 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Driven Research for Databases
Apr 08, 2026As the complexity of modern workloads and hardware increasingly outpaces human research and engineering capacity, existing methods for database performance optimization struggle to keep pace. To address this gap, a new class of techniques, termed AI-Driven Research for Systems (ADRS), uses large language models to automate solution discovery. This approach shifts optimization from manual system design to automated code generation. The key obstacle, however, in applying ADRS is the evaluation pipeline. Since these frameworks rapidly generate hundreds of candidates without human supervision, they depend on fast and accurate feedback from evaluators to converge on effective solutions. Building such evaluators is especially difficult for complex database systems. To enable the practical application of ADRS in this domain, we propose automating the design of evaluators by co-evolving them with the solutions. We demonstrate the effectiveness of this approach through three case studies optimizing buffer management, query rewriting, and index selection. Our automated evaluators enable the discovery of novel algorithms that outperform state-of-the-art baselines (e.g., a deterministic query rewrite policy that achieves up to 6.8x lower latency), demonstrating that addressing the evaluation bottleneck unlocks the potential of ADRS to generate highly optimized, deployable code for next-generation data systems.
The Price Reversal Phenomenon: When Cheaper Reasoning Models End Up Costing More
Mar 25, 2026Developers and consumers increasingly choose reasoning language models (RLMs) based on their listed API prices. However, how accurately do these prices reflect actual inference costs? We conduct the first systematic study of this question, evaluating 8 frontier RLMs across 9 diverse tasks covering competition math, science QA, code generation, and multi-domain reasoning. We uncover the pricing reversal phenomenon: in 21.8% of model-pair comparisons, the model with a lower listed price actually incurs a higher total cost, with reversal magnitude reaching up to 28x. For example, Gemini 3 Flash's listed price is 78% cheaper than GPT-5.2's, yet its actual cost across all tasks is 22% higher. We trace the root cause to vast heterogeneity in thinking token consumption: on the same query, one model may use 900% more thinking tokens than another. In fact, removing thinking token costs reduces ranking reversals by 70% and raises the rank correlation (Kendall's $τ$ ) between price and cost rankings from 0.563 to 0.873. We further show that per-query cost prediction is fundamentally difficult: repeated runs of the same query yield thinking token variation up to 9.7x, establishing an irreducible noise floor for any predictor. Our findings demonstrate that listed API pricing is an unreliable proxy for actual cost, calling for cost-aware model selection and transparent per-request cost monitoring.
OfficeQA Pro: An Enterprise Benchmark for End-to-End Grounded Reasoning
Mar 09, 2026We introduce OfficeQA Pro, a benchmark for evaluating AI agents on grounded, multi-document reasoning over a large and heterogeneous document corpus. The corpus consists of U.S. Treasury Bulletins spanning nearly 100 years, comprising 89,000 pages and over 26 million numerical values. OfficeQA Pro consists of 133 questions that require precise document parsing, retrieval, and analytical reasoning across both unstructured text and tabular data. Frontier LLMs including Claude Opus 4.6, GPT-5.4, and Gemini 3.1 Pro Preview achieve less than 5% accuracy on OfficeQA Pro when relying on parametric knowledge, and less than 12% with additional access to the web. When provided directly with the document corpus, frontier agents still struggle on over half of questions, scoring 34.1% on average. We find that providing agents with a structured document representation produced by Databricks' ai_parse_document yields a 16.1% average relative performance gain across agents. We conduct additional ablations to study the effects of model selection, table representation, retrieval strategy, and test-time scaling on performance. Despite these improvements, significant headroom remains before agents can be considered reliable at enterprise-grade grounded reasoning.
AdaEvolve: Adaptive LLM Driven Zeroth-Order Optimization
Feb 23, 2026The paradigm of automated program generation is shifting from one-shot generation to inference-time search, where Large Language Models (LLMs) function as semantic mutation operators within evolutionary loops. While effective, these systems are currently governed by static schedules that fail to account for the non-stationary dynamics of the search process. This rigidity results in substantial computational waste, as resources are indiscriminately allocated to stagnating populations while promising frontiers remain under-exploited. We introduce AdaEvolve, a framework that reformulates LLM-driven evolution as a hierarchical adaptive optimization problem. AdaEvolve uses an "accumulated improvement signal" to unify decisions across three levels: Local Adaptation, which dynamically modulates the exploration intensity within a population of solution candidates; Global Adaptation, which routes the global resource budget via bandit-based scheduling across different solution candidate populations; and Meta-Guidance which generates novel solution tactics based on the previously generated solutions and their corresponding improvements when the progress stalls. We demonstrate that AdaEvolve consistently outperforms the open-sourced baselines across 185 different open-ended optimization problems including combinatorial, systems optimization and algorithm design problems.
Let the Barbarians In: How AI Can Accelerate Systems Performance Research
Dec 22, 2025Artificial Intelligence (AI) is beginning to transform the research process by automating the discovery of new solutions. This shift depends on the availability of reliable verifiers, which AI-driven approaches require to validate candidate solutions. Research focused on improving systems performance is especially well-suited to this paradigm because system performance problems naturally admit such verifiers: candidates can be implemented in real systems or simulators and evaluated against predefined workloads. We term this iterative cycle of generation, evaluation, and refinement AI-Driven Research for Systems (ADRS). Using several open-source ADRS instances (i.e., OpenEvolve, GEPA, and ShinkaEvolve), we demonstrate across ten case studies (e.g., multi-region cloud scheduling, mixture-of-experts load balancing, LLM-based SQL, transaction scheduling) that ADRS-generated solutions can match or even outperform human state-of-the-art designs. Based on these findings, we outline best practices (e.g., level of prompt specification, amount of feedback, robust evaluation) for effectively using ADRS, and we discuss future research directions and their implications. Although we do not yet have a universal recipe for applying ADRS across all of systems research, we hope our preliminary findings, together with the challenges we identify, offer meaningful guidance for future work as researcher effort shifts increasingly toward problem formulation and strategic oversight. Note: This paper is an extension of our prior work [14]. It adds extensive evaluation across multiple ADRS frameworks and provides deeper analysis and insights into best practices.
DeepScholar-Bench: A Live Benchmark and Automated Evaluation for Generative Research Synthesis
Aug 27, 2025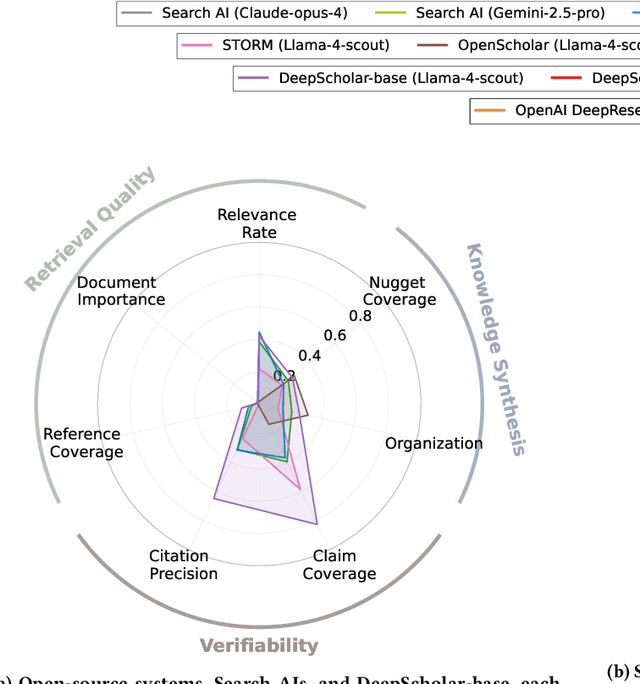
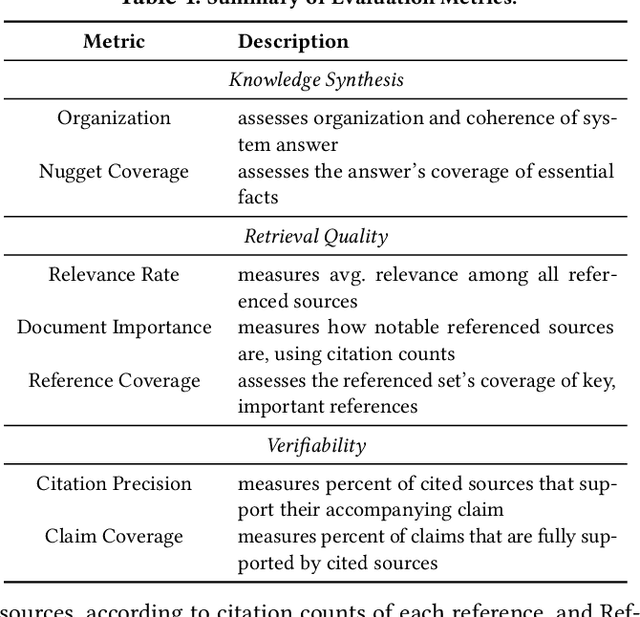
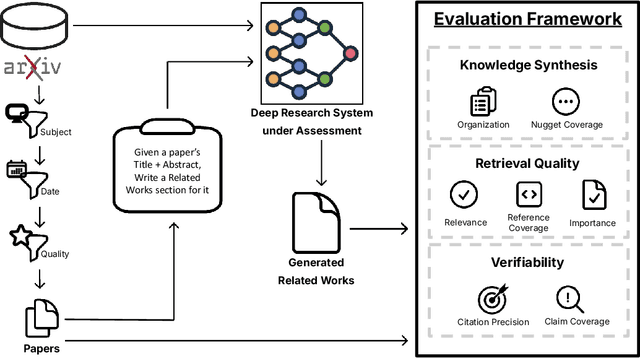
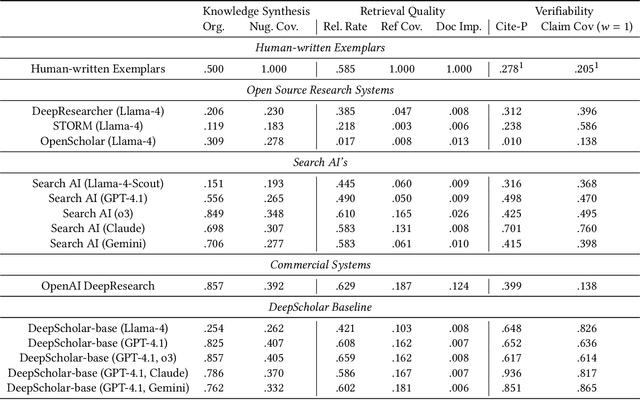
The ability to research and synthesize knowledge is central to human expertise and progress. An emerging class of systems promises these exciting capabilities through generative research synthesis, performing retrieval over the live web and synthesizing discovered sources into long-form, cited summaries. However, evaluating such systems remains an open challenge: existing question-answering benchmarks focus on short-form factual responses, while expert-curated datasets risk staleness and data contamination. Both fail to capture the complexity and evolving nature of real research synthesis tasks. In this work, we introduce DeepScholar-bench, a live benchmark and holistic, automated evaluation framework designed to evaluate generative research synthesis. DeepScholar-bench draws queries from recent, high-quality ArXiv papers and focuses on a real research synthesis task: generating the related work sections of a paper by retrieving, synthesizing, and citing prior research. Our evaluation framework holistically assesses performance across three key dimensions, knowledge synthesis, retrieval quality, and verifiability. We also develop DeepScholar-base, a reference pipeline implemented efficiently using the LOTUS API. Using the DeepScholar-bench framework, we perform a systematic evaluation of prior open-source systems, search AI's, OpenAI's DeepResearch, and DeepScholar-base. We find that DeepScholar-base establishes a strong baseline, attaining competitive or higher performance than each other method. We also find that DeepScholar-bench remains far from saturated, with no system exceeding a score of $19\%$ across all metrics. These results underscore the difficulty of DeepScholar-bench, as well as its importance for progress towards AI systems capable of generative research synthesis. We make our code available at https://github.com/guestrin-lab/deepscholar-bench.
Multi-module GRPO: Composing Policy Gradients and Prompt Optimization for Language Model Programs
Aug 06, 2025Group Relative Policy Optimization (GRPO) has proven to be an effective tool for post-training language models (LMs). However, AI systems are increasingly expressed as modular programs that mix together multiple LM calls with distinct prompt templates and other tools, and it is not clear how best to leverage GRPO to improve these systems. We begin to address this challenge by defining mmGRPO, a simple multi-module generalization of GRPO that groups LM calls by module across rollouts and handles variable-length and interrupted trajectories. We find that mmGRPO, composed with automatic prompt optimization, improves accuracy by 11% on average across classification, many-hop search, and privacy-preserving delegation tasks against the post-trained LM, and by 5% against prompt optimization on its own. We open-source mmGRPO in DSPy as the dspy.GRPO optimizer.
Establishing Best Practices for Building Rigorous Agentic Benchmarks
Jul 03, 2025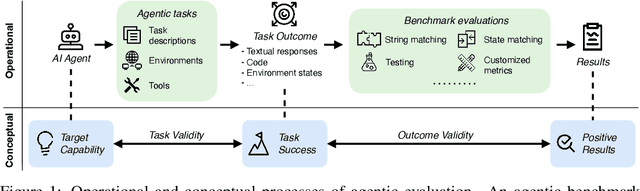
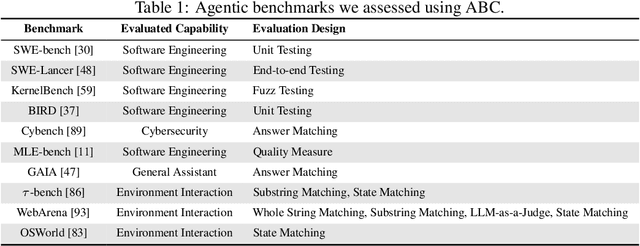
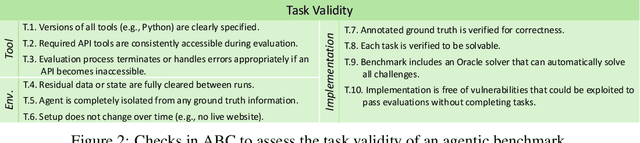
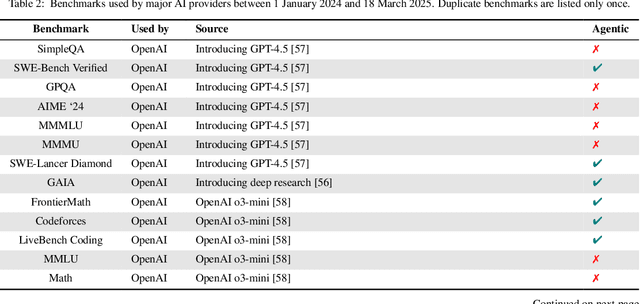
Benchmarks are essential for quantitatively tracking progress in AI. As AI agents become increasingly capable, researchers and practitioners have introduced agentic benchmarks to evaluate agents on complex, real-world tasks. These benchmarks typically measure agent capabilities by evaluating task outcomes via specific reward designs. However, we show that many agentic benchmarks have issues task setup or reward design. For example, SWE-bench Verified uses insufficient test cases, while TAU-bench counts empty responses as successful. Such issues can lead to under- or overestimation agents' performance by up to 100% in relative terms. To make agentic evaluation rigorous, we introduce the Agentic Benchmark Checklist (ABC), a set of guidelines that we synthesized from our benchmark-building experience, a survey of best practices, and previously reported issues. When applied to CVE-Bench, a benchmark with a particularly complex evaluation design, ABC reduces the performance overestimation by 33%.
LEANN: A Low-Storage Vector Index
Jun 09, 2025Embedding-based search is widely used in applications such as recommendation and retrieval-augmented generation (RAG). Recently, there is a growing demand to support these capabilities over personal data stored locally on devices. However, maintaining the necessary data structure associated with the embedding-based search is often infeasible due to its high storage overhead. For example, indexing 100 GB of raw data requires 150 to 700 GB of storage, making local deployment impractical. Reducing this overhead while maintaining search quality and latency becomes a critical challenge. In this paper, we present LEANN, a storage-efficient approximate nearest neighbor (ANN) search index optimized for resource-constrained personal devices. LEANN combines a compact graph-based structure with an efficient on-the-fly recomputation strategy to enable fast and accurate retrieval with minimal storage overhead. Our evaluation shows that LEANN reduces index size to under 5% of the original raw data, achieving up to 50 times smaller storage than standard indexes, while maintaining 90% top-3 recall in under 2 seconds on real-world question answering benchmarks.
EXP-Bench: Can AI Conduct AI Research Experiments?
May 30, 2025



Automating AI research holds immense potential for accelerating scientific progress, yet current AI agents struggle with the complexities of rigorous, end-to-end experimentation. We introduce EXP-Bench, a novel benchmark designed to systematically evaluate AI agents on complete research experiments sourced from influential AI publications. Given a research question and incomplete starter code, EXP-Bench challenges AI agents to formulate hypotheses, design and implement experimental procedures, execute them, and analyze results. To enable the creation of such intricate and authentic tasks with high-fidelity, we design a semi-autonomous pipeline to extract and structure crucial experimental details from these research papers and their associated open-source code. With the pipeline, EXP-Bench curated 461 AI research tasks from 51 top-tier AI research papers. Evaluations of leading LLM-based agents, such as OpenHands and IterativeAgent on EXP-Bench demonstrate partial capabilities: while scores on individual experimental aspects such as design or implementation correctness occasionally reach 20-35%, the success rate for complete, executable experiments was a mere 0.5%. By identifying these bottlenecks and providing realistic step-by-step experiment procedures, EXP-Bench serves as a vital tool for future AI agents to improve their ability to conduct AI research experiments. EXP-Bench is open-sourced at https://github.com/Just-Curieous/Curie/tree/main/benchmark/exp_bench.