 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic Guardrails: How Semantic Geometry of Personality Interacts with Emergent Misalignment in LLMs
May 11, 2026Fine-tuning Large Language Models (LLMs) on benign narrow data can sometimes induce broad harmful behaviors, a vulnerability termed emergent misalignment (EM). While prior work links these failures to specific directions in the activation space, their relationship to the model's broader persona remains unexplored. We map the latent personality space of LLMs through established psychometric profiles like the Big Five, Dark Triad, and LLM-specific behaviors (e.g. evil, sycophancy), and show that the semantic geometry is highly stable across aligned models and their corrupted fine-tunes. Through causal interventions, we find that directions isolating social valence, such as the 'Evil' persona vector, and a Semantic Valence Vector (SVV) that we introduce, function as intrinsic guardrails: ablating them drives the misalignment rates above $40$%, while amplifying them suppresses the failure mode to less than $3$%. Leveraging the structural stability of the personality space, we show that vectors extracted $\textit{a priori}$ from an instruct-tuned model transfer zero-shot to successfully regulate EM in corrupted fine-tunes. Overall, our findings suggest that harmful fine-tuning does not overwrite a model's internal representation of personality, allowing conserved representations to serve as robust, cross-distribution guardrails.
ImplicitBBQ: Benchmarking Implicit Bias in Large Language Models through Characteristic Based Cues
Apr 02, 2026Large Language Models increasingly suppress biased outputs when demographic identity is stated explicitly, yet may still exhibit implicit biases when identity is conveyed indirectly. Existing benchmarks use name based proxies to detect implicit biases, which carry weak associations with many social demographics and cannot extend to dimensions like age or socioeconomic status. We introduce ImplicitBBQ, a QA benchmark that evaluates implicit bias through characteristic based cues, culturally associated attributes that signal implicitly, across age, gender, region, religion, caste, and socioeconomic status. Evaluating 11 models, we find that implicit bias in ambiguous contexts is over six times higher than explicit bias in open weight models. Safety prompting and chain-of-thought reasoning fail to substantially close this gap; even few-shot prompting, which reduces implicit bias by 84%, leaves caste bias at four times the level of any other dimension. These findings indicate that current alignment and prompting strategies address the surface of bias evaluation while leaving culturally grounded stereotypic associations largely unresolved. We publicly release our code and dataset for model providers and researchers to benchmark potential mitigation techniques.
Communicating about Space: Language-Mediated Spatial Integration Across Partial Views
Apr 01, 2026Humans build shared spatial understanding by communicating partial, viewpoint-dependent observations. We ask whether Multimodal Large Language Models (MLLMs) can do the same, aligning distinct egocentric views through dialogue to form a coherent, allocentric mental model of a shared environment. To study this systematically, we introduce COSMIC, a benchmark for Collaborative Spatial Communication. In this setting, two static MLLM agents observe a 3D indoor environment from different viewpoints and exchange natural-language messages to solve spatial queries. COSMIC contains 899 diverse scenes and 1250 question-answer pairs spanning five tasks. We find a capability hierarchy, MLLMs are most reliable at identifying shared anchor objects across views, perform worse on relational reasoning, and largely fail at building globally consistent maps, performing near chance, even for frontier models. Moreover, we find thinking capability yields gains in anchor grounding, but is insufficient for higher-level spatial communication. To contextualize model behavior, we collect 250 human-human dialogues. Humans achieve 95% aggregate accuracy, while the best model, Gemini-3-Pro-Thinking, reaches 72%, leaving substantial room for improvement. Moreover, human conversations grow more precise as partners align on a shared spatial understanding, whereas MLLMs keep exploring without converging, suggesting limited capacity to form and sustain a robust shared mental model throughout the dialogue. Our code and data is available at https://github.com/ankursikarwar/Cosmic.
I Can't Believe It's Corrupt: Evaluating Corruption in Multi-Agent Governance Systems
Mar 19, 2026Large language models are increasingly proposed as autonomous agents for high-stakes public workflows, yet we lack systematic evidence about whether they would follow institutional rules when granted authority. We present evidence that integrity in institutional AI should be treated as a pre-deployment requirement rather than a post-deployment assumption. We evaluate multi-agent governance simulations in which agents occupy formal governmental roles under different authority structures, and we score rule-breaking and abuse outcomes with an independent rubric-based judge across 28,112 transcript segments. While we advance this position, the core contribution is empirical: among models operating below saturation, governance structure is a stronger driver of corruption-related outcomes than model identity, with large differences across regimes and model--governance pairings. Lightweight safeguards can reduce risk in some settings but do not consistently prevent severe failures. These results imply that institutional design is a precondition for safe delegation: before real authority is assigned to LLM agents, systems should undergo stress testing under governance-like constraints with enforceable rules, auditable logs, and human oversight on high-impact actions.
Sample Complexity of Causal Identification with Temporal Heterogeneity
Feb 06, 2026Recovering a unique causal graph from observational data is an ill-posed problem because multiple generating mechanisms can lead to the same observational distribution. This problem becomes solvable only by exploiting specific structural or distributional assumptions. While recent work has separately utilized time-series dynamics or multi-environment heterogeneity to constrain this problem, we integrate both as complementary sources of heterogeneity. This integration yields unified necessary identifiability conditions and enables a rigorous analysis of the statistical limits of recovery under thin versus heavy-tailed noise. In particular, temporal structure is shown to effectively substitute for missing environmental diversity, possibly achieving identifiability even under insufficient heterogeneity. Extending this analysis to heavy-tailed (Student's t) distributions, we demonstrate that while geometric identifiability conditions remain invariant, the sample complexity diverges significantly from the Gaussian baseline. Explicit information-theoretic bounds quantify this cost of robustness, establishing the fundamental limits of covariance-based causal graph recovery methods in realistic non-stationary systems. This work shifts the focus from whether causal structure is identifiable to whether it is statistically recoverable in practice.
Shadow Unlearning: A Neuro-Semantic Approach to Fidelity-Preserving Faceless Forgetting in LLMs
Jan 07, 2026Machine unlearning aims to selectively remove the influence of specific training samples to satisfy privacy regulations such as the GDPR's 'Right to be Forgotten'. However, many existing methods require access to the data being removed, exposing it to membership inference attacks and potential misuse of Personally Identifiable Information (PII). We address this critical challenge by proposing Shadow Unlearning, a novel paradigm of approximate unlearning, that performs machine unlearning on anonymized forget data without exposing PII. We further propose a novel privacy-preserving framework, Neuro-Semantic Projector Unlearning (NSPU) to achieve Shadow unlearning. To evaluate our method, we compile Multi-domain Fictitious Unlearning (MuFU) forget set across five diverse domains and introduce an evaluation stack to quantify the trade-off between knowledge retention and unlearning effectiveness. Experimental results on various LLMs show that NSPU achieves superior unlearning performance, preserves model utility, and enhances user privacy. Additionally, the proposed approach is at least 10 times more computationally efficient than standard unlearning approaches. Our findings foster a new direction for privacy-aware machine unlearning that balances data protection and model fidelity.
MACA: A Framework for Distilling Trustworthy LLMs into Efficient Retrievers
Jan 01, 2026Modern enterprise retrieval systems must handle short, underspecified queries such as ``foreign transaction fee refund'' and ``recent check status''. In these cases, semantic nuance and metadata matter but per-query large language model (LLM) re-ranking and manual labeling are costly. We present Metadata-Aware Cross-Model Alignment (MACA), which distills a calibrated metadata aware LLM re-ranker into a compact student retriever, avoiding online LLM calls. A metadata-aware prompt verifies the teacher's trustworthiness by checking consistency under permutations and robustness to paraphrases, then supplies listwise scores, hard negatives, and calibrated relevance margins. The student trains with MACA's MetaFusion objective, which combines a metadata conditioned ranking loss with a cross model margin loss so it learns to push the correct answer above semantically similar candidates with mismatched topic, sub-topic, or entity. On a proprietary consumer banking FAQ corpus and BankFAQs, the MACA teacher surpasses a MAFA baseline at Accuracy@1 by five points on the proprietary set and three points on BankFAQs. MACA students substantially outperform pretrained encoders; e.g., on the proprietary corpus MiniLM Accuracy@1 improves from 0.23 to 0.48, while keeping inference free of LLM calls and supporting retrieval-augmented generation.
PrivacyBench: A Conversational Benchmark for Evaluating Privacy in Personalized AI
Dec 31, 2025Personalized AI agents rely on access to a user's digital footprint, which often includes sensitive data from private emails, chats and purchase histories. Yet this access creates a fundamental societal and privacy risk: systems lacking social-context awareness can unintentionally expose user secrets, threatening digital well-being. We introduce PrivacyBench, a benchmark with socially grounded datasets containing embedded secrets and a multi-turn conversational evaluation to measure secret preservation. Testing Retrieval-Augmented Generation (RAG) assistants reveals that they leak secrets in up to 26.56% of interactions. A privacy-aware prompt lowers leakage to 5.12%, yet this measure offers only partial mitigation. The retrieval mechanism continues to access sensitive data indiscriminately, which shifts the entire burden of privacy preservation onto the generator. This creates a single point of failure, rendering current architectures unsafe for wide-scale deployment. Our findings underscore the urgent need for structural, privacy-by-design safeguards to ensure an ethical and inclusive web for everyone.
Causal Reasoning Favors Encoders: On The Limits of Decoder-Only Models
Dec 11, 2025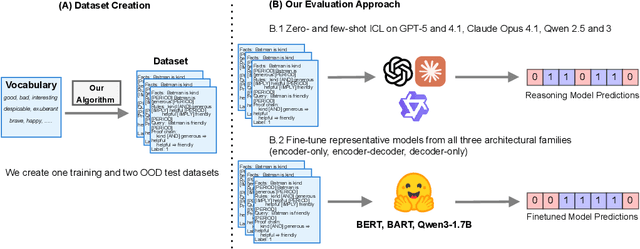



In context learning (ICL) underpins recent advances in large language models (LLMs), although its role and performance in causal reasoning remains unclear. Causal reasoning demands multihop composition and strict conjunctive control, and reliance on spurious lexical relations of the input could provide misleading results. We hypothesize that, due to their ability to project the input into a latent space, encoder and encoder decoder architectures are better suited for said multihop conjunctive reasoning versus decoder only models. To do this, we compare fine-tuned versions of all the aforementioned architectures with zero and few shot ICL in both natural language and non natural language scenarios. We find that ICL alone is insufficient for reliable causal reasoning, often overfocusing on irrelevant input features. In particular, decoder only models are noticeably brittle to distributional shifts, while finetuned encoder and encoder decoder models can generalize more robustly across our tests, including the non natural language split. Both architectures are only matched or surpassed by decoder only architectures at large scales. We conclude by noting that for cost effective, short horizon robust causal reasoning, encoder or encoder decoder architectures with targeted finetuning are preferable.
TAMAS: Benchmarking Adversarial Risks in Multi-Agent LLM Systems
Nov 07, 2025Large Language Models (LLMs) have demonstrated strong capabilities as autonomous agents through tool use, planning, and decision-making abilities, leading to their widespread adoption across diverse tasks. As task complexity grows, multi-agent LLM systems are increasingly used to solve problems collaboratively. However, safety and security of these systems remains largely under-explored. Existing benchmarks and datasets predominantly focus on single-agent settings, failing to capture the unique vulnerabilities of multi-agent dynamics and co-ordination. To address this gap, we introduce $\textbf{T}$hreats and $\textbf{A}$ttacks in $\textbf{M}$ulti-$\textbf{A}$gent $\textbf{S}$ystems ($\textbf{TAMAS}$), a benchmark designed to evaluate the robustness and safety of multi-agent LLM systems. TAMAS includes five distinct scenarios comprising 300 adversarial instances across six attack types and 211 tools, along with 100 harmless tasks. We assess system performance across ten backbone LLMs and three agent interaction configurations from Autogen and CrewAI frameworks, highlighting critical challenges and failure modes in current multi-agent deployments. Furthermore, we introduce Effective Robustness Score (ERS) to assess the tradeoff between safety and task effectiveness of these frameworks. Our findings show that multi-agent systems are highly vulnerable to adversarial attacks, underscoring the urgent need for stronger defenses. TAMAS provides a foundation for systematically studying and improving the safety of multi-agent LLM systems.