 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Lock-in: Diversifying Text-to-Image Generation via Representation Modulation
Jun 05, 2026Recent text-to-image models built on large-scale Transformer backbones and flow-based objectives deliver strong text-image alignment and high visual quality, yet often produce overly similar samples under a fixed prompt. Existing diversity-enhancement methods alleviate this issue, but typically require expensive sampling or auxiliary optimization, incurring non-trivial overhead. To investigate the root cause of this homogeneity, we examine intermediate Transformer features and observe that the zero-frequency spatial average (DC) component rapidly converges across seeds early in generation, causing early trajectory lock-in that limits downstream variation. Building on this observation, we propose DC Attenuation for diVersity Enhancement (DAVE), a training-free representation-level intervention that selectively attenuates this component in the early regime. DAVE preserves the sampling pipeline with negligible overhead, improving prompt-consistent diversity while maintaining competitive image quality.
DistMatch: Adaptive Binning via Distribution Matching for Robust Sequential Conformal Prediction
May 30, 2026Sequential conformal prediction (CP) provides valid uncertainty quantification under the assumption of residual exchangeability. However, this assumption is often violated in real-world time series due to temporal dependencies and distributional shifts. While recent methods attempt to approximate exchangeability through reweighting, identifying optimal weights remains an open challenge. To address this limitation, we propose DistMatch, a binning-based method that recursively partitions residuals within a binary tree using the Kolmogorov-Smirnov (KS) statistic. We theoretically show that this partitioning induces approximately exchangeable leaves, thereby avoiding the need for reweighting. By applying quantile regression with online updates within each leaf, DistMatch enables locally adaptive inference and improves robustness to distributional shifts. Extensive experiments demonstrate that DistMatch outperforms existing sequential CP methods.
Spectral Integrated Gradients for Coarse-to-Fine Feature Attribution
May 19, 2026Integrated Gradients (IG) is a widely adopted feature attribution method that satisfies desirable axiomatic properties. However, the choice of integration path significantly affects the quality of attributions, and the standard straight-line path introduces all input features simultaneously, often accumulating noisy gradients along the way. To address this limitation, we propose Spectral Integrated Gradients, which constructs integration paths based on singular value decomposition (SVD) of the baseline-to-input difference. By progressively activating singular components from largest to smallest, SIG introduces global structure before fine-grained details, naturally following a coarse-to-fine progression. Through extensive evaluation across diverse image classification datasets, we demonstrate that SIG produces cleaner attribution maps with reduced noise and achieves improved quantitative performance compared to existing path-based attribution methods. Our code is available at https://github.com/leekwoon/sig/.
Manifold-Aligned Guided Integrated Gradients for Reliable Feature Attribution
May 06, 2026Feature attribution is central to diagnosing and trusting deep neural networks, and Integrated Gradients (IG) is widely used due to its axiomatic properties. However, IG can yield unreliable explanations when the integration path between a baseline and the input passes through regions with noisy gradients. While Guided Integrated Gradients reduces this sensitivity by adaptively updating low-gradient-magnitude features, input-space guidance still produces intermediate inputs that deviate from the data manifold. To address this limitation, we propose \emph{Manifold-Aligned Guided Integrated Gradients} (MA-GIG), which constructs attribution paths in the latent space of a pre-trained variational autoencoder. By decoding intermediate latent states, MA-GIG biases the path toward the learned generative manifold and reduces exposure to implausible input-space regions. Through qualitative and quantitative evaluations, we demonstrate that MA-GIG produces faithful explanations by aggregating gradients on path features proximal to the input. Consequently, our method reduces off-manifold noise and outperforms prior path-based attribution methods across multiple datasets and classifiers. Our code is available at https://github.com/leekwoon/ma-gig/.
Refining Compositional Diffusion for Reliable Long-Horizon Planning
May 04, 2026Compositional diffusion planning generates long-horizon trajectories by stitching together overlapping short-horizon segments through score composition. However, when local plan distributions are multimodal, existing compositional methods suffer from mode-averaging, where averaging incompatible local modes leads to plans that are neither locally feasible nor globally coherent. We propose Refining Compositional Diffusion (RCD), a training-free guidance method that steers compositional sampling toward high-density, globally coherent plans. RCD leverages the self-reconstruction error of a pretrained diffusion model as a proxy for the log-density of composed plans, combined with an overlap consistency term that enforces consistency at segment boundaries. We show that the combined guidance concentrates sampling on high-density plans that mitigate mode-averaging. Experiments on challenging long-horizon tasks from OGBench, including locomotion, object manipulation, and pixel-based observations, demonstrate that RCD consistently outperforms existing methods.
K-MetBench: A Multi-Dimensional Benchmark for Fine-Grained Evaluation of Expert Reasoning, Locality, and Multimodality in Meteorology
Apr 27, 2026The development of practical (multimodal) large language model assistants for Korean weather forecasters is hindered by the absence of a multidimensional, expert-level evaluation framework grounded in authoritative sources. To address this, we introduce K-MetBench, a diagnostic benchmark grounded in national qualification exams. It exposes critical gaps across four dimensions: expert visual reasoning of charts, logical validity via expert-verified rationales, Korean-specific geo-cultural comprehension, and fine-grained domain analysis. Our evaluation of 55 models reveals a profound modality gap in interpreting specialized diagrams and a reasoning gap where models hallucinate logic despite correct predictions. Crucially, Korean models outperform significantly larger global models in local contexts, demonstrating that parameter scaling alone cannot resolve cultural dependencies. K-MetBench serves as a roadmap for developing reliable, culturally aware expert AI agents. The dataset is available at https://huggingface.co/datasets/soyeonbot/K-MetBench .
PnPXAI: A Universal XAI Framework Providing Automatic Explanations Across Diverse Modalities and Models
May 15, 2025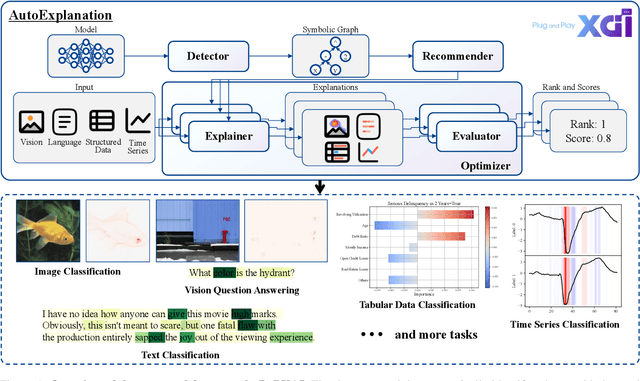
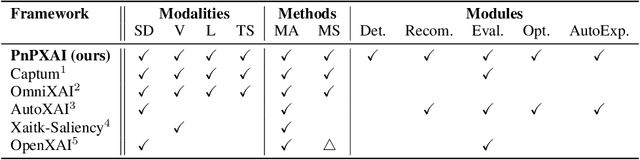

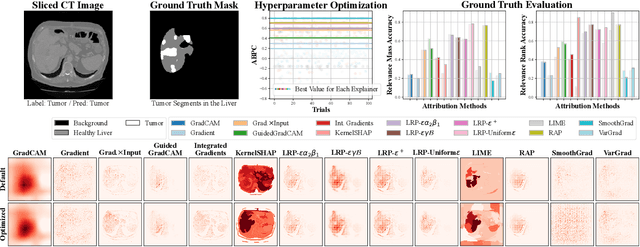
Recently, post hoc explanation methods have emerged to enhance model transparency by attributing model outputs to input features. However, these methods face challenges due to their specificity to certain neural network architectures and data modalities. Existing explainable artificial intelligence (XAI) frameworks have attempted to address these challenges but suffer from several limitations. These include limited flexibility to diverse model architectures and data modalities due to hard-coded implementations, a restricted number of supported XAI methods because of the requirements for layer-specific operations of attribution methods, and sub-optimal recommendations of explanations due to the lack of evaluation and optimization phases. Consequently, these limitations impede the adoption of XAI technology in real-world applications, making it difficult for practitioners to select the optimal explanation method for their domain. To address these limitations, we introduce \textbf{PnPXAI}, a universal XAI framework that supports diverse data modalities and neural network models in a Plug-and-Play (PnP) manner. PnPXAI automatically detects model architectures, recommends applicable explanation methods, and optimizes hyperparameters for optimal explanations. We validate the framework's effectiveness through user surveys and showcase its versatility across various domains, including medicine and finance.
Conditional Temporal Neural Processes with Covariance Loss
Apr 01, 2025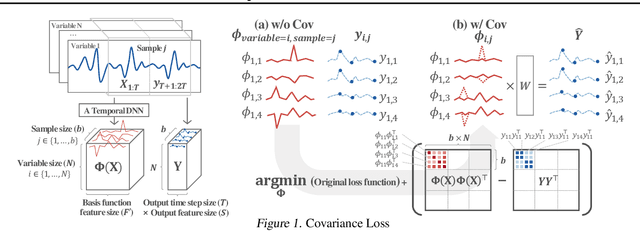



We introduce a novel loss function, Covariance Loss, which is conceptually equivalent to conditional neural processes and has a form of regularization so that is applicable to many kinds of neural networks. With the proposed loss, mappings from input variables to target variables are highly affected by dependencies of target variables as well as mean activation and mean dependencies of input and target variables. This nature enables the resulting neural networks to become more robust to noisy observations and recapture missing dependencies from prior information. In order to show the validity of the proposed loss, we conduct extensive sets of experiments on real-world datasets with state-of-the-art models and discuss the benefits and drawbacks of the proposed Covariance Loss.
* 11 pages, 18 figures
Example-Based Concept Analysis Framework for Deep Weather Forecast Models
Apr 01, 2025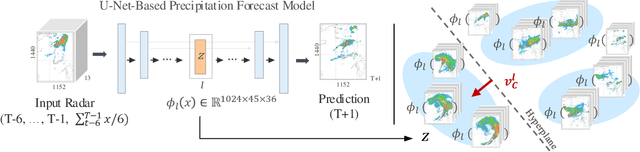
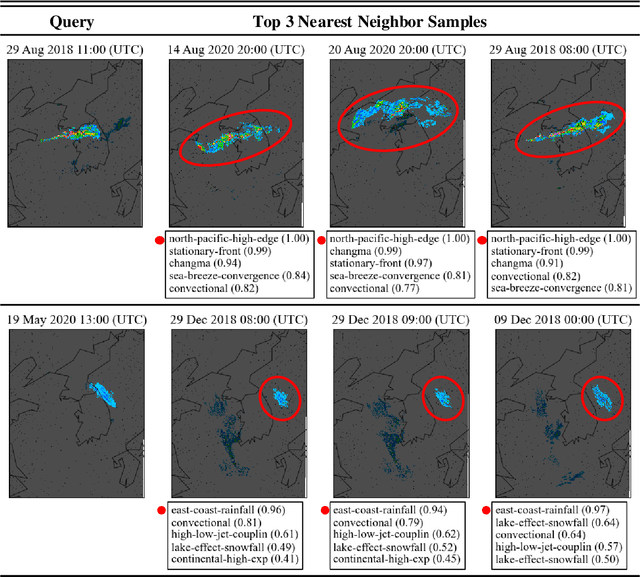
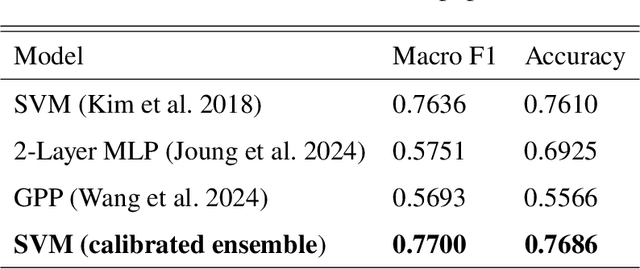
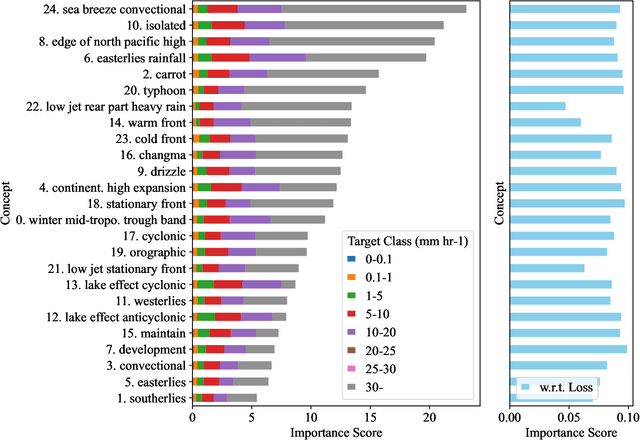
To improve the trustworthiness of an AI model, finding consistent, understandable representations of its inference process is essential. This understanding is particularly important in high-stakes operations such as weather forecasting, where the identification of underlying meteorological mechanisms is as critical as the accuracy of the predictions. Despite the growing literature that addresses this issue through explainable AI, the applicability of their solutions is often limited due to their AI-centric development. To fill this gap, we follow a user-centric process to develop an example-based concept analysis framework, which identifies cases that follow a similar inference process as the target instance in a target model and presents them in a user-comprehensible format. Our framework provides the users with visually and conceptually analogous examples, including the probability of concept assignment to resolve ambiguities in weather mechanisms. To bridge the gap between vector representations identified from models and human-understandable explanations, we compile a human-annotated concept dataset and implement a user interface to assist domain experts involved in the the framework development.
* 39 pages, 10 figures
Explainable AI-Based Interface System for Weather Forecasting Model
Apr 01, 2025Machine learning (ML) is becoming increasingly popular in meteorological decision-making. Although the literature on explainable artificial intelligence (XAI) is growing steadily, user-centered XAI studies have not extend to this domain yet. This study defines three requirements for explanations of black-box models in meteorology through user studies: statistical model performance for different rainfall scenarios to identify model bias, model reasoning, and the confidence of model outputs. Appropriate XAI methods are mapped to each requirement, and the generated explanations are tested quantitatively and qualitatively. An XAI interface system is designed based on user feedback. The results indicate that the explanations increase decision utility and user trust. Users prefer intuitive explanations over those based on XAI algorithms even for potentially easy-to-recognize examples. These findings can provide evidence for future research on user-centered XAI algorithms, as well as a basis to improve the usability of AI systems in practice.
* 19 pages, 16 figures