 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Model is Stubborn: Diagnosing Instruction Overriding in Reasoning Models
May 22, 2025


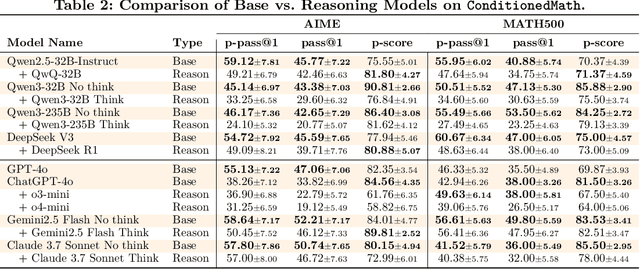
Large language models have demonstrated remarkable proficiency in long and complex reasoning tasks. However, they frequently exhibit a problematic reliance on familiar reasoning patterns, a phenomenon we term \textit{reasoning rigidity}. Despite explicit instructions from users, these models often override clearly stated conditions and default to habitual reasoning trajectories, leading to incorrect conclusions. This behavior presents significant challenges, particularly in domains such as mathematics and logic puzzle, where precise adherence to specified constraints is critical. To systematically investigate reasoning rigidity, a behavior largely unexplored in prior work, we introduce a expert-curated diagnostic set, \dataset{}. Our dataset includes specially modified variants of existing mathematical benchmarks, namely AIME and MATH500, as well as well-known puzzles deliberately redesigned to require deviation from familiar reasoning strategies. Using this dataset, we identify recurring contamination patterns that occur when models default to ingrained reasoning. Specifically, we categorize this contamination into three distinctive modes: (i) Interpretation Overload, (ii) Input Distrust, and (iii) Partial Instruction Attention, each causing models to ignore or distort provided instructions. We publicly release our diagnostic set to facilitate future research on mitigating reasoning rigidity in language models.
Augmentation-Driven Metric for Balancing Preservation and Modification in Text-Guided Image Editing
Oct 15, 2024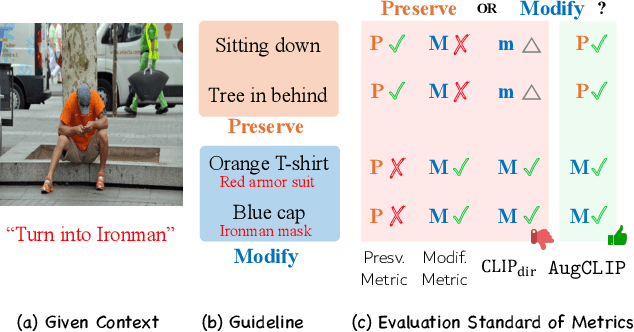

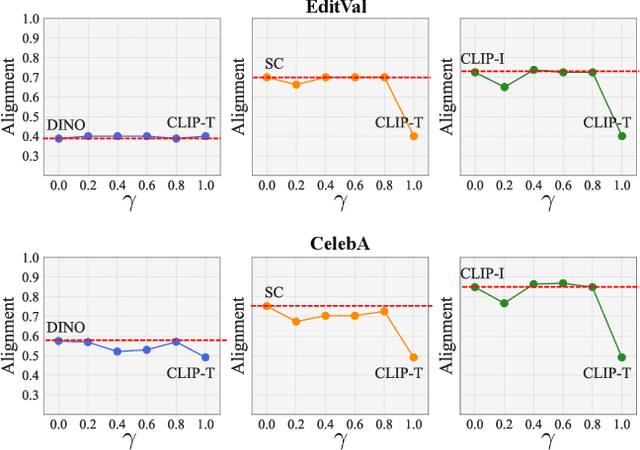
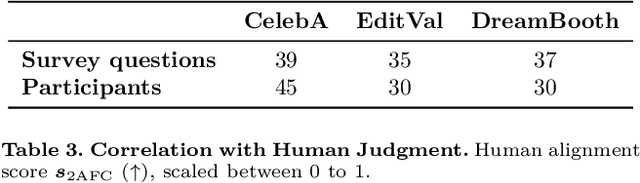
The development of vision-language and generative models has significantly advanced text-guided image editing, which seeks \textit{preservation} of core elements in the source image while implementing \textit{modifications} based on the target text. However, in the absence of evaluation metrics specifically tailored for text-guided image editing, existing metrics are limited in balancing the consideration of preservation and modification. Especially, our analysis reveals that CLIPScore, the most commonly used metric, tends to favor modification and ignore core attributes to be preserved, resulting in inaccurate evaluations. To address this problem, we propose \texttt{AugCLIP}, \black{which balances preservation and modification by estimating the representation of an ideal edited image that aligns with the target text with minimum alteration on the source image. We augment detailed textual descriptions on the source image and the target text using a multi-modal large language model, to model a hyperplane that separates CLIP space into source or target. The representation of the ideal edited image is an orthogonal projection of the source image into the hyperplane, which encapsulates the relative importance of each attribute considering the interdependent relationships.} Our extensive experiments on five benchmark datasets, encompassing a diverse range of editing scenarios, demonstrate that \texttt{AugCLIP} aligns remarkably well with human evaluation standards compared to existing metrics. The code for evaluation will be open-sourced to contribute to the community.
Learning Input-agnostic Manipulation Directions in StyleGAN with Text Guidance
Feb 26, 2023With the advantages of fast inference and human-friendly flexible manipulation, image-agnostic style manipulation via text guidance enables new applications that were not previously available. The state-of-the-art text-guided image-agnostic manipulation method embeds the representation of each channel of StyleGAN independently in the Contrastive Language-Image Pre-training (CLIP) space, and provides it in the form of a Dictionary to quickly find out the channel-wise manipulation direction during inference time. However, in this paper we argue that this dictionary which is constructed by controlling single channel individually is limited to accommodate the versatility of text guidance since the collective and interactive relation among multiple channels are not considered. Indeed, we show that it fails to discover a large portion of manipulation directions that can be found by existing methods, which manually manipulates latent space without texts. To alleviate this issue, we propose a novel method that learns a Dictionary, whose entry corresponds to the representation of a single channel, by taking into account the manipulation effect coming from the interaction with multiple other channels. We demonstrate that our strategy resolves the inability of previous methods in finding diverse known directions from unsupervised methods and unknown directions from random text while maintaining the real-time inference speed and disentanglement ability.
Music2Video: Automatic Generation of Music Video with fusion of audio and text
Jan 11, 2022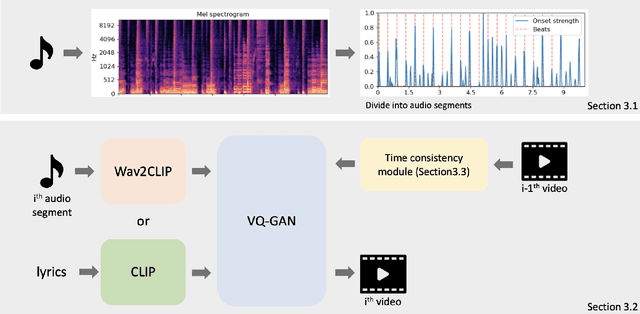


Creation of images using generative adversarial networks has been widely adapted into multi-modal regime with the advent of multi-modal representation models pre-trained on large corpus. Various modalities sharing a common representation space could be utilized to guide the generative models to create images from text or even from audio source. Departing from the previous methods that solely rely on either text or audio, we exploit the expressiveness of both modality. Based on the fusion of text and audio, we create video whose content is consistent with the distinct modalities that are provided. A simple approach to automatically segment the video into variable length intervals and maintain time consistency in generated video is part of our method. Our proposed framework for generating music video shows promising results in application level where users can interactively feed in music source and text source to create artistic music videos. Our code is available at https://github.com/joeljang/music2video.
Sequential Targeting: an incremental learning approach for data imbalance in text classification
Nov 23, 2020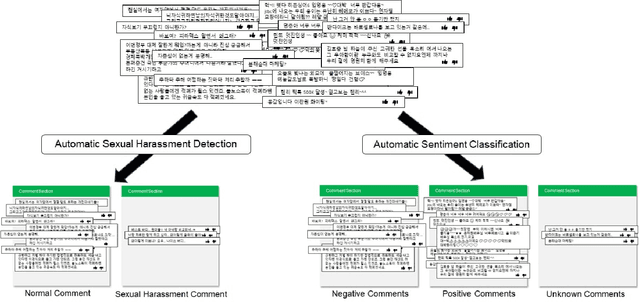
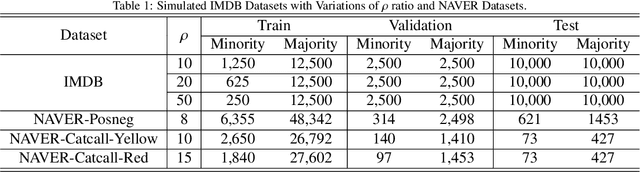
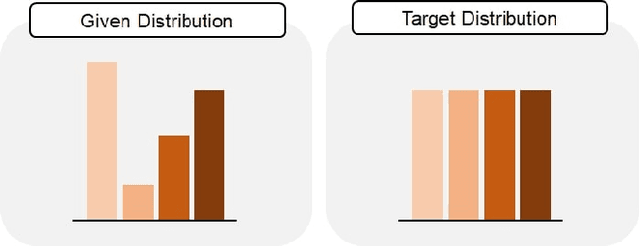
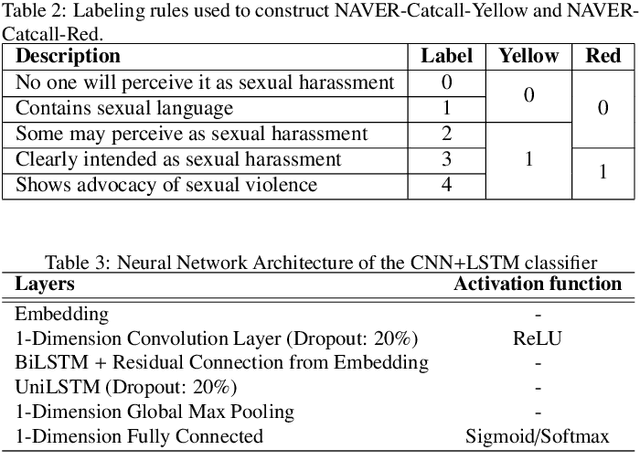
Classification tasks require a balanced distribution of data to ensure the learner to be trained to generalize over all classes. In real-world datasets, however, the number of instances vary substantially among classes. This typically leads to a learner that promotes bias towards the majority group due to its dominating property. Therefore, methods to handle imbalanced datasets are crucial for alleviating distributional skews and fully utilizing the under-represented data, especially in text classification. While addressing the imbalance in text data, most methods utilize sampling methods on the numerical representation of the data, which limits its efficiency on how effective the representation is. We propose a novel training method, Sequential Targeting(ST), independent of the effectiveness of the representation method, which enforces an incremental learning setting by splitting the data into mutually exclusive subsets and training the learner adaptively. To address problems that arise within incremental learning, we apply elastic weight consolidation. We demonstrate the effectiveness of our method through experiments on simulated benchmark datasets (IMDB) and data collected from NAVER.