 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Model is Stubborn: Diagnosing Instruction Overriding in Reasoning Models
May 22, 2025


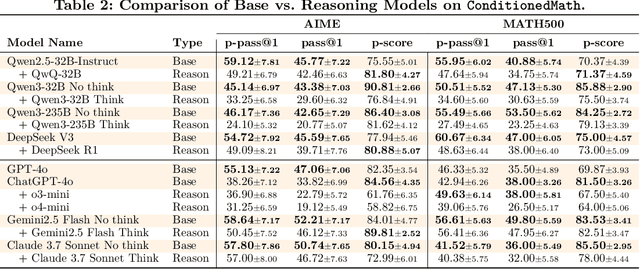
Large language models have demonstrated remarkable proficiency in long and complex reasoning tasks. However, they frequently exhibit a problematic reliance on familiar reasoning patterns, a phenomenon we term \textit{reasoning rigidity}. Despite explicit instructions from users, these models often override clearly stated conditions and default to habitual reasoning trajectories, leading to incorrect conclusions. This behavior presents significant challenges, particularly in domains such as mathematics and logic puzzle, where precise adherence to specified constraints is critical. To systematically investigate reasoning rigidity, a behavior largely unexplored in prior work, we introduce a expert-curated diagnostic set, \dataset{}. Our dataset includes specially modified variants of existing mathematical benchmarks, namely AIME and MATH500, as well as well-known puzzles deliberately redesigned to require deviation from familiar reasoning strategies. Using this dataset, we identify recurring contamination patterns that occur when models default to ingrained reasoning. Specifically, we categorize this contamination into three distinctive modes: (i) Interpretation Overload, (ii) Input Distrust, and (iii) Partial Instruction Attention, each causing models to ignore or distort provided instructions. We publicly release our diagnostic set to facilitate future research on mitigating reasoning rigidity in language models.
LANTERN++: Enhanced Relaxed Speculative Decoding with Static Tree Drafting for Visual Auto-regressive Models
Feb 10, 2025



Speculative decoding has been widely used to accelerate autoregressive (AR) text generation. However, its effectiveness in visual AR models remains limited due to token selection ambiguity, where multiple tokens receive similarly low probabilities, reducing acceptance rates. While dynamic tree drafting has been proposed to improve speculative decoding, we show that it fails to mitigate token selection ambiguity, resulting in shallow draft trees and suboptimal acceleration. To address this, we introduce LANTERN++, a novel framework that integrates static tree drafting with a relaxed acceptance condition, allowing drafts to be selected independently of low-confidence predictions. This enables deeper accepted sequences, improving decoding efficiency while preserving image quality. Extensive experiments on state-of-the-art visual AR models demonstrate that LANTERN++ significantly accelerates inference, achieving up to $\mathbf{\times 2.56}$ speedup over standard AR decoding while maintaining high image quality.
Med-PerSAM: One-Shot Visual Prompt Tuning for Personalized Segment Anything Model in Medical Domain
Nov 25, 2024Leveraging pre-trained models with tailored prompts for in-context learning has proven highly effective in NLP tasks. Building on this success, recent studies have applied a similar approach to the Segment Anything Model (SAM) within a ``one-shot" framework, where only a single reference image and its label are employed. However, these methods face limitations in the medical domain, primarily due to SAM's essential requirement for visual prompts and the over-reliance on pixel similarity for generating them. This dependency may lead to (1) inaccurate prompt generation and (2) clustering of point prompts, resulting in suboptimal outcomes. To address these challenges, we introduce \textbf{Med-PerSAM}, a novel and straightforward one-shot framework designed for the medical domain. Med-PerSAM uses only visual prompt engineering and eliminates the need for additional training of the pretrained SAM or human intervention, owing to our novel automated prompt generation process. By integrating our lightweight warping-based prompt tuning model with SAM, we enable the extraction and iterative refinement of visual prompts, enhancing the performance of the pre-trained SAM. This advancement is particularly meaningful in the medical domain, where creating visual prompts poses notable challenges for individuals lacking medical expertise. Our model outperforms various foundational models and previous SAM-based approaches across diverse 2D medical imaging datasets.
LANTERN: Accelerating Visual Autoregressive Models with Relaxed Speculative Decoding
Oct 04, 2024


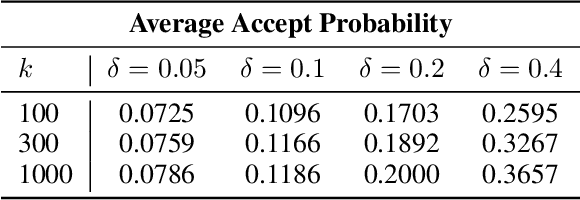
Auto-Regressive (AR) models have recently gained prominence in image generation, often matching or even surpassing the performance of diffusion models. However, one major limitation of AR models is their sequential nature, which processes tokens one at a time, slowing down generation compared to models like GANs or diffusion-based methods that operate more efficiently. While speculative decoding has proven effective for accelerating LLMs by generating multiple tokens in a single forward, its application in visual AR models remains largely unexplored. In this work, we identify a challenge in this setting, which we term \textit{token selection ambiguity}, wherein visual AR models frequently assign uniformly low probabilities to tokens, hampering the performance of speculative decoding. To overcome this challenge, we propose a relaxed acceptance condition referred to as LANTERN that leverages the interchangeability of tokens in latent space. This relaxation restores the effectiveness of speculative decoding in visual AR models by enabling more flexible use of candidate tokens that would otherwise be prematurely rejected. Furthermore, by incorporating a total variation distance bound, we ensure that these speed gains are achieved without significantly compromising image quality or semantic coherence. Experimental results demonstrate the efficacy of our method in providing a substantial speed-up over speculative decoding. In specific, compared to a na\"ive application of the state-of-the-art speculative decoding, LANTERN increases speed-ups by $\mathbf{1.75}\times$ and $\mathbf{1.76}\times$, as compared to greedy decoding and random sampling, respectively, when applied to LlamaGen, a contemporary visual AR model.
PromptKD: Distilling Student-Friendly Knowledge for Generative Language Models via Prompt Tuning
Feb 20, 2024Recent advancements in large language models (LLMs) have raised concerns about inference costs, increasing the need for research into model compression. While knowledge distillation (KD) is a prominent method for this, research on KD for generative language models like LLMs is relatively sparse, and the approach of distilling student-friendly knowledge, which has shown promising performance in KD for classification models, remains unexplored in generative language models. To explore this approach, we propose PromptKD, a simple yet effective method that utilizes prompt tuning - for the first time in KD - to enable generative language models to transfer student-friendly knowledge. Unlike previous works in classification that require fine-tuning the entire teacher model for extracting student-friendly knowledge, PromptKD achieves similar effects by adding a small number of prompt tokens and tuning only the prompt with student guidance. Extensive experiments on instruction-following datasets using the GPT-2 model family show that PromptKD achieves state-of-the-art performance while adding only 0.0007% of the teacher's parameters as prompts. Further analysis suggests that distilling student-friendly knowledge alleviates exposure bias effectively throughout the entire training process, leading to performance enhancements.