 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding World Simulation Models in a Real-World Metropolis
Mar 16, 2026What if a world simulation model could render not an imagined environment but a city that actually exists? Prior generative world models synthesize visually plausible yet artificial environments by imagining all content. We present Seoul World Model (SWM), a city-scale world model grounded in the real city of Seoul. SWM anchors autoregressive video generation through retrieval-augmented conditioning on nearby street-view images. However, this design introduces several challenges, including temporal misalignment between retrieved references and the dynamic target scene, limited trajectory diversity and data sparsity from vehicle-mounted captures at sparse intervals. We address these challenges through cross-temporal pairing, a large-scale synthetic dataset enabling diverse camera trajectories, and a view interpolation pipeline that synthesizes coherent training videos from sparse street-view images. We further introduce a Virtual Lookahead Sink to stabilize long-horizon generation by continuously re-grounding each chunk to a retrieved image at a future location. We evaluate SWM against recent video world models across three cities: Seoul, Busan, and Ann Arbor. SWM outperforms existing methods in generating spatially faithful, temporally consistent, long-horizon videos grounded in actual urban environments over trajectories reaching hundreds of meters, while supporting diverse camera movements and text-prompted scenario variations.
CAPA: Contribution-Aware Pruning and FFN Approximation for Efficient Large Vision-Language Models
Jan 30, 2026Efficient inference in Large Vision-Language Models is constrained by the high cost of processing thousands of visual tokens, yet it remains unclear which tokens and computations can be safely removed. While attention scores are commonly used to estimate visual token importance, they are an imperfect proxy for actual contribution. We show that Attention Contribution, which weights attention probabilities by value vector magnitude, provides a more accurate criterion for visual token selection. Our empirical analysis reveals that visual attention sinks are functionally heterogeneous, comprising Probability Dumps with low contribution that can be safely pruned, and Structural Anchors with high contribution essential for maintaining model performance. Further, we identify substantial redundancy in Feed-Forward Networks (FFNs) associated with visual tokens, particularly in intermediate layers where image tokens exhibit linear behavior. Based on our findings, we introduce CAPA (Contribution-Aware Pruning and FFN Approximation), a dual-strategy framework that prunes visual tokens using attention contribution at critical functional transitions and reduces FFN computation through efficient linear approximations. Experiments on various benchmarks across baselines show that CAPA achieves competent efficiency--performance trade-offs with improved robustness.
Video Parallel Scaling: Aggregating Diverse Frame Subsets for VideoLLMs
Sep 09, 2025



Video Large Language Models (VideoLLMs) face a critical bottleneck: increasing the number of input frames to capture fine-grained temporal detail leads to prohibitive computational costs and performance degradation from long context lengths. We introduce Video Parallel Scaling (VPS), an inference-time method that expands a model's perceptual bandwidth without increasing its context window. VPS operates by running multiple parallel inference streams, each processing a unique, disjoint subset of the video's frames. By aggregating the output probabilities from these complementary streams, VPS integrates a richer set of visual information than is possible with a single pass. We theoretically show that this approach effectively contracts the Chinchilla scaling law by leveraging uncorrelated visual evidence, thereby improving performance without additional training. Extensive experiments across various model architectures and scales (2B-32B) on benchmarks such as Video-MME and EventHallusion demonstrate that VPS consistently and significantly improves performance. It scales more favorably than other parallel alternatives (e.g. Self-consistency) and is complementary to other decoding strategies, offering a memory-efficient and robust framework for enhancing the temporal reasoning capabilities of VideoLLMs.
Aligned Novel View Image and Geometry Synthesis via Cross-modal Attention Instillation
Jun 13, 2025We introduce a diffusion-based framework that performs aligned novel view image and geometry generation via a warping-and-inpainting methodology. Unlike prior methods that require dense posed images or pose-embedded generative models limited to in-domain views, our method leverages off-the-shelf geometry predictors to predict partial geometries viewed from reference images, and formulates novel-view synthesis as an inpainting task for both image and geometry. To ensure accurate alignment between generated images and geometry, we propose cross-modal attention distillation, where attention maps from the image diffusion branch are injected into a parallel geometry diffusion branch during both training and inference. This multi-task approach achieves synergistic effects, facilitating geometrically robust image synthesis as well as well-defined geometry prediction. We further introduce proximity-based mesh conditioning to integrate depth and normal cues, interpolating between point cloud and filtering erroneously predicted geometry from influencing the generation process. Empirically, our method achieves high-fidelity extrapolative view synthesis on both image and geometry across a range of unseen scenes, delivers competitive reconstruction quality under interpolation settings, and produces geometrically aligned colored point clouds for comprehensive 3D completion. Project page is available at https://cvlab-kaist.github.io/MoAI.
DIP-R1: Deep Inspection and Perception with RL Looking Through and Understanding Complex Scenes
May 29, 2025Multimodal Large Language Models (MLLMs) have demonstrated significant visual understanding capabilities, yet their fine-grained visual perception in complex real-world scenarios, such as densely crowded public areas, remains limited. Inspired by the recent success of reinforcement learning (RL) in both LLMs and MLLMs, in this paper, we explore how RL can enhance visual perception ability of MLLMs. Then we develop a novel RL-based framework, Deep Inspection and Perception with RL (DIP-R1) designed to enhance the visual perception capabilities of MLLMs, by comprehending complex scenes and looking through visual instances closely. DIP-R1 guides MLLMs through detailed inspection of visual scene via three simply designed rule-based reward modelings. First, we adopt a standard reasoning reward encouraging the model to include three step-by-step processes: 1) reasoning for understanding visual scenes, 2) observing for looking through interested but ambiguous regions, and 3) decision-making for predicting answer. Second, a variance-guided looking reward is designed to examine uncertain regions for the second observing process. It explicitly enables the model to inspect ambiguous areas, improving its ability to mitigate perceptual uncertainties. Third, we model a weighted precision-recall accuracy reward enhancing accurate decision-making. We explore its effectiveness across diverse fine-grained object detection data consisting of challenging real-world environments, such as densely crowded scenes. Built upon existing MLLMs, DIP-R1 achieves consistent and significant improvement across various in-domain and out-of-domain scenarios. It also outperforms various existing baseline models and supervised fine-tuning methods. Our findings highlight the substantial potential of integrating RL into MLLMs for enhancing capabilities in complex real-world perception tasks.
Enhancing Creative Generation on Stable Diffusion-based Models
Mar 30, 2025Recent text-to-image generative models, particularly Stable Diffusion and its distilled variants, have achieved impressive fidelity and strong text-image alignment. However, their creative capability remains constrained, as including `creative' in prompts seldom yields the desired results. This paper introduces C3 (Creative Concept Catalyst), a training-free approach designed to enhance creativity in Stable Diffusion-based models. C3 selectively amplifies features during the denoising process to foster more creative outputs. We offer practical guidelines for choosing amplification factors based on two main aspects of creativity. C3 is the first study to enhance creativity in diffusion models without extensive computational costs. We demonstrate its effectiveness across various Stable Diffusion-based models.
Learning 3D Scene Analogies with Neural Contextual Scene Maps
Mar 20, 2025



Understanding scene contexts is crucial for machines to perform tasks and adapt prior knowledge in unseen or noisy 3D environments. As data-driven learning is intractable to comprehensively encapsulate diverse ranges of layouts and open spaces, we propose teaching machines to identify relational commonalities in 3D spaces. Instead of focusing on point-wise or object-wise representations, we introduce 3D scene analogies, which are smooth maps between 3D scene regions that align spatial relationships. Unlike well-studied single instance-level maps, these scene-level maps smoothly link large scene regions, potentially enabling unique applications in trajectory transfer in AR/VR, long demonstration transfer for imitation learning, and context-aware object rearrangement. To find 3D scene analogies, we propose neural contextual scene maps, which extract descriptor fields summarizing semantic and geometric contexts, and holistically align them in a coarse-to-fine manner for map estimation. This approach reduces reliance on individual feature points, making it robust to input noise or shape variations. Experiments demonstrate the effectiveness of our approach in identifying scene analogies and transferring trajectories or object placements in diverse indoor scenes, indicating its potential for robotics and AR/VR applications.
DECOR:Decomposition and Projection of Text Embeddings for Text-to-Image Customization
Dec 12, 2024Text-to-image (T2I) models can effectively capture the content or style of reference images to perform high-quality customization. A representative technique for this is fine-tuning using low-rank adaptations (LoRA), which enables efficient model customization with reference images. However, fine-tuning with a limited number of reference images often leads to overfitting, resulting in issues such as prompt misalignment or content leakage. These issues prevent the model from accurately following the input prompt or generating undesired objects during inference. To address this problem, we examine the text embeddings that guide the diffusion model during inference. This study decomposes the text embedding matrix and conducts a component analysis to understand the embedding space geometry and identify the cause of overfitting. Based on this, we propose DECOR, which projects text embeddings onto a vector space orthogonal to undesired token vectors, thereby reducing the influence of unwanted semantics in the text embeddings. Experimental results demonstrate that DECOR outperforms state-of-the-art customization models and achieves Pareto frontier performance across text and visual alignment evaluation metrics. Furthermore, it generates images more faithful to the input prompts, showcasing its effectiveness in addressing overfitting and enhancing text-to-image customization.
Look Every Frame All at Once: Video-Ma$^2$mba for Efficient Long-form Video Understanding with Multi-Axis Gradient Checkpointing
Nov 29, 2024With the growing scale and complexity of video data, efficiently processing long video sequences poses significant challenges due to the quadratic increase in memory and computational demands associated with existing transformer-based Large Multi-modal Models (LMMs). To address these issues, we introduce Video-Ma$^2$mba, a novel architecture that incorporates State Space Models (SSMs) within the Mamba-2 framework, replacing the attention mechanisms. This allows the LMMs to scale linearly in terms of time and memory requirements, making it feasible to handle long-duration video content. Furthermore, we enhance the memory efficiency introducing the Multi-Axis Gradient Checkpointing (MA-GC) method, which strategically manages memory by retaining only essential activations across multiple computational axes. Our approach significantly reduces the memory footprint compared to standard gradient checkpointing. Empirical analyses show that Video-Ma$^2$mba can process extensive video sequences-equivalent to millions of tokens or over two hours of continuous sequences at 1 FPS-on a single GPU. By maintaining a detailed capture of temporal dynamics, our model improves the accuracy and relevance of responses in long video understanding tasks, demonstrating substantial advantages over existing frameworks.
SALOVA: Segment-Augmented Long Video Assistant for Targeted Retrieval and Routing in Long-Form Video Analysis
Nov 25, 2024

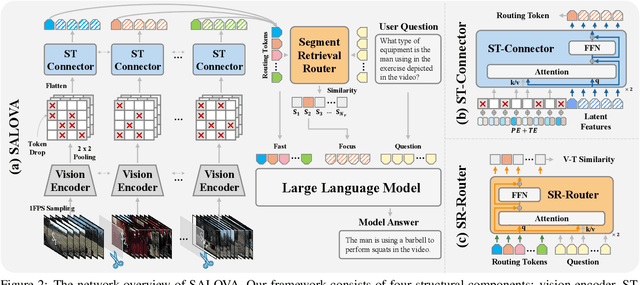
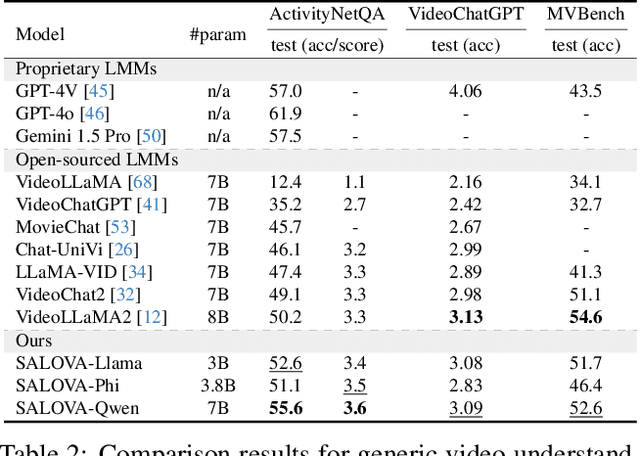
Despite advances in Large Multi-modal Models, applying them to long and untrimmed video content remains challenging due to limitations in context length and substantial memory overhead. These constraints often lead to significant information loss and reduced relevance in the model responses. With the exponential growth of video data across web platforms, understanding long-form video is crucial for advancing generalized intelligence. In this paper, we introduce SALOVA: Segment-Augmented LOng Video Assistant, a novel video-LLM framework designed to enhance the comprehension of lengthy video content through targeted retrieval process. We address two main challenges to achieve it: (i) We present the SceneWalk dataset, a high-quality collection of 87.8K long videos, each densely captioned at the segment level to enable models to capture scene continuity and maintain rich descriptive context. (ii) We develop robust architectural designs integrating dynamic routing mechanism and spatio-temporal projector to efficiently retrieve and process relevant video segments based on user queries. Our framework mitigates the limitations of current video-LMMs by allowing for precise identification and retrieval of relevant video segments in response to queries, thereby improving the contextual relevance of the generated responses. Through extensive experiments, SALOVA demonstrates enhanced capability in processing complex long-form videos, showing significant capability to maintain contextual integrity across extended sequences.