 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColBERT-serve: Efficient Multi-Stage Memory-Mapped Scoring
Apr 21, 2025We study serving retrieval models, specifically late interaction models like ColBERT, to many concurrent users at once and under a small budget, in which the index may not fit in memory. We present ColBERT-serve, a novel serving system that applies a memory-mapping strategy to the ColBERT index, reducing RAM usage by 90% and permitting its deployment on cheap servers, and incorporates a multi-stage architecture with hybrid scoring, reducing ColBERT's query latency and supporting many concurrent queries in parallel.
DeepThink: Aligning Language Models with Domain-Specific User Intents
Feb 08, 2025Supervised fine-tuning with synthesized instructions has been a common practice for adapting LLMs to domain-specific QA tasks. However, the synthesized instructions deviate from real user questions and expected answers. This study proposes a novel framework called DeepThink to generate high-quality instructions. DeepThink first generates a few seed questions to mimic actual user questions, simulates conversations to uncover the hidden user needs, and refines the answer by conversational contexts and the retrieved documents for more comprehensive answers. Experiments demonstrate that DeepThink achieves an average performance improvement of 7.92% compared to a GPT-4-turbo+RAG-based assistant on the real user test set in the advertising domain across dimensions such as relevance, completeness, clarity, accuracy, and actionability.
Investigating Effect of Dialogue History in Multilingual Task Oriented Dialogue Systems
Dec 23, 2021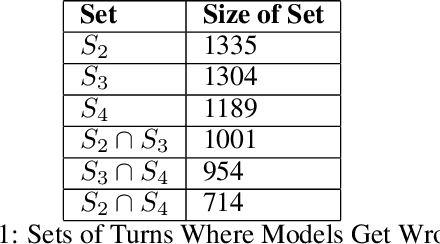
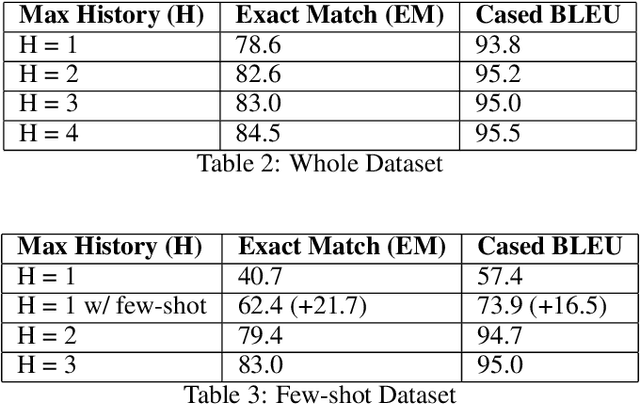
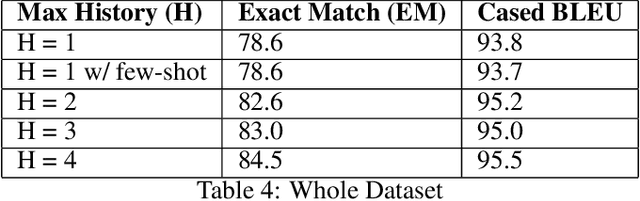
While the English virtual assistants have achieved exciting performance with an enormous amount of training resources, the needs of non-English-speakers have not been satisfied well. Up to Dec 2021, Alexa, one of the most popular smart speakers around the world, is able to support 9 different languages [1], while there are thousands of languages in the world, 91 of which are spoken by more than 10 million people according to statistics published in 2019 [2]. However, training a virtual assistant in other languages than English is often more difficult, especially for those low-resource languages. The lack of high-quality training data restricts the performance of models, resulting in poor user satisfaction. Therefore, we devise an efficient and effective training solution for multilingual task-orientated dialogue systems, using the same dataset generation pipeline and end-to-end dialogue system architecture as BiToD[5], which adopted some key design choices for a minimalistic natural language design where formal dialogue states are used in place of natural language inputs. This reduces the room for error brought by weaker natural language models, and ensures the model can correctly extract the essential slot values needed to perform dialogue state tracking (DST). Our goal is to reduce the amount of natural language encoded at each turn, and the key parameter we investigate is the number of turns (H) to feed as history to model. We first explore the turning point where increasing H begins to yield limiting returns on the overall performance. Then we examine whether the examples a model with small H gets wrong can be categorized in a way for the model to do few-shot finetuning on. Lastly, will explore the limitations of this approach, and whether there is a certain type of examples that this approach will not be able to resolve.
Overview of the Ninth Dialog System Technology Challenge: DSTC9
Nov 12, 2020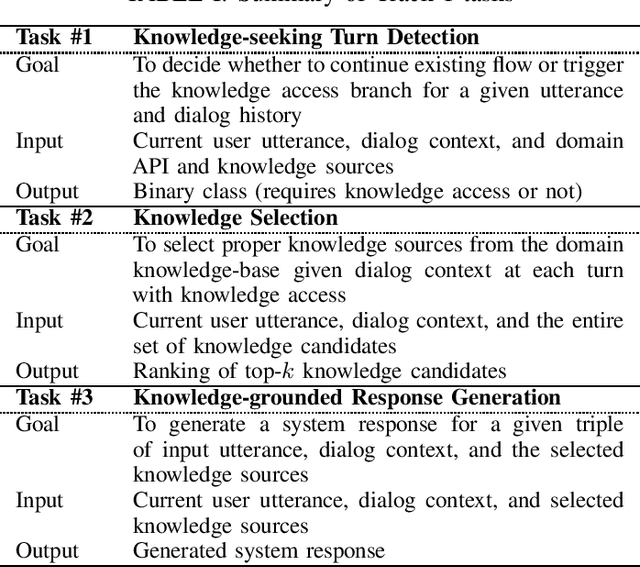
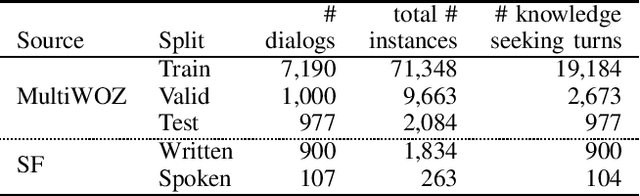

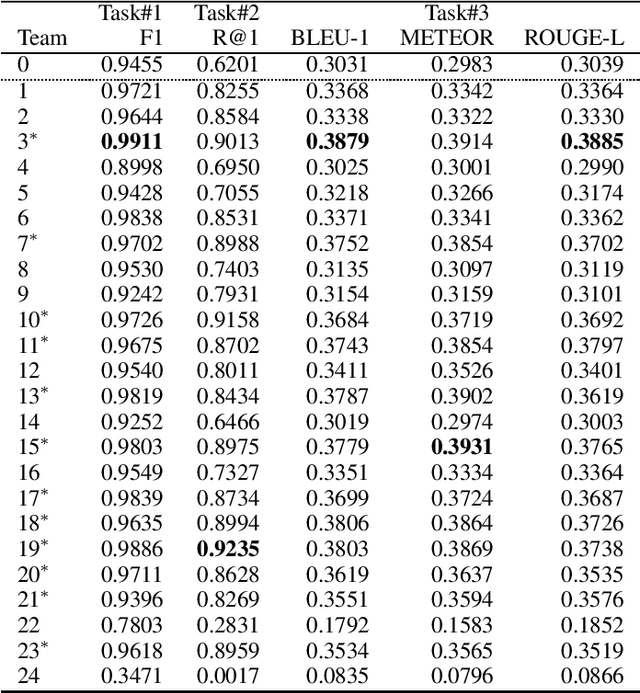
This paper introduces the Ninth Dialog System Technology Challenge (DSTC-9). This edition of the DSTC focuses on applying end-to-end dialog technologies for four distinct tasks in dialog systems, namely, 1. Task-oriented dialog Modeling with unstructured knowledge access, 2. Multi-domain task-oriented dialog, 3. Interactive evaluation of dialog, and 4. Situated interactive multi-modal dialog. This paper describes the task definition, provided datasets, baselines and evaluation set-up for each track. We also summarize the results of the submitted systems to highlight the overall trends of the state-of-the-art technologies for the tasks.
A Large-Scale Chinese Short-Text Conversation Dataset
Aug 10, 2020



The advancements of neural dialogue generation models show promising results on modeling short-text conversations. However, training such models usually needs a large-scale high-quality dialogue corpus, which is hard to access. In this paper, we present a large-scale cleaned Chinese conversation dataset, LCCC, which contains a base version (6.8million dialogues) and a large version (12.0 million dialogues). The quality of our dataset is ensured by a rigorous data cleaning pipeline, which is built based on a set of rules and a classifier that is trained on manually annotated 110K dialogue pairs. We also release pre-training dialogue models which are trained on LCCC-base and LCCC-large respectively. The cleaned dataset and the pre-training models will facilitate the research of short-text conversation modeling. All the models and datasets are available at https://github.com/thu-coai/CDial-GPT.
KdConv: A Chinese Multi-domain Dialogue Dataset Towards Multi-turn Knowledge-driven Conversation
Apr 08, 2020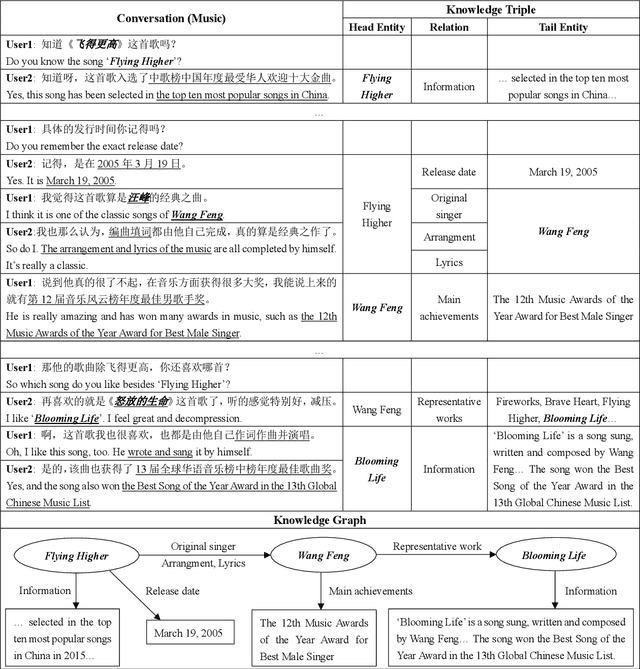



The research of knowledge-driven conversational systems is largely limited due to the lack of dialog data which consist of multi-turn conversations on multiple topics and with knowledge annotations. In this paper, we propose a Chinese multi-domain knowledge-driven conversation dataset, KdConv, which grounds the topics in multi-turn conversations to knowledge graphs. Our corpus contains 4.5K conversations from three domains (film, music, and travel), and 86K utterances with an average turn number of 19.0. These conversations contain in-depth discussions on related topics and natural transition between multiple topics. To facilitate the following research on this corpus, we provide several benchmark models. Comparative results show that the models can be enhanced by introducing background knowledge, yet there is still a large space for leveraging knowledge to model multi-turn conversations for further research. Results also show that there are obvious performance differences between different domains, indicating that it is worth to further explore transfer learning and domain adaptation. The corpus and benchmark models are publicly available.
CrossWOZ: A Large-Scale Chinese Cross-Domain Task-Oriented Dialogue Dataset
Feb 28, 2020


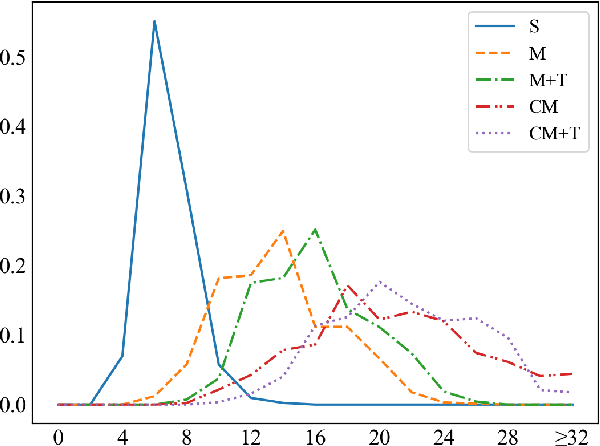
To advance multi-domain (cross-domain) dialogue modeling as well as alleviate the shortage of Chinese task-oriented datasets, we propose CrossWOZ, the first large-scale Chinese Cross-Domain Wizard-of-Oz task-oriented dataset. It contains 6K dialogue sessions and 102K utterances for 5 domains, including hotel, restaurant, attraction, metro, and taxi. Moreover, the corpus contains rich annotation of dialogue states and dialogue acts at both user and system sides. About 60% of the dialogues have cross-domain user goals that favor inter-domain dependency and encourage natural transition across domains in conversation. We also provide a user simulator and several benchmark models for pipelined task-oriented dialogue systems, which will facilitate researchers to compare and evaluate their models on this corpus. The large size and rich annotation of CrossWOZ make it suitable to investigate a variety of tasks in cross-domain dialogue modeling, such as dialogue state tracking, policy learning, user simulation, etc.