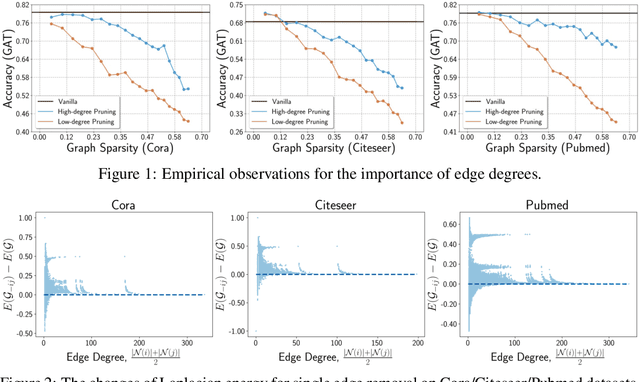
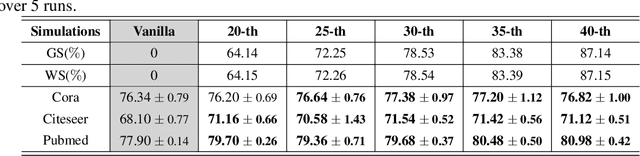
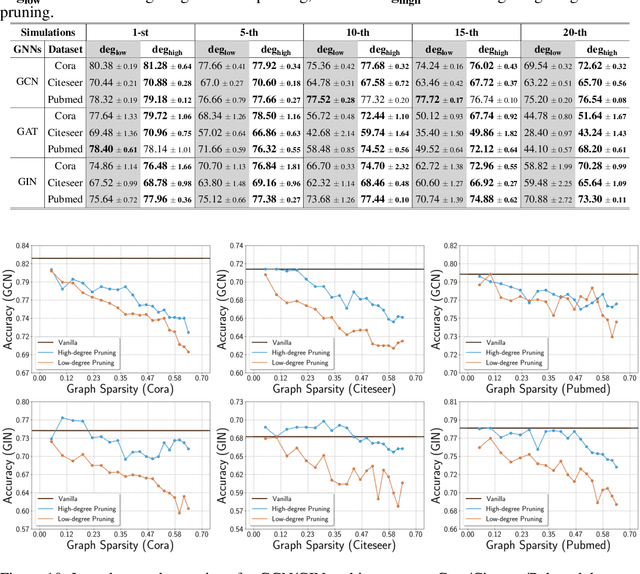
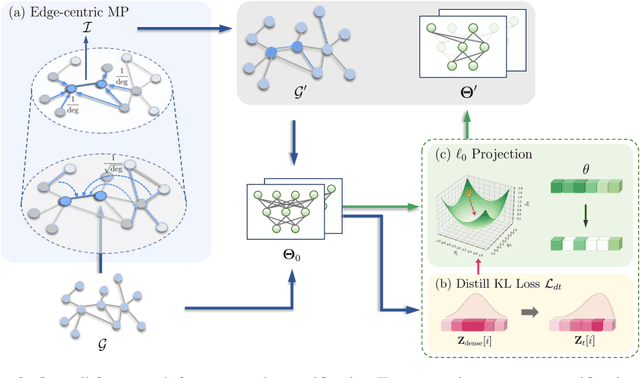
Since the pioneering work on the lottery ticket hypothesis for graph neural networks (GNNs) was proposed in Chen et al. (2021), the study on finding graph lottery tickets (GLT) has become one of the pivotal focus in the GNN community, inspiring researchers to discover sparser GLT while achieving comparable performance to original dense networks. In parallel, the graph structure has gained substantial attention as a crucial factor in GNN training dynamics, also elucidated by several recent studies. Despite this, contemporary studies on GLT, in general, have not fully exploited inherent pathways in the graph structure and identified tickets in an iterative manner, which is time-consuming and inefficient. To address these limitations, we introduce TEDDY, a one-shot edge sparsification framework that leverages structural information by incorporating edge-degree information. Following edge sparsification, we encourage the parameter sparsity during training via simple projected gradient descent on the $\ell_0$ ball. Given the target sparsity levels for both the graph structure and the model parameters, our TEDDY facilitates efficient and rapid realization of GLT within a single training. Remarkably, our experimental results demonstrate that TEDDY significantly surpasses conventional iterative approaches in generalization, even when conducting one-shot sparsification that solely utilizes graph structures, without taking node features into account.
Cluster-Promoting Quantization with Bit-Drop for Minimizing Network Quantization Loss
Sep 05, 2021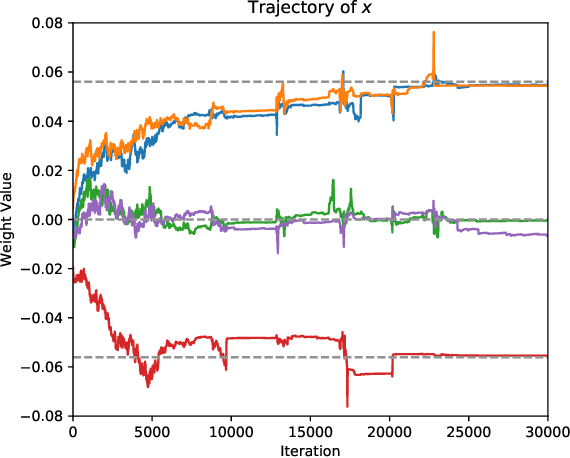
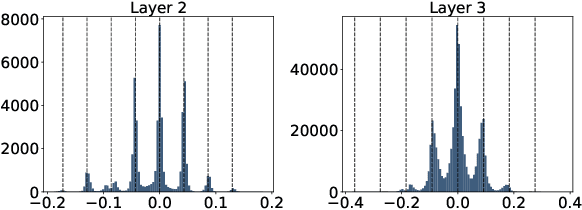
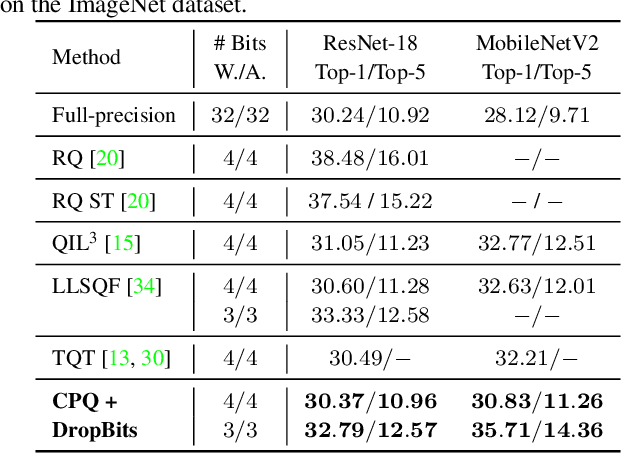
Network quantization, which aims to reduce the bit-lengths of the network weights and activations, has emerged for their deployments to resource-limited devices. Although recent studies have successfully discretized a full-precision network, they still incur large quantization errors after training, thus giving rise to a significant performance gap between a full-precision network and its quantized counterpart. In this work, we propose a novel quantization method for neural networks, Cluster-Promoting Quantization (CPQ) that finds the optimal quantization grids while naturally encouraging the underlying full-precision weights to gather around those quantization grids cohesively during training. This property of CPQ is thanks to our two main ingredients that enable differentiable quantization: i) the use of the categorical distribution designed by a specific probabilistic parametrization in the forward pass and ii) our proposed multi-class straight-through estimator (STE) in the backward pass. Since our second component, multi-class STE, is intrinsically biased, we additionally propose a new bit-drop technique, DropBits, that revises the standard dropout regularization to randomly drop bits instead of neurons. As a natural extension of DropBits, we further introduce the way of learning heterogeneous quantization levels to find proper bit-length for each layer by imposing an additional regularization on DropBits. We experimentally validate our method on various benchmark datasets and network architectures, and also support a new hypothesis for quantization: learning heterogeneous quantization levels outperforms the case using the same but fixed quantization levels from scratch.
A General Family of Stochastic Proximal Gradient Methods for Deep Learning
Jul 15, 2020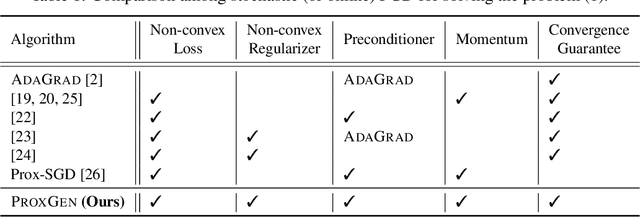
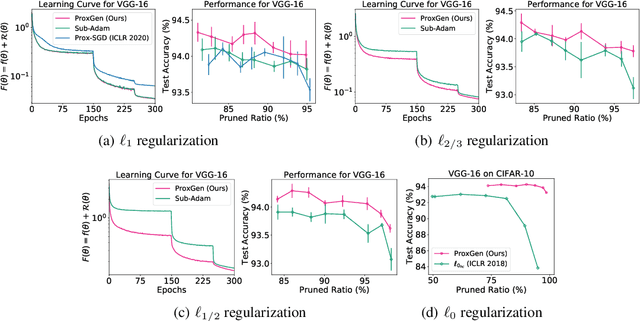

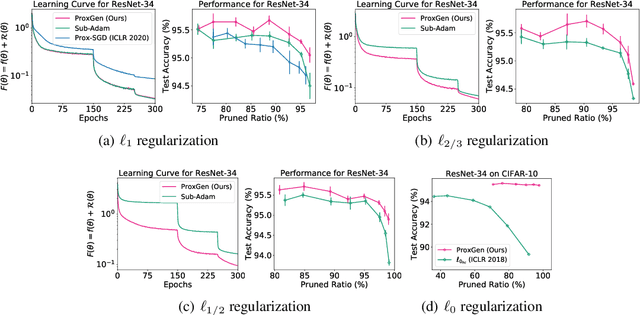
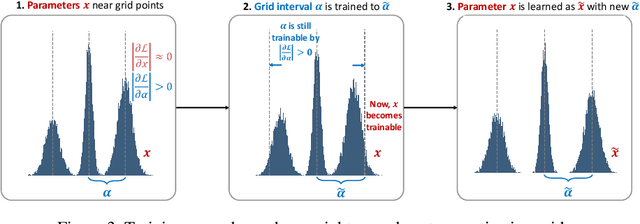
We study the training of regularized neural networks where the regularizer can be non-smooth and non-convex. We propose a unified framework for stochastic proximal gradient descent, which we term ProxGen, that allows for arbitrary positive preconditioners and lower semi-continuous regularizers. Our framework encompasses standard stochastic proximal gradient methods without preconditioners as special cases, which have been extensively studied in various settings. Not only that, we present two important update rules beyond the well-known standard methods as a byproduct of our approach: (i) the first closed-form proximal mappings of $\ell_q$ regularization ($0 \leq q \leq 1$) for adaptive stochastic gradient methods, and (ii) a revised version of ProxQuant that fixes a caveat of the original approach for quantization-specific regularizers. We analyze the convergence of ProxGen and show that the whole family of ProxGen enjoys the same convergence rate as stochastic proximal gradient descent without preconditioners. We also empirically show the superiority of proximal methods compared to subgradient-based approaches via extensive experiments. Interestingly, our results indicate that proximal methods with non-convex regularizers are more effective than those with convex regularizers.