 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmark Underestimates the Readiness of Multi-lingual Dialogue Agents
May 28, 2024



Creating multilingual task-oriented dialogue (TOD) agents is challenging due to the high cost of training data acquisition. Following the research trend of improving training data efficiency, we show for the first time, that in-context learning is sufficient to tackle multilingual TOD. To handle the challenging dialogue state tracking (DST) subtask, we break it down to simpler steps that are more compatible with in-context learning where only a handful of few-shot examples are used. We test our approach on the multilingual TOD dataset X-RiSAWOZ, which has 12 domains in Chinese, English, French, Korean, Hindi, and code-mixed Hindi-English. Our turn-by-turn DST accuracy on the 6 languages range from 55.6% to 80.3%, seemingly worse than the SOTA results from fine-tuned models that achieve from 60.7% to 82.8%; our BLEU scores in the response generation (RG) subtask are also significantly lower than SOTA. However, after manual evaluation of the validation set, we find that by correcting gold label errors and improving dataset annotation schema, GPT-4 with our prompts can achieve (1) 89.6%-96.8% accuracy in DST, and (2) more than 99% correct response generation across different languages. This leads us to conclude that current automatic metrics heavily underestimate the effectiveness of in-context learning.
X-RiSAWOZ: High-Quality End-to-End Multilingual Dialogue Datasets and Few-shot Agents
Jun 30, 2023



Task-oriented dialogue research has mainly focused on a few popular languages like English and Chinese, due to the high dataset creation cost for a new language. To reduce the cost, we apply manual editing to automatically translated data. We create a new multilingual benchmark, X-RiSAWOZ, by translating the Chinese RiSAWOZ to 4 languages: English, French, Hindi, Korean; and a code-mixed English-Hindi language. X-RiSAWOZ has more than 18,000 human-verified dialogue utterances for each language, and unlike most multilingual prior work, is an end-to-end dataset for building fully-functioning agents. The many difficulties we encountered in creating X-RiSAWOZ led us to develop a toolset to accelerate the post-editing of a new language dataset after translation. This toolset improves machine translation with a hybrid entity alignment technique that combines neural with dictionary-based methods, along with many automated and semi-automated validation checks. We establish strong baselines for X-RiSAWOZ by training dialogue agents in the zero- and few-shot settings where limited gold data is available in the target language. Our results suggest that our translation and post-editing methodology and toolset can be used to create new high-quality multilingual dialogue agents cost-effectively. Our dataset, code, and toolkit are released open-source.
Zero and Few-Shot Localization of Task-Oriented Dialogue Agents with a Distilled Representation
Feb 18, 2023Task-oriented Dialogue (ToD) agents are mostly limited to a few widely-spoken languages, mainly due to the high cost of acquiring training data for each language. Existing low-cost approaches that rely on cross-lingual embeddings or naive machine translation sacrifice a lot of accuracy for data efficiency, and largely fail in creating a usable dialogue agent. We propose automatic methods that use ToD training data in a source language to build a high-quality functioning dialogue agent in another target language that has no training data (i.e. zero-shot) or a small training set (i.e. few-shot). Unlike most prior work in cross-lingual ToD that only focuses on Dialogue State Tracking (DST), we build an end-to-end agent. We show that our approach closes the accuracy gap between few-shot and existing full-shot methods for ToD agents. We achieve this by (1) improving the dialogue data representation, (2) improving entity-aware machine translation, and (3) automatic filtering of noisy translations. We evaluate our approach on the recent bilingual dialogue dataset BiToD. In Chinese to English transfer, in the zero-shot setting, our method achieves 46.7% and 22.0% in Task Success Rate (TSR) and Dialogue Success Rate (DSR) respectively. In the few-shot setting where 10% of the data in the target language is used, we improve the state-of-the-art by 15.2% and 14.0%, coming within 5% of full-shot training.
Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks
Apr 16, 2022

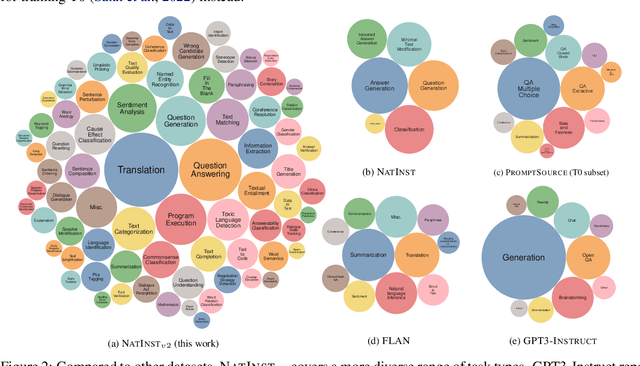
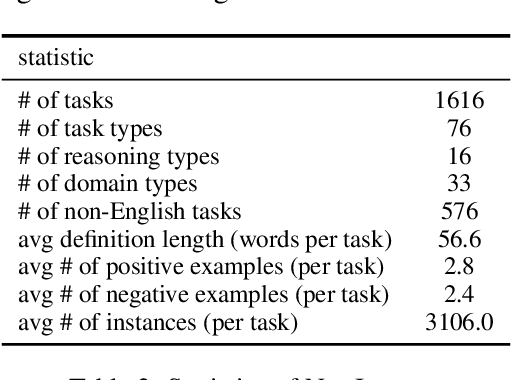
How can we measure the generalization of models to a variety of unseen tasks when provided with their language instructions? To facilitate progress in this goal, we introduce Natural-Instructions v2, a collection of 1,600+ diverse language tasks and their expert written instructions. More importantly, the benchmark covers 70+ distinct task types, such as tagging, in-filling, and rewriting. This benchmark is collected with contributions of NLP practitioners in the community and through an iterative peer review process to ensure their quality. This benchmark enables large-scale evaluation of cross-task generalization of the models -- training on a subset of tasks and evaluating on the remaining unseen ones. For instance, we are able to rigorously quantify generalization as a function of various scaling parameters, such as the number of observed tasks, the number of instances, and model sizes. As a by-product of these experiments. we introduce Tk-Instruct, an encoder-decoder Transformer that is trained to follow a variety of in-context instructions (plain language task definitions or k-shot examples) which outperforms existing larger models on our benchmark. We hope this benchmark facilitates future progress toward more general-purpose language understanding models.
ThingTalk: An Extensible, Executable Representation Language for Task-Oriented Dialogues
Mar 23, 2022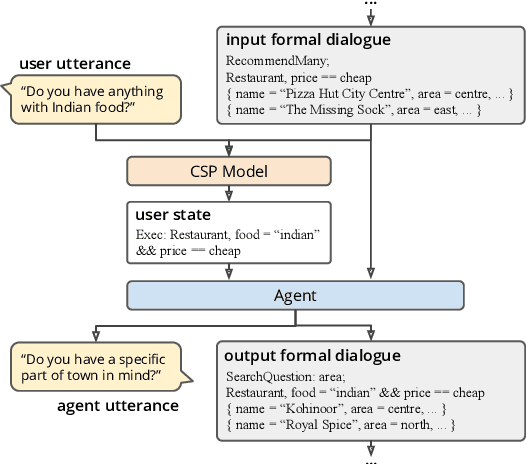
Task-oriented conversational agents rely on semantic parsers to translate natural language to formal representations. In this paper, we propose the design and rationale of the ThingTalk formal representation, and how the design improves the development of transactional task-oriented agents. ThingTalk is built on four core principles: (1) representing user requests directly as executable statements, covering all the functionality of the agent, (2) representing dialogues formally and succinctly to support accurate contextual semantic parsing, (3) standardizing types and interfaces to maximize reuse between agents, and (4) allowing multiple, independently-developed agents to be composed in a single virtual assistant. ThingTalk is developed as part of the Genie Framework that allows developers to quickly build transactional agents given a database and APIs. We compare ThingTalk to existing representations: SMCalFlow, SGD, TreeDST. Compared to the others, the ThingTalk design is both more general and more cost-effective. Evaluated on the MultiWOZ benchmark, using ThingTalk and associated tools yields a new state of the art accuracy of 79% turn-by-turn.
Investigating Effect of Dialogue History in Multilingual Task Oriented Dialogue Systems
Dec 23, 2021
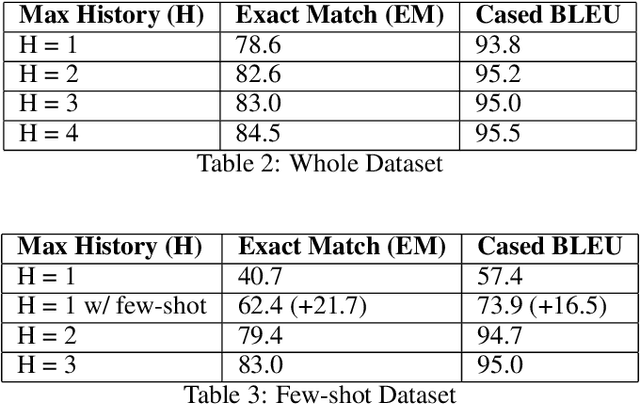
While the English virtual assistants have achieved exciting performance with an enormous amount of training resources, the needs of non-English-speakers have not been satisfied well. Up to Dec 2021, Alexa, one of the most popular smart speakers around the world, is able to support 9 different languages [1], while there are thousands of languages in the world, 91 of which are spoken by more than 10 million people according to statistics published in 2019 [2]. However, training a virtual assistant in other languages than English is often more difficult, especially for those low-resource languages. The lack of high-quality training data restricts the performance of models, resulting in poor user satisfaction. Therefore, we devise an efficient and effective training solution for multilingual task-orientated dialogue systems, using the same dataset generation pipeline and end-to-end dialogue system architecture as BiToD[5], which adopted some key design choices for a minimalistic natural language design where formal dialogue states are used in place of natural language inputs. This reduces the room for error brought by weaker natural language models, and ensures the model can correctly extract the essential slot values needed to perform dialogue state tracking (DST). Our goal is to reduce the amount of natural language encoded at each turn, and the key parameter we investigate is the number of turns (H) to feed as history to model. We first explore the turning point where increasing H begins to yield limiting returns on the overall performance. Then we examine whether the examples a model with small H gets wrong can be categorized in a way for the model to do few-shot finetuning on. Lastly, will explore the limitations of this approach, and whether there is a certain type of examples that this approach will not be able to resolve.
Contextual Semantic Parsing for Multilingual Task-Oriented Dialogues
Nov 04, 2021

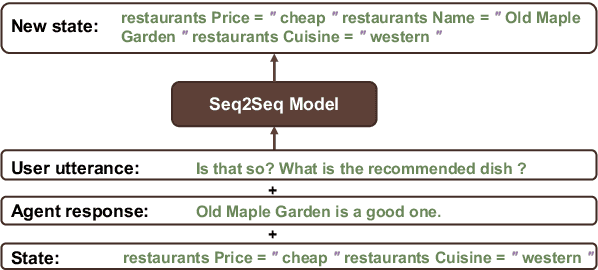

Robust state tracking for task-oriented dialogue systems currently remains restricted to a few popular languages. This paper shows that given a large-scale dialogue data set in one language, we can automatically produce an effective semantic parser for other languages using machine translation. We propose automatic translation of dialogue datasets with alignment to ensure faithful translation of slot values and eliminate costly human supervision used in previous benchmarks. We also propose a new contextual semantic parsing model, which encodes the formal slots and values, and only the last agent and user utterances. We show that the succinct representation reduces the compounding effect of translation errors, without harming the accuracy in practice. We evaluate our approach on several dialogue state tracking benchmarks. On RiSAWOZ, CrossWOZ, CrossWOZ-EN, and MultiWOZ-ZH datasets we improve the state of the art by 11%, 17%, 20%, and 0.3% in joint goal accuracy. We present a comprehensive error analysis for all three datasets showing erroneous annotations can obscure judgments on the quality of the model. Finally, we present RiSAWOZ English and German datasets, created using our translation methodology. On these datasets, accuracy is within 11% of the original showing that high-accuracy multilingual dialogue datasets are possible without relying on expensive human annotations.
Localizing Open-Ontology QA Semantic Parsers in a Day Using Machine Translation
Oct 10, 2020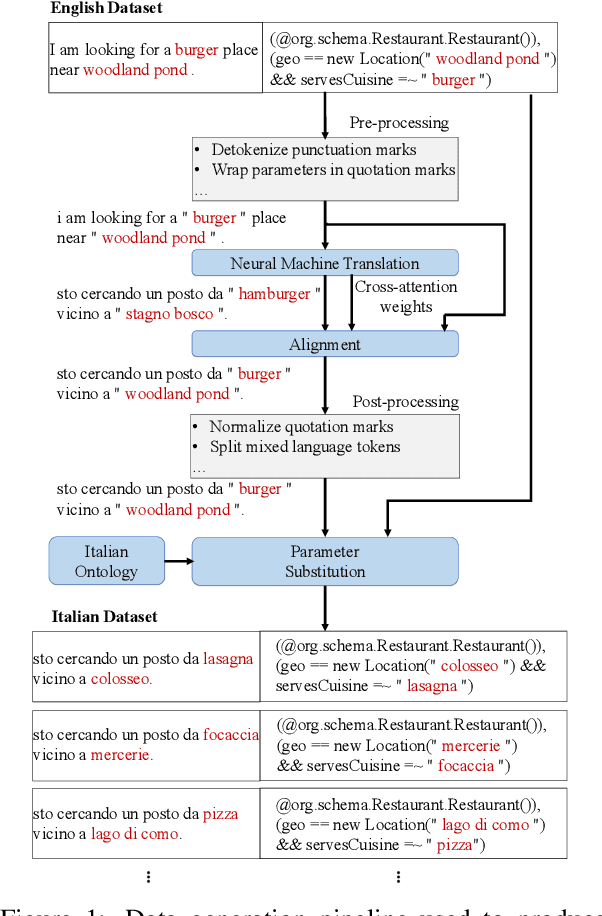

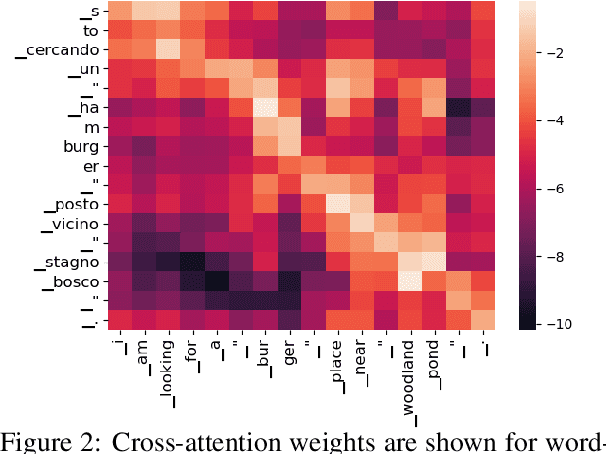
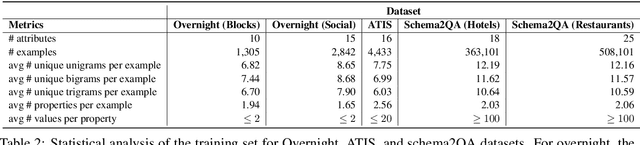
We propose Semantic Parser Localizer (SPL), a toolkit that leverages Neural Machine Translation (NMT) systems to localize a semantic parser for a new language. Our methodology is to (1) generate training data automatically in the target language by augmenting machine-translated datasets with local entities scraped from public websites, (2) add a few-shot boost of human-translated sentences and train a novel XLMR-LSTM semantic parser, and (3) test the model on natural utterances curated using human translators. We assess the effectiveness of our approach by extending the current capabilities of Schema2QA, a system for English Question Answering (QA) on the open web, to 10 new languages for the restaurants and hotels domains. Our models achieve an overall test accuracy ranging between 61% and 69% for the hotels domain and between 64% and 78% for restaurants domain, which compares favorably to 69% and 80% obtained for English parser trained on gold English data and a few examples from validation set. We show our approach outperforms the previous state-of-the-art methodology by more than 30% for hotels and 40% for restaurants with localized ontologies for the subset of languages tested. Our methodology enables any software developer to add a new language capability to a QA system for a new domain, leveraging machine translation, in less than 24 hours.
Zero-Shot Transfer Learning with Synthesized Data for Multi-Domain Dialogue State Tracking
May 02, 2020



Zero-shot transfer learning for multi-domain dialogue state tracking can allow us to handle new domains without incurring the high cost of data acquisition. This paper proposes new zero-short transfer learning technique for dialogue state tracking where the in-domain training data are all synthesized from an abstract dialogue model and the ontology of the domain. We show that data augmentation through synthesized data can improve the accuracy of zero-shot learning for both the TRADE model and the BERT-based SUMBT model on the MultiWOZ 2.1 dataset. We show training with only synthesized in-domain data on the SUMBT model can reach about 2/3 of the accuracy obtained with the full training dataset. We improve the zero-shot learning state of the art on average across domains by 21%.
HUBERT Untangles BERT to Improve Transfer across NLP Tasks
Oct 25, 2019
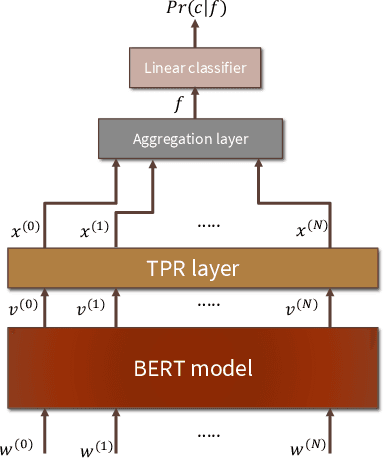


We introduce HUBERT which combines the structured-representational power of Tensor-Product Representations (TPRs) and BERT, a pre-trained bidirectional Transformer language model. We show that there is shared structure between different NLP datasets that HUBERT, but not BERT, is able to learn and leverage. We validate the effectiveness of our model on the GLUE benchmark and HANS dataset. Our experiment results show that untangling data-specific semantics from general language structure is key for better transfer among NLP tasks.