 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Dataset for Human vs. AI Generated Text Detection
Oct 26, 2025
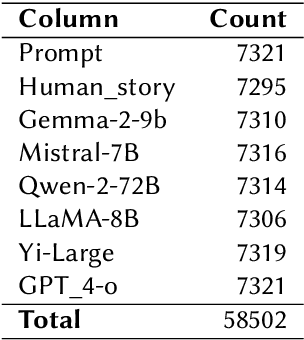

The rapid advancement of large language models (LLMs) has led to increasingly human-like AI-generated text, raising concerns about content authenticity, misinformation, and trustworthiness. Addressing the challenge of reliably detecting AI-generated text and attributing it to specific models requires large-scale, diverse, and well-annotated datasets. In this work, we present a comprehensive dataset comprising over 58,000 text samples that combine authentic New York Times articles with synthetic versions generated by multiple state-of-the-art LLMs including Gemma-2-9b, Mistral-7B, Qwen-2-72B, LLaMA-8B, Yi-Large, and GPT-4-o. The dataset provides original article abstracts as prompts, full human-authored narratives. We establish baseline results for two key tasks: distinguishing human-written from AI-generated text, achieving an accuracy of 58.35\%, and attributing AI texts to their generating models with an accuracy of 8.92\%. By bridging real-world journalistic content with modern generative models, the dataset aims to catalyze the development of robust detection and attribution methods, fostering trust and transparency in the era of generative AI. Our dataset is available at: https://huggingface.co/datasets/gsingh1-py/train.
Towards Physics-informed Diffusion for Anomaly Detection in Trajectories
Jun 08, 2025Given trajectory data, a domain-specific study area, and a user-defined threshold, we aim to find anomalous trajectories indicative of possible GPS spoofing (e.g., fake trajectory). The problem is societally important to curb illegal activities in international waters, such as unauthorized fishing and illicit oil transfers. The problem is challenging due to advances in AI generated in deep fakes generation (e.g., additive noise, fake trajectories) and lack of adequate amount of labeled samples for ground-truth verification. Recent literature shows promising results for anomalous trajectory detection using generative models despite data sparsity. However, they do not consider fine-scale spatiotemporal dependencies and prior physical knowledge, resulting in higher false-positive rates. To address these limitations, we propose a physics-informed diffusion model that integrates kinematic constraints to identify trajectories that do not adhere to physical laws. Experimental results on real-world datasets in the maritime and urban domains show that the proposed framework results in higher prediction accuracy and lower estimation error rate for anomaly detection and trajectory generation methods, respectively. Our implementation is available at https://github.com/arunshar/Physics-Informed-Diffusion-Probabilistic-Model.
Efficient and Direct Duplex Modeling for Speech-to-Speech Language Model
May 21, 2025
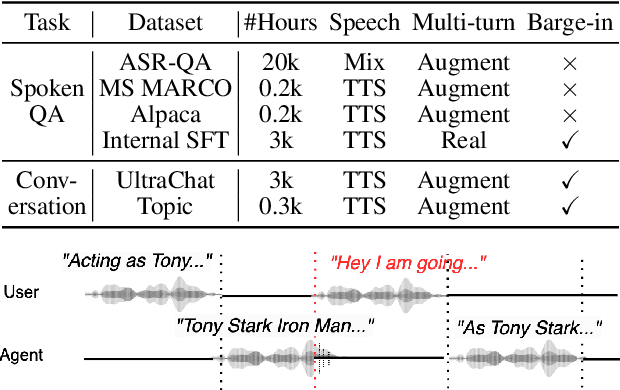
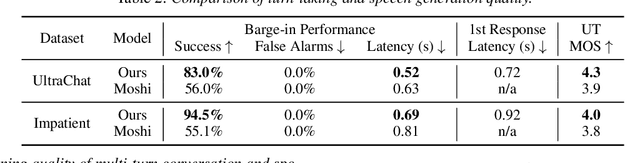

Spoken dialogue is an intuitive form of human-computer interaction, yet current speech language models often remain constrained to turn-based exchanges, lacking real-time adaptability such as user barge-in. We propose a novel duplex speech to speech (S2S) architecture featuring continuous user inputs and codec agent outputs with channel fusion that directly models simultaneous user and agent streams. Using a pretrained streaming encoder for user input enables the first duplex S2S model without requiring speech pretrain. Separate architectures for agent and user modeling facilitate codec fine-tuning for better agent voices and halve the bitrate (0.6 kbps) compared to previous works. Experimental results show that the proposed model outperforms previous duplex models in reasoning, turn-taking, and barge-in abilities. The model requires significantly less speech data, as speech pretrain is skipped, which markedly simplifies the process of building a duplex S2S model from any LLMs. Finally, it is the first openly available duplex S2S model with training and inference code to foster reproducibility.
Building Machine Learning Challenges for Anomaly Detection in Science
Mar 03, 2025



Scientific discoveries are often made by finding a pattern or object that was not predicted by the known rules of science. Oftentimes, these anomalous events or objects that do not conform to the norms are an indication that the rules of science governing the data are incomplete, and something new needs to be present to explain these unexpected outliers. The challenge of finding anomalies can be confounding since it requires codifying a complete knowledge of the known scientific behaviors and then projecting these known behaviors on the data to look for deviations. When utilizing machine learning, this presents a particular challenge since we require that the model not only understands scientific data perfectly but also recognizes when the data is inconsistent and out of the scope of its trained behavior. In this paper, we present three datasets aimed at developing machine learning-based anomaly detection for disparate scientific domains covering astrophysics, genomics, and polar science. We present the different datasets along with a scheme to make machine learning challenges around the three datasets findable, accessible, interoperable, and reusable (FAIR). Furthermore, we present an approach that generalizes to future machine learning challenges, enabling the possibility of large, more compute-intensive challenges that can ultimately lead to scientific discovery.
Spatial Distribution-Shift Aware Knowledge-Guided Machine Learning
Feb 20, 2025



Given inputs of diverse soil characteristics and climate data gathered from various regions, we aimed to build a model to predict accurate land emissions. The problem is important since accurate quantification of the carbon cycle in agroecosystems is crucial for mitigating climate change and ensuring sustainable food production. Predicting accurate land emissions is challenging since calibrating the heterogeneous nature of soil properties, moisture, and environmental conditions is hard at decision-relevant scales. Traditional approaches do not adequately estimate land emissions due to location-independent parameters failing to leverage the spatial heterogeneity and also require large datasets. To overcome these limitations, we proposed Spatial Distribution-Shift Aware Knowledge-Guided Machine Learning (SDSA-KGML), which leverages location-dependent parameters that account for significant spatial heterogeneity in soil moisture from multiple sites within the same region. Experimental results demonstrate that SDSA-KGML models achieve higher local accuracy for the specified states in the Midwest Region.
d-Sketch: Improving Visual Fidelity of Sketch-to-Image Translation with Pretrained Latent Diffusion Models without Retraining
Feb 19, 2025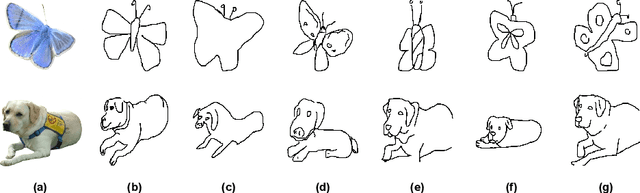
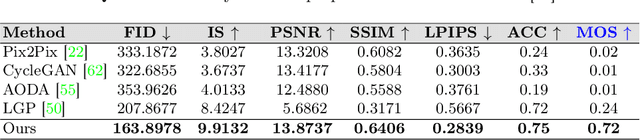

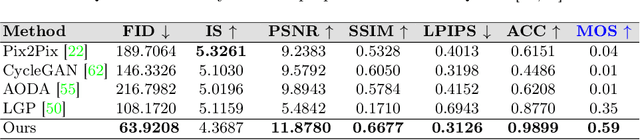
Structural guidance in an image-to-image translation allows intricate control over the shapes of synthesized images. Generating high-quality realistic images from user-specified rough hand-drawn sketches is one such task that aims to impose a structural constraint on the conditional generation process. While the premise is intriguing for numerous use cases of content creation and academic research, the problem becomes fundamentally challenging due to substantial ambiguities in freehand sketches. Furthermore, balancing the trade-off between shape consistency and realistic generation contributes to additional complexity in the process. Existing approaches based on Generative Adversarial Networks (GANs) generally utilize conditional GANs or GAN inversions, often requiring application-specific data and optimization objectives. The recent introduction of Denoising Diffusion Probabilistic Models (DDPMs) achieves a generational leap for low-level visual attributes in general image synthesis. However, directly retraining a large-scale diffusion model on a domain-specific subtask is often extremely difficult due to demanding computation costs and insufficient data. In this paper, we introduce a technique for sketch-to-image translation by exploiting the feature generalization capabilities of a large-scale diffusion model without retraining. In particular, we use a learnable lightweight mapping network to achieve latent feature translation from source to target domain. Experimental results demonstrate that the proposed method outperforms the existing techniques in qualitative and quantitative benchmarks, allowing high-resolution realistic image synthesis from rough hand-drawn sketches.
Exploring Mutual Cross-Modal Attention for Context-Aware Human Affordance Generation
Feb 19, 2025



Human affordance learning investigates contextually relevant novel pose prediction such that the estimated pose represents a valid human action within the scene. While the task is fundamental to machine perception and automated interactive navigation agents, the exponentially large number of probable pose and action variations make the problem challenging and non-trivial. However, the existing datasets and methods for human affordance prediction in 2D scenes are significantly limited in the literature. In this paper, we propose a novel cross-attention mechanism to encode the scene context for affordance prediction by mutually attending spatial feature maps from two different modalities. The proposed method is disentangled among individual subtasks to efficiently reduce the problem complexity. First, we sample a probable location for a person within the scene using a variational autoencoder (VAE) conditioned on the global scene context encoding. Next, we predict a potential pose template from a set of existing human pose candidates using a classifier on the local context encoding around the predicted location. In the subsequent steps, we use two VAEs to sample the scale and deformation parameters for the predicted pose template by conditioning on the local context and template class. Our experiments show significant improvements over the previous baseline of human affordance injection into complex 2D scenes.
Koel-TTS: Enhancing LLM based Speech Generation with Preference Alignment and Classifier Free Guidance
Feb 07, 2025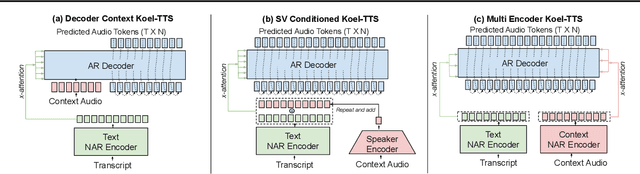
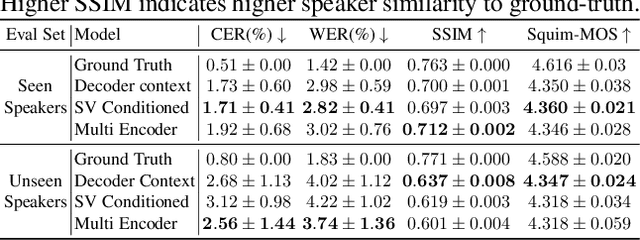
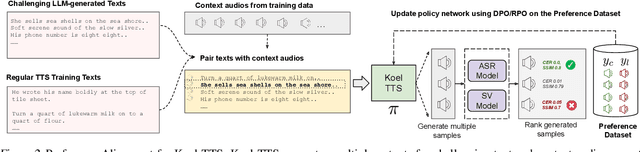
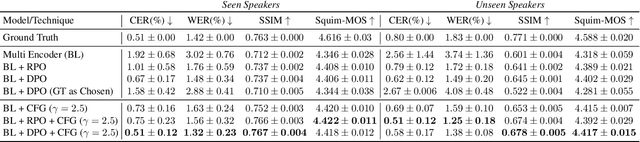
While autoregressive speech token generation models produce speech with remarkable variety and naturalness, their inherent lack of controllability often results in issues such as hallucinations and undesired vocalizations that do not conform to conditioning inputs. We introduce Koel-TTS, a suite of enhanced encoder-decoder Transformer TTS models that address these challenges by incorporating preference alignment techniques guided by automatic speech recognition and speaker verification models. Additionally, we incorporate classifier-free guidance to further improve synthesis adherence to the transcript and reference speaker audio. Our experiments demonstrate that these optimizations significantly enhance target speaker similarity, intelligibility, and naturalness of synthesized speech. Notably, Koel-TTS directly maps text and context audio to acoustic tokens, and on the aforementioned metrics, outperforms state-of-the-art TTS models, despite being trained on a significantly smaller dataset. Audio samples and demos are available on our website.
TTS-Transducer: End-to-End Speech Synthesis with Neural Transducer
Jan 10, 2025This work introduces TTS-Transducer - a novel architecture for text-to-speech, leveraging the strengths of audio codec models and neural transducers. Transducers, renowned for their superior quality and robustness in speech recognition, are employed to learn monotonic alignments and allow for avoiding using explicit duration predictors. Neural audio codecs efficiently compress audio into discrete codes, revealing the possibility of applying text modeling approaches to speech generation. However, the complexity of predicting multiple tokens per frame from several codebooks, as necessitated by audio codec models with residual quantizers, poses a significant challenge. The proposed system first uses a transducer architecture to learn monotonic alignments between tokenized text and speech codec tokens for the first codebook. Next, a non-autoregressive Transformer predicts the remaining codes using the alignment extracted from transducer loss. The proposed system is trained end-to-end. We show that TTS-Transducer is a competitive and robust alternative to contemporary TTS systems.
Visual Counter Turing Test (VCT^2): Discovering the Challenges for AI-Generated Image Detection and Introducing Visual AI Index (V_AI)
Nov 24, 2024



The proliferation of AI techniques for image generation, coupled with their increasing accessibility, has raised significant concerns about the potential misuse of these images to spread misinformation. Recent AI-generated image detection (AGID) methods include CNNDetection, NPR, DM Image Detection, Fake Image Detection, DIRE, LASTED, GAN Image Detection, AIDE, SSP, DRCT, RINE, OCC-CLIP, De-Fake, and Deep Fake Detection. However, we argue that the current state-of-the-art AGID techniques are inadequate for effectively detecting contemporary AI-generated images and advocate for a comprehensive reevaluation of these methods. We introduce the Visual Counter Turing Test (VCT^2), a benchmark comprising ~130K images generated by contemporary text-to-image models (Stable Diffusion 2.1, Stable Diffusion XL, Stable Diffusion 3, DALL-E 3, and Midjourney 6). VCT^2 includes two sets of prompts sourced from tweets by the New York Times Twitter account and captions from the MS COCO dataset. We also evaluate the performance of the aforementioned AGID techniques on the VCT$^2$ benchmark, highlighting their ineffectiveness in detecting AI-generated images. As image-generative AI models continue to evolve, the need for a quantifiable framework to evaluate these models becomes increasingly critical. To meet this need, we propose the Visual AI Index (V_AI), which assesses generated images from various visual perspectives, including texture complexity and object coherence, setting a new standard for evaluating image-generative AI models. To foster research in this domain, we make our https://huggingface.co/datasets/anonymous1233/COCO_AI and https://huggingface.co/datasets/anonymous1233/twitter_AI datasets publicly available.