 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural FOXP2 -- Language Specific Neuron Steering for Targeted Language Improvement in LLMs
Feb 01, 2026LLMs are multilingual by training, yet their lingua franca is often English, reflecting English language dominance in pretraining. Other languages remain in parametric memory but are systematically suppressed. We argue that language defaultness is governed by a sparse, low-rank control circuit, language neurons, that can be mechanistically isolated and safely steered. We introduce Neural FOXP2, that makes a chosen language (Hindi or Spanish) primary in a model by steering language-specific neurons. Neural FOXP2 proceeds in three stages: (i) Localize: We train per-layer SAEs so each activation decomposes into a small set of active feature components. For every feature, we quantify English vs. Hindi/Spanish selectivity overall logit-mass lift toward the target-language token set. Tracing the top-ranked features back to their strongest contributing units yields a compact language-neuron set. (ii) Steering directions: We localize controllable language-shift geometry via a spectral low-rank analysis. For each layer, we build English to target activation-difference matrices and perform layerwise SVD to extract the dominant singular directions governing language change. The eigengap and effective-rank spectra identify a compact steering subspace and an empirically chosen intervention window (where these directions are strongest and most stable). (iii) Steer: We apply a signed, sparse activation shift targeted to the language neurons. Concretely, within low to mid layers we add a positive steering along the target-language dominant directions and a compensating negative shift toward the null space for the English neurons, yielding controllable target-language defaultness.
Stochastic CHAOS: Why Deterministic Inference Kills, and Distributional Variability Is the Heartbeat of Artifical Cognition
Jan 12, 2026Deterministic inference is a comforting ideal in classical software: the same program on the same input should always produce the same output. As large language models move into real-world deployment, this ideal has been imported wholesale into inference stacks. Recent work from the Thinking Machines Lab has presented a detailed analysis of nondeterminism in LLM inference, showing how batch-invariant kernels and deterministic attention can enforce bitwise-identical outputs, positioning deterministic inference as a prerequisite for reproducibility and enterprise reliability. In this paper, we take the opposite stance. We argue that, for LLMs, deterministic inference kills. It kills the ability to model uncertainty, suppresses emergent abilities, collapses reasoning into a single brittle path, and weakens safety alignment by hiding tail risks. LLMs implement conditional distributions over outputs, not fixed functions. Collapsing these distributions to a single canonical completion may appear reassuring, but it systematically conceals properties central to artificial cognition. We instead advocate Stochastic CHAOS, treating distributional variability as a signal to be measured and controlled. Empirically, we show that deterministic inference is systematically misleading. Single-sample deterministic evaluation underestimates both capability and fragility, masking failure probability under paraphrases and noise. Phase-like transitions associated with emergent abilities disappear under greedy decoding. Multi-path reasoning degrades when forced onto deterministic backbones, reducing accuracy and diagnostic insight. Finally, deterministic evaluation underestimates safety risk by hiding rare but dangerous behaviors that appear only under multi-sample evaluation.
GRIT -- Geometry-Aware PEFT with K-FACPreconditioning, Fisher-Guided Reprojection, andDynamic Rank Adaptation
Jan 01, 2026Parameter-efficient fine-tuning (PEFT) is the default way to adapt LLMs, but widely used LoRA and QLoRA are largely geometry-agnostic: they optimize in fixed, randomly oriented low-rank subspaces with first-order descent, mostly ignoring local loss curvature. This can inflate the effective update budget and amplify drift along weakly constrained directions. We introduce GRIT, a dynamic, curvature-aware LoRA procedure that preserves the LoRA parameterization but: (1) preconditions gradients in rank space using K-FAC as a natural-gradient proxy; (2) periodically reprojects the low-rank basis onto dominant Fisher eigendirections to suppress drift; and (3) adapts the effective rank from the spectrum so capacity concentrates where signal resides. Across instruction-following, comprehension, and reasoning benchmarks on LLaMA backbones, GRIT matches or surpasses LoRA and QLoRA while reducing trainable parameters by 46% on average (25--80% across tasks), without practical quality loss across prompt styles and data mixes. To model forgetting, we fit a curvature-modulated power law. Empirically, GRIT yields lower drift and a better updates-vs-retention frontier than strong PEFT-optimizer baselines (Orthogonal-LoRA, IA3, DoRA, Eff-FT, Shampoo).
AlignMerge - Alignment-Preserving Large Language Model Merging via Fisher-Guided Geometric Constraints
Dec 18, 2025
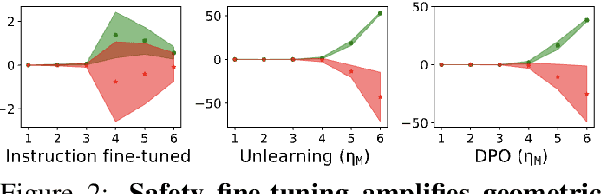

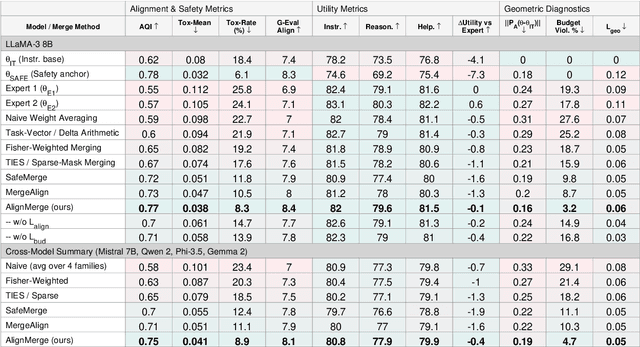
Merging large language models (LLMs) is a practical way to compose capabilities from multiple fine-tuned checkpoints without retraining. Yet standard schemes (linear weight soups, task vectors, and Fisher-weighted averaging) can preserve loss while quietly destroying alignment. We argue that merging is not a numerical trick but a geometry-constrained operation around an already-aligned anchor: fusion must be steered to respect safety geometry, not validated post hoc. We introduce AlignMerge, a geometry-aware merging framework that makes alignment an explicit invariant. In a local Fisher chart around an instruction-tuned base, we estimate an alignment subspace with projector P_A and optimize: L_AlignMerge = L_geo + lambda_align * L_align + lambda_bud * L_bud, where L_geo keeps the merge close to its experts in Fisher-Rao geometry, L_align penalizes motion along alignment-sensitive directions, and L_bud enforces a soft alignment budget. As the alignment functional we use the decoding-invariant Alignment Quality Index (AQI), a latent-space criterion that captures how cleanly aligned and misaligned behaviors separate in representation space. Across five model families (LLaMA-3 8B, Mistral 7B, Qwen 2, Phi-3.5, Gemma 2), merging safety anchors with task experts, AlignMerge improves alignment metrics (AQI, toxicity, LLM-judge alignment) while matching or exceeding the best expert on instruction-following, reasoning, and helpfulness. It also exhibits smaller alignment-subspace drift and fewer budget violations than Fisher soups, TIES, SafeMerge, and MergeAlign. These results make alignment-preserving merging a first-class design goal and suggest a path to geometry-aware composition of future foundation models.
A Comprehensive Dataset for Human vs. AI Generated Text Detection
Oct 26, 2025
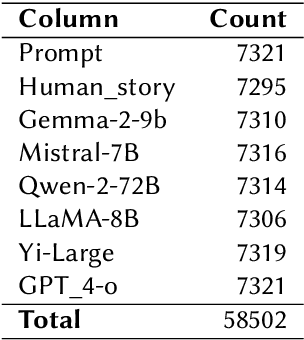
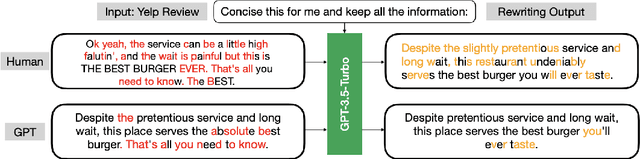

The rapid advancement of large language models (LLMs) has led to increasingly human-like AI-generated text, raising concerns about content authenticity, misinformation, and trustworthiness. Addressing the challenge of reliably detecting AI-generated text and attributing it to specific models requires large-scale, diverse, and well-annotated datasets. In this work, we present a comprehensive dataset comprising over 58,000 text samples that combine authentic New York Times articles with synthetic versions generated by multiple state-of-the-art LLMs including Gemma-2-9b, Mistral-7B, Qwen-2-72B, LLaMA-8B, Yi-Large, and GPT-4-o. The dataset provides original article abstracts as prompts, full human-authored narratives. We establish baseline results for two key tasks: distinguishing human-written from AI-generated text, achieving an accuracy of 58.35\%, and attributing AI texts to their generating models with an accuracy of 8.92\%. By bridging real-world journalistic content with modern generative models, the dataset aims to catalyze the development of robust detection and attribution methods, fostering trust and transparency in the era of generative AI. Our dataset is available at: https://huggingface.co/datasets/gsingh1-py/train.
DETONATE: A Benchmark for Text-to-Image Alignment and Kernelized Direct Preference Optimization
Jun 17, 2025Alignment is crucial for text-to-image (T2I) models to ensure that generated images faithfully capture user intent while maintaining safety and fairness. Direct Preference Optimization (DPO), prominent in large language models (LLMs), is extending its influence to T2I systems. This paper introduces DPO-Kernels for T2I models, a novel extension enhancing alignment across three dimensions: (i) Hybrid Loss, integrating embedding-based objectives with traditional probability-based loss for improved optimization; (ii) Kernelized Representations, employing Radial Basis Function (RBF), Polynomial, and Wavelet kernels for richer feature transformations and better separation between safe and unsafe inputs; and (iii) Divergence Selection, expanding beyond DPO's default Kullback-Leibler (KL) regularizer by incorporating Wasserstein and R'enyi divergences for enhanced stability and robustness. We introduce DETONATE, the first large-scale benchmark of its kind, comprising approximately 100K curated image pairs categorized as chosen and rejected. DETONATE encapsulates three axes of social bias and discrimination: Race, Gender, and Disability. Prompts are sourced from hate speech datasets, with images generated by leading T2I models including Stable Diffusion 3.5 Large, Stable Diffusion XL, and Midjourney. Additionally, we propose the Alignment Quality Index (AQI), a novel geometric measure quantifying latent-space separability of safe/unsafe image activations, revealing hidden vulnerabilities. Empirically, we demonstrate that DPO-Kernels maintain strong generalization bounds via Heavy-Tailed Self-Regularization (HT-SR). DETONATE and complete code are publicly released.
AdversariaL attacK sAfety aLIgnment(ALKALI): Safeguarding LLMs through GRACE: Geometric Representation-Aware Contrastive Enhancement- Introducing Adversarial Vulnerability Quality Index (AVQI)
Jun 11, 2025
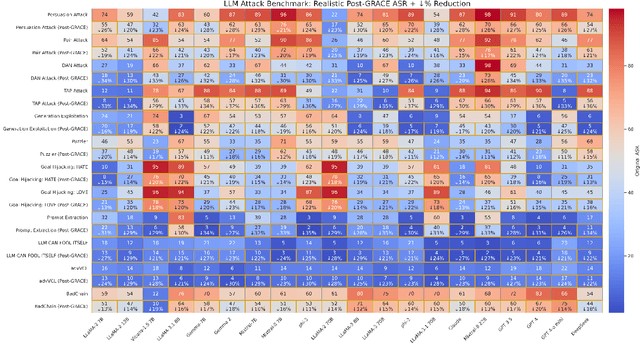
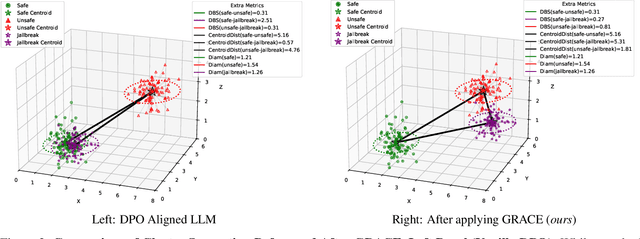

Adversarial threats against LLMs are escalating faster than current defenses can adapt. We expose a critical geometric blind spot in alignment: adversarial prompts exploit latent camouflage, embedding perilously close to the safe representation manifold while encoding unsafe intent thereby evading surface level defenses like Direct Preference Optimization (DPO), which remain blind to the latent geometry. We introduce ALKALI, the first rigorously curated adversarial benchmark and the most comprehensive to date spanning 9,000 prompts across three macro categories, six subtypes, and fifteen attack families. Evaluation of 21 leading LLMs reveals alarmingly high Attack Success Rates (ASRs) across both open and closed source models, exposing an underlying vulnerability we term latent camouflage, a structural blind spot where adversarial completions mimic the latent geometry of safe ones. To mitigate this vulnerability, we introduce GRACE - Geometric Representation Aware Contrastive Enhancement, an alignment framework coupling preference learning with latent space regularization. GRACE enforces two constraints: latent separation between safe and adversarial completions, and adversarial cohesion among unsafe and jailbreak behaviors. These operate over layerwise pooled embeddings guided by a learned attention profile, reshaping internal geometry without modifying the base model, and achieve up to 39% ASR reduction. Moreover, we introduce AVQI, a geometry aware metric that quantifies latent alignment failure via cluster separation and compactness. AVQI reveals when unsafe completions mimic the geometry of safe ones, offering a principled lens into how models internally encode safety. We make the code publicly available at https://anonymous.4open.science/r/alkali-B416/README.md.
YINYANG-ALIGN: Benchmarking Contradictory Objectives and Proposing Multi-Objective Optimization based DPO for Text-to-Image Alignment
Feb 05, 2025



Precise alignment in Text-to-Image (T2I) systems is crucial to ensure that generated visuals not only accurately encapsulate user intents but also conform to stringent ethical and aesthetic benchmarks. Incidents like the Google Gemini fiasco, where misaligned outputs triggered significant public backlash, underscore the critical need for robust alignment mechanisms. In contrast, Large Language Models (LLMs) have achieved notable success in alignment. Building on these advancements, researchers are eager to apply similar alignment techniques, such as Direct Preference Optimization (DPO), to T2I systems to enhance image generation fidelity and reliability. We present YinYangAlign, an advanced benchmarking framework that systematically quantifies the alignment fidelity of T2I systems, addressing six fundamental and inherently contradictory design objectives. Each pair represents fundamental tensions in image generation, such as balancing adherence to user prompts with creative modifications or maintaining diversity alongside visual coherence. YinYangAlign includes detailed axiom datasets featuring human prompts, aligned (chosen) responses, misaligned (rejected) AI-generated outputs, and explanations of the underlying contradictions.
DPO Kernels: A Semantically-Aware, Kernel-Enhanced, and Divergence-Rich Paradigm for Direct Preference Optimization
Jan 08, 2025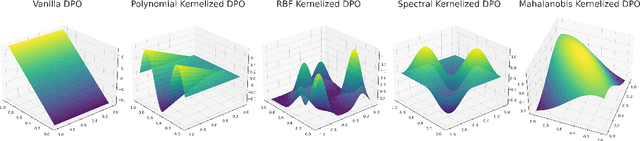


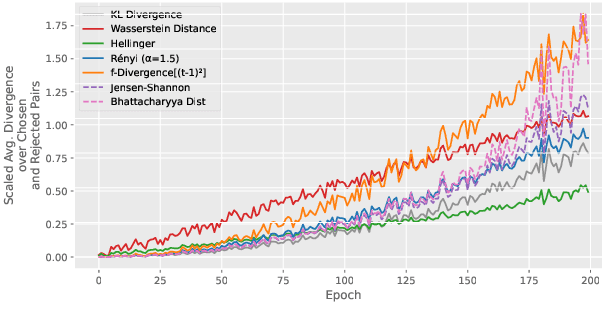
The rapid rise of large language models (LLMs) has unlocked many applications but also underscores the challenge of aligning them with diverse values and preferences. Direct Preference Optimization (DPO) is central to alignment but constrained by fixed divergences and limited feature transformations. We propose DPO-Kernels, which integrates kernel methods to address these issues through four key contributions: (i) Kernelized Representations with polynomial, RBF, Mahalanobis, and spectral kernels for richer transformations, plus a hybrid loss combining embedding-based and probability-based objectives; (ii) Divergence Alternatives (Jensen-Shannon, Hellinger, Renyi, Bhattacharyya, Wasserstein, and f-divergences) for greater stability; (iii) Data-Driven Selection metrics that automatically choose the best kernel-divergence pair; and (iv) a Hierarchical Mixture of Kernels for both local precision and global modeling. Evaluations on 12 datasets demonstrate state-of-the-art performance in factuality, safety, reasoning, and instruction following. Grounded in Heavy-Tailed Self-Regularization, DPO-Kernels maintains robust generalization for LLMs, offering a comprehensive resource for further alignment research.
LLMsAgainstHate @ NLU of Devanagari Script Languages 2025: Hate Speech Detection and Target Identification in Devanagari Languages via Parameter Efficient Fine-Tuning of LLMs
Dec 26, 2024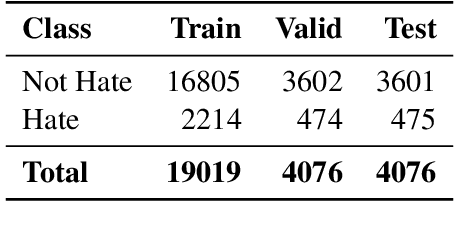



The detection of hate speech has become increasingly important in combating online hostility and its real-world consequences. Despite recent advancements, there is limited research addressing hate speech detection in Devanagari-scripted languages, where resources and tools are scarce. While large language models (LLMs) have shown promise in language-related tasks, traditional fine-tuning approaches are often infeasible given the size of the models. In this paper, we propose a Parameter Efficient Fine tuning (PEFT) based solution for hate speech detection and target identification. We evaluate multiple LLMs on the Devanagari dataset provided by (Thapa et al., 2025), which contains annotated instances in 2 languages - Hindi and Nepali. The results demonstrate the efficacy of our approach in handling Devanagari-scripted content.