 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-MetBench: A Multi-Dimensional Benchmark for Fine-Grained Evaluation of Expert Reasoning, Locality, and Multimodality in Meteorology
Apr 27, 2026The development of practical (multimodal) large language model assistants for Korean weather forecasters is hindered by the absence of a multidimensional, expert-level evaluation framework grounded in authoritative sources. To address this, we introduce K-MetBench, a diagnostic benchmark grounded in national qualification exams. It exposes critical gaps across four dimensions: expert visual reasoning of charts, logical validity via expert-verified rationales, Korean-specific geo-cultural comprehension, and fine-grained domain analysis. Our evaluation of 55 models reveals a profound modality gap in interpreting specialized diagrams and a reasoning gap where models hallucinate logic despite correct predictions. Crucially, Korean models outperform significantly larger global models in local contexts, demonstrating that parameter scaling alone cannot resolve cultural dependencies. K-MetBench serves as a roadmap for developing reliable, culturally aware expert AI agents. The dataset is available at https://huggingface.co/datasets/soyeonbot/K-MetBench .
Neural ODE Transformers: Analyzing Internal Dynamics and Adaptive Fine-tuning
Mar 03, 2025Recent advancements in large language models (LLMs) based on transformer architectures have sparked significant interest in understanding their inner workings. In this paper, we introduce a novel approach to modeling transformer architectures using highly flexible non-autonomous neural ordinary differential equations (ODEs). Our proposed model parameterizes all weights of attention and feed-forward blocks through neural networks, expressing these weights as functions of a continuous layer index. Through spectral analysis of the model's dynamics, we uncover an increase in eigenvalue magnitude that challenges the weight-sharing assumption prevalent in existing theoretical studies. We also leverage the Lyapunov exponent to examine token-level sensitivity, enhancing model interpretability. Our neural ODE transformer demonstrates performance comparable to or better than vanilla transformers across various configurations and datasets, while offering flexible fine-tuning capabilities that can adapt to different architectural constraints.
Impact of Co-occurrence on Factual Knowledge of Large Language Models
Oct 12, 2023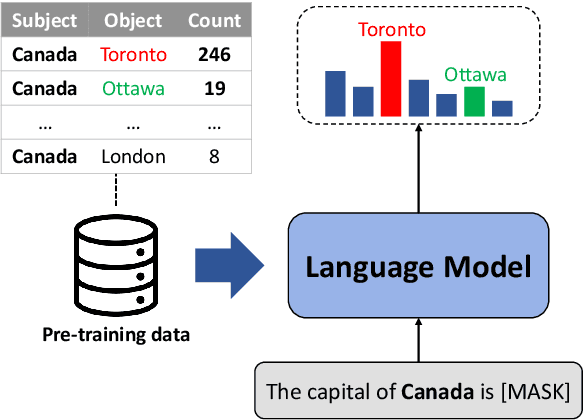



Large language models (LLMs) often make factually incorrect responses despite their success in various applications. In this paper, we hypothesize that relying heavily on simple co-occurrence statistics of the pre-training corpora is one of the main factors that cause factual errors. Our results reveal that LLMs are vulnerable to the co-occurrence bias, defined as preferring frequently co-occurred words over the correct answer. Consequently, LLMs struggle to recall facts whose subject and object rarely co-occur in the pre-training dataset although they are seen during finetuning. We show that co-occurrence bias remains despite scaling up model sizes or finetuning. Therefore, we suggest finetuning on a debiased dataset to mitigate the bias by filtering out biased samples whose subject-object co-occurrence count is high. Although debiased finetuning allows LLMs to memorize rare facts in the training set, it is not effective in recalling rare facts unseen during finetuning. Further research in mitigation will help build reliable language models by preventing potential errors. The code is available at \url{https://github.com/CheongWoong/impact_of_cooccurrence}.
Why Do Neural Language Models Still Need Commonsense Knowledge to Handle Semantic Variations in Question Answering?
Sep 01, 2022


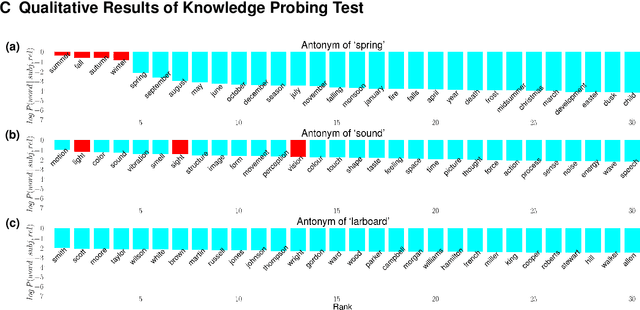
Many contextualized word representations are now learned by intricate neural network models, such as masked neural language models (MNLMs) which are made up of huge neural network structures and trained to restore the masked text. Such representations demonstrate superhuman performance in some reading comprehension (RC) tasks which extract a proper answer in the context given a question. However, identifying the detailed knowledge trained in MNLMs is challenging owing to numerous and intermingled model parameters. This paper provides new insights and empirical analyses on commonsense knowledge included in pretrained MNLMs. First, we use a diagnostic test that evaluates whether commonsense knowledge is properly trained in MNLMs. We observe that a large proportion of commonsense knowledge is not appropriately trained in MNLMs and MNLMs do not often understand the semantic meaning of relations accurately. In addition, we find that the MNLM-based RC models are still vulnerable to semantic variations that require commonsense knowledge. Finally, we discover the fundamental reason why some knowledge is not trained. We further suggest that utilizing an external commonsense knowledge repository can be an effective solution. We exemplify the possibility to overcome the limitations of the MNLM-based RC models by enriching text with the required knowledge from an external commonsense knowledge repository in controlled experiments.
Why Do Masked Neural Language Models Still Need Common Sense Knowledge?
Nov 08, 2019

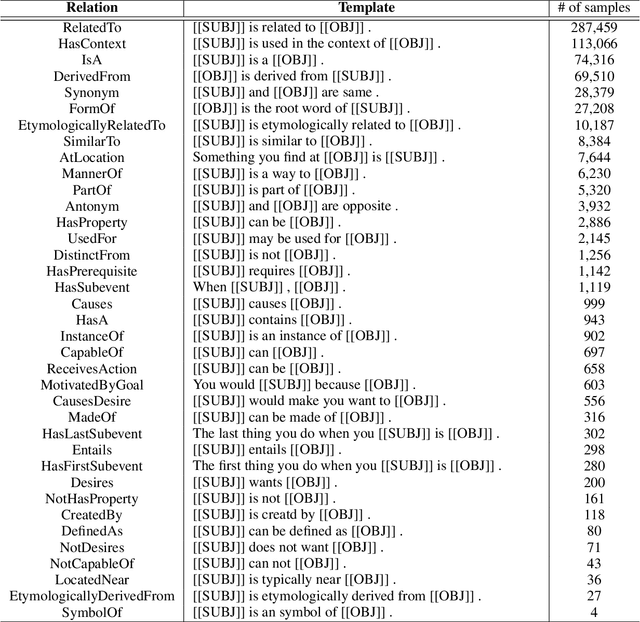

Currently, contextualized word representations are learned by intricate neural network models, such as masked neural language models (MNLMs). The new representations significantly enhanced the performance in automated question answering by reading paragraphs. However, identifying the detailed knowledge trained in the MNLMs is difficult owing to numerous and intermingled parameters. This paper provides empirical but insightful analyses on the pretrained MNLMs with respect to common sense knowledge. First, we propose a test that measures what types of common sense knowledge do pretrained MNLMs understand. From the test, we observed that MNLMs partially understand various types of common sense knowledge but do not accurately understand the semantic meaning of relations. In addition, based on the difficulty of the question-answering task problems, we observed that pretrained MLM-based models are still vulnerable to problems that require common sense knowledge. We also experimentally demonstrated that we can elevate existing MNLM-based models by combining knowledge from an external common sense repository.