 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildCross: A Cross-Modal Large Scale Benchmark for Place Recognition and Metric Depth Estimation in Natural Environments
Mar 02, 2026Recent years have seen a significant increase in demand for robotic solutions in unstructured natural environments, alongside growing interest in bridging 2D and 3D scene understanding. However, existing robotics datasets are predominantly captured in structured urban environments, making them inadequate for addressing the challenges posed by complex, unstructured natural settings. To address this gap, we propose WildCross, a cross-modal benchmark for place recognition and metric depth estimation in large-scale natural environments. WildCross comprises over 476K sequential RGB frames with semi-dense depth and surface normal annotations, each aligned with accurate 6DoF poses and synchronized dense lidar submaps. We conduct comprehensive experiments on visual, lidar, and cross-modal place recognition, as well as metric depth estimation, demonstrating the value of WildCross as a challenging benchmark for multi-modal robotic perception tasks. We provide access to the code repository and dataset at https://csiro-robotics.github.io/WildCross.
Beyond a Single Extractor: Re-thinking HTML-to-Text Extraction for LLM Pretraining
Feb 23, 2026One of the first pre-processing steps for constructing web-scale LLM pretraining datasets involves extracting text from HTML. Despite the immense diversity of web content, existing open-source datasets predominantly apply a single fixed extractor to all webpages. In this work, we investigate whether this practice leads to suboptimal coverage and utilization of Internet data. We first show that while different extractors may lead to similar model performance on standard language understanding tasks, the pages surviving a fixed filtering pipeline can differ substantially. This suggests a simple intervention: by taking a Union over different extractors, we can increase the token yield of DCLM-Baseline by up to 71% while maintaining benchmark performance. We further show that for structured content such as tables and code blocks, extractor choice can significantly impact downstream task performance, with differences of up to 10 percentage points (p.p.) on WikiTQ and 3 p.p. on HumanEval.
Democracy of AI Numerical Weather Models: An Example of Global Forecasting with FourCastNetv2 Made by a University Research Lab Using GPU
Apr 23, 2025This paper demonstrates the feasibility of democratizing AI-driven global weather forecasting models among university research groups by leveraging Graphics Processing Units (GPUs) and freely available AI models, such as NVIDIA's FourCastNetv2. FourCastNetv2 is an NVIDIA's advanced neural network for weather prediction and is trained on a 73-channel subset of the European Centre for Medium-Range Weather Forecasts (ECMWF) Reanalysis v5 (ERA5) dataset at single levels and different pressure levels. Although the training specifications for FourCastNetv2 are not released to the public, the training documentation of the model's first generation, FourCastNet, is available to all users. The training had 64 A100 GPUs and took 16 hours to complete. Although NVIDIA's models offer significant reductions in both time and cost compared to traditional Numerical Weather Prediction (NWP), reproducing published forecasting results presents ongoing challenges for resource-constrained university research groups with limited GPU availability. We demonstrate both (i) leveraging FourCastNetv2 to create predictions through the designated application programming interface (API) and (ii) utilizing NVIDIA hardware to train the original FourCastNet model. Further, this paper demonstrates the capabilities and limitations of NVIDIA A100's for resource-limited research groups in universities. We also explore data management, training efficiency, and model validation, highlighting the advantages and challenges of using limited high-performance computing resources. Consequently, this paper and its corresponding GitHub materials may serve as an initial guide for other university research groups and courses related to machine learning, climate science, and data science to develop research and education programs on AI weather forecasting, and hence help democratize the AI NWP in the digital economy.
Neural ODE Transformers: Analyzing Internal Dynamics and Adaptive Fine-tuning
Mar 03, 2025Recent advancements in large language models (LLMs) based on transformer architectures have sparked significant interest in understanding their inner workings. In this paper, we introduce a novel approach to modeling transformer architectures using highly flexible non-autonomous neural ordinary differential equations (ODEs). Our proposed model parameterizes all weights of attention and feed-forward blocks through neural networks, expressing these weights as functions of a continuous layer index. Through spectral analysis of the model's dynamics, we uncover an increase in eigenvalue magnitude that challenges the weight-sharing assumption prevalent in existing theoretical studies. We also leverage the Lyapunov exponent to examine token-level sensitivity, enhancing model interpretability. Our neural ODE transformer demonstrates performance comparable to or better than vanilla transformers across various configurations and datasets, while offering flexible fine-tuning capabilities that can adapt to different architectural constraints.
Understanding Warmup-Stable-Decay Learning Rates: A River Valley Loss Landscape Perspective
Oct 07, 2024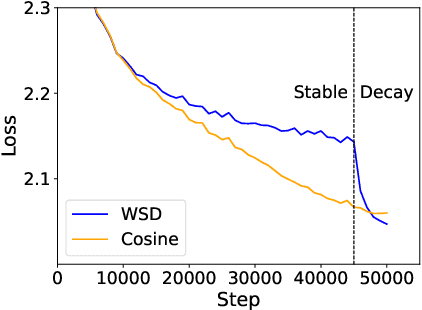

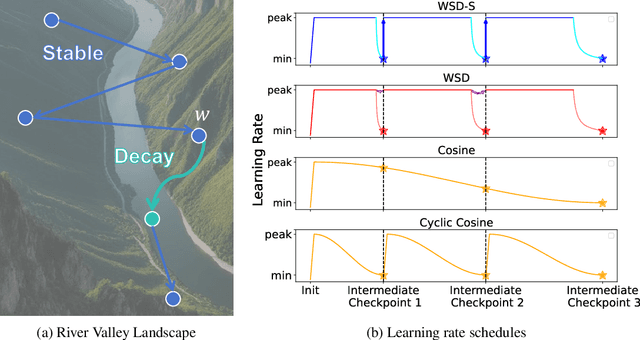
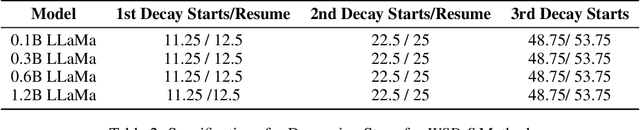
Training language models currently requires pre-determining a fixed compute budget because the typical cosine learning rate schedule depends on the total number of steps. In contrast, the Warmup-Stable-Decay (WSD) schedule uses a constant learning rate to produce a main branch of iterates that can in principle continue indefinitely without a pre-specified compute budget. Then, given any compute budget, one can branch out from the main branch at a proper at any time with a rapidly decaying learning rate to produce a strong model. Empirically, WSD generates a non-traditional loss curve: the loss remains elevated during the stable phase but sharply declines during the decay phase. Towards explaining this phenomenon, we conjecture that pretraining loss exhibits a river valley landscape, which resembles a deep valley with a river at its bottom. Under this assumption, we show that during the stable phase, the iterate undergoes large oscillations due to the high learning rate, yet it progresses swiftly along the river. During the decay phase, the rapidly dropping learning rate minimizes the iterate's oscillations, moving it closer to the river and revealing true optimization progress. Therefore, the sustained high learning rate phase and fast decaying phase are responsible for progress in the river and the mountain directions respectively, and are both critical. Our analysis predicts phenomenons consistent with empirical observations and shows that this landscape can emerge from pretraining on a simple bi-gram dataset. Inspired by the theory, we introduce WSD-S, a variant of WSD that reuses previous checkpoints' decay phases and keeps only one main branch, where we resume from a decayed checkpoint. WSD-S empirically outperforms WSD and Cyclic-Cosine in obtaining multiple language model checkpoints across various compute budgets in a single run for parameters scaling from 0.1B to 1.2B.
Object Registration in Neural Fields
Apr 29, 2024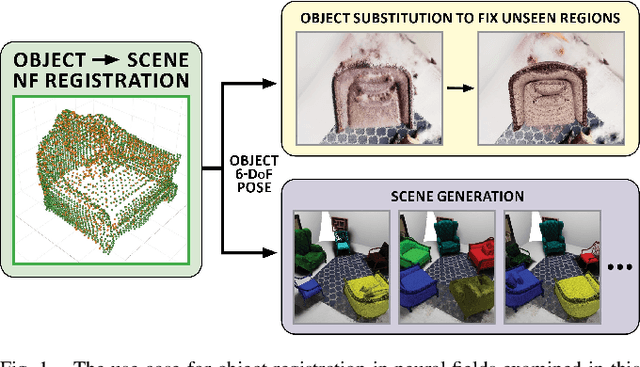

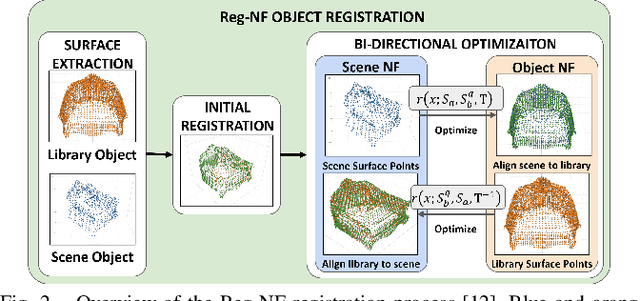

Neural fields provide a continuous scene representation of 3D geometry and appearance in a way which has great promise for robotics applications. One functionality that unlocks unique use-cases for neural fields in robotics is object 6-DoF registration. In this paper, we provide an expanded analysis of the recent Reg-NF neural field registration method and its use-cases within a robotics context. We showcase the scenario of determining the 6-DoF pose of known objects within a scene using scene and object neural field models. We show how this may be used to better represent objects within imperfectly modelled scenes and generate new scenes by substituting object neural field models into the scene.
BioMedLM: A 2.7B Parameter Language Model Trained On Biomedical Text
Mar 27, 2024Models such as GPT-4 and Med-PaLM 2 have demonstrated impressive performance on a wide variety of biomedical NLP tasks. However, these models have hundreds of billions of parameters, are computationally expensive to run, require users to send their input data over the internet, and are trained on unknown data sources. Can smaller, more targeted models compete? To address this question, we build and release BioMedLM, a 2.7 billion parameter GPT-style autoregressive model trained exclusively on PubMed abstracts and full articles. When fine-tuned, BioMedLM can produce strong multiple-choice biomedical question-answering results competitive with much larger models, such as achieving a score of 57.3% on MedMCQA (dev) and 69.0% on the MMLU Medical Genetics exam. BioMedLM can also be fine-tuned to produce useful answers to patient questions on medical topics. This demonstrates that smaller models can potentially serve as transparent, privacy-preserving, economical and environmentally friendly foundations for particular NLP applications, such as in biomedicine. The model is available on the Hugging Face Hub: https://huggingface.co/stanford-crfm/BioMedLM.
Reg-NF: Efficient Registration of Implicit Surfaces within Neural Fields
Feb 15, 2024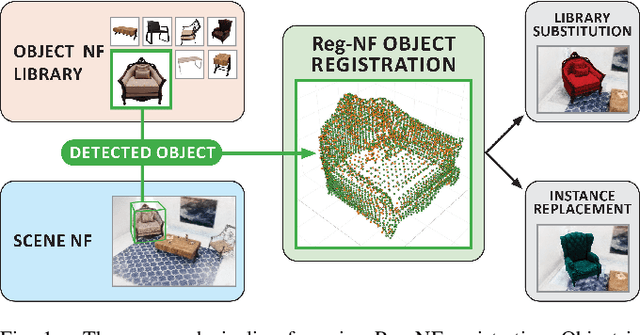
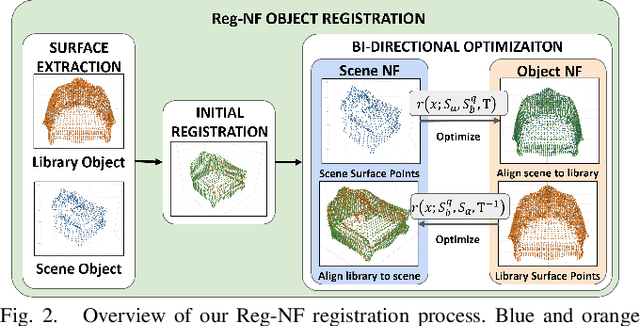

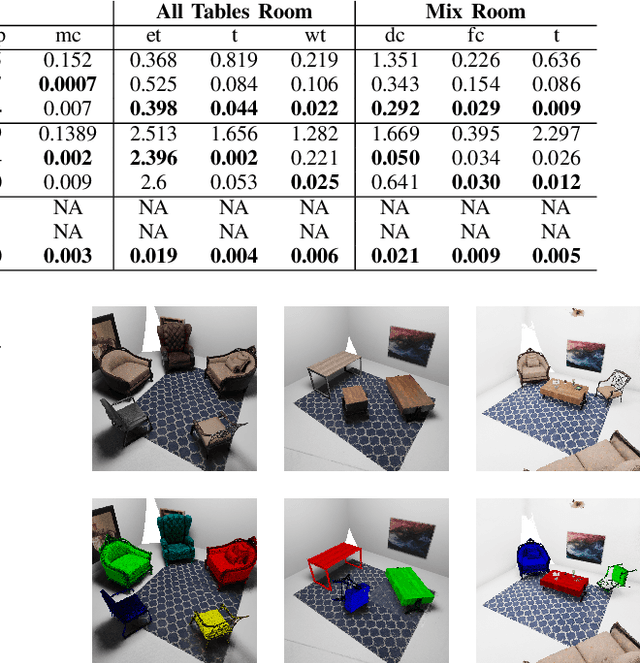
Neural fields, coordinate-based neural networks, have recently gained popularity for implicitly representing a scene. In contrast to classical methods that are based on explicit representations such as point clouds, neural fields provide a continuous scene representation able to represent 3D geometry and appearance in a way which is compact and ideal for robotics applications. However, limited prior methods have investigated registering multiple neural fields by directly utilising these continuous implicit representations. In this paper, we present Reg-NF, a neural fields-based registration that optimises for the relative 6-DoF transformation between two arbitrary neural fields, even if those two fields have different scale factors. Key components of Reg-NF include a bidirectional registration loss, multi-view surface sampling, and utilisation of volumetric signed distance functions (SDFs). We showcase our approach on a new neural field dataset for evaluating registration problems. We provide an exhaustive set of experiments and ablation studies to identify the performance of our approach, while also discussing limitations to provide future direction to the research community on open challenges in utilizing neural fields in unconstrained environments.
Anticipatory Music Transformer
Jun 14, 2023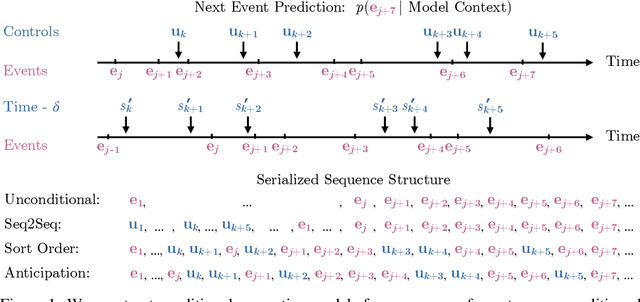
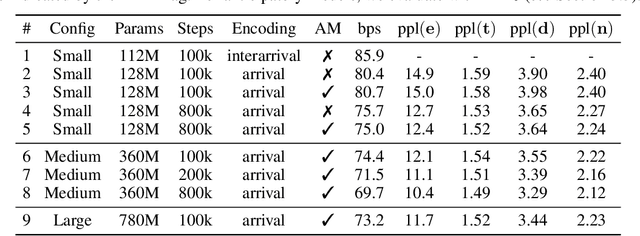
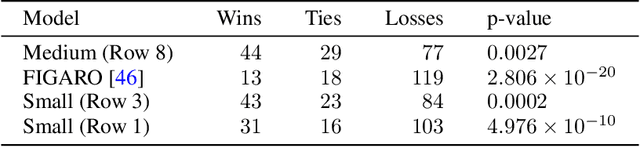
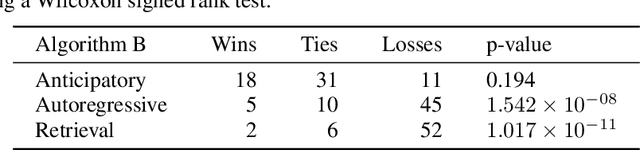
We introduce anticipation: a method for constructing a controllable generative model of a temporal point process (the event process) conditioned asynchronously on realizations of a second, correlated process (the control process). We achieve this by interleaving sequences of events and controls, such that controls appear following stopping times in the event sequence. This work is motivated by problems arising in the control of symbolic music generation. We focus on infilling control tasks, whereby the controls are a subset of the events themselves, and conditional generation completes a sequence of events given the fixed control events. We train anticipatory infilling models using the large and diverse Lakh MIDI music dataset. These models match the performance of autoregressive models for prompted music generation, with the additional capability to perform infilling control tasks, including accompaniment. Human evaluators report that an anticipatory model produces accompaniments with similar musicality to even music composed by humans over a 20-second clip.
Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training
May 23, 2023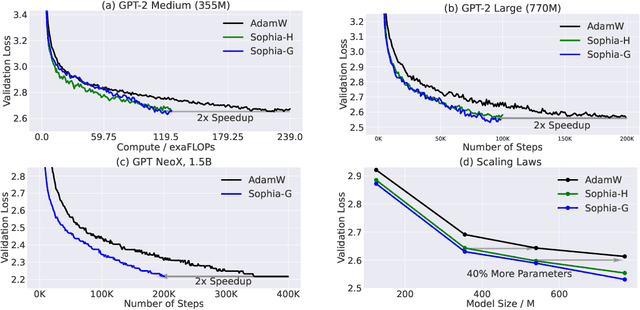
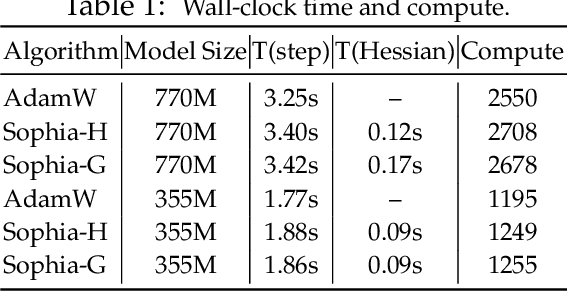

Given the massive cost of language model pre-training, a non-trivial improvement of the optimization algorithm would lead to a material reduction on the time and cost of training. Adam and its variants have been state-of-the-art for years, and more sophisticated second-order (Hessian-based) optimizers often incur too much per-step overhead. In this paper, we propose Sophia, Second-order Clipped Stochastic Optimization, a simple scalable second-order optimizer that uses a light-weight estimate of the diagonal Hessian as the pre-conditioner. The update is the moving average of the gradients divided by the moving average of the estimated Hessian, followed by element-wise clipping. The clipping controls the worst-case update size and tames the negative impact of non-convexity and rapid change of Hessian along the trajectory. Sophia only estimates the diagonal Hessian every handful of iterations, which has negligible average per-step time and memory overhead. On language modeling with GPT-2 models of sizes ranging from 125M to 770M, Sophia achieves a 2x speed-up compared with Adam in the number of steps, total compute, and wall-clock time. Theoretically, we show that Sophia adapts to the curvature in different components of the parameters, which can be highly heterogeneous for language modeling tasks. Our run-time bound does not depend on the condition number of the loss.