 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Judge a Book by its Cover: Testing LLMs' Robustness Under Logical Obfuscation
Feb 01, 2026Tasks such as solving arithmetic equations, evaluating truth tables, and completing syllogisms are handled well by large language models (LLMs) in their standard form, but they often fail when the same problems are posed in logically equivalent yet obfuscated formats. To study this vulnerability, we introduce Logifus, a structure-preserving logical obfuscation framework, and, utilizing this, we present LogiQAte, a first-of-its-kind diagnostic benchmark with 1,108 questions across four reasoning tasks: (i) Obfus FOL (first-order logic entailment under equivalence-preserving rewrites), (ii) Obfus Blood Relation (family-graph entailment under indirect relational chains), (iii) Obfus Number Series (pattern induction under symbolic substitutions), and (iv) Obfus Direction Sense (navigation reasoning under altered directions and reference frames). Across all the tasks, evaluating six state-of-the-art models, we find that obfuscation severely degrades zero-shot performance, with performance dropping on average by 47% for GPT-4o, 27% for GPT-5, and 22% for reasoning model, o4-mini. Our findings reveal that current LLMs parse questions without deep understanding, highlighting the urgency of building models that genuinely comprehend and preserve meaning beyond surface form.
ObfusQAte: A Proposed Framework to Evaluate LLM Robustness on Obfuscated Factual Question Answering
Aug 10, 2025The rapid proliferation of Large Language Models (LLMs) has significantly contributed to the development of equitable AI systems capable of factual question-answering (QA). However, no known study tests the LLMs' robustness when presented with obfuscated versions of questions. To systematically evaluate these limitations, we propose a novel technique, ObfusQAte and, leveraging the same, introduce ObfusQA, a comprehensive, first of its kind, framework with multi-tiered obfuscation levels designed to examine LLM capabilities across three distinct dimensions: (i) Named-Entity Indirection, (ii) Distractor Indirection, and (iii) Contextual Overload. By capturing these fine-grained distinctions in language, ObfusQA provides a comprehensive benchmark for evaluating LLM robustness and adaptability. Our study observes that LLMs exhibit a tendency to fail or generate hallucinated responses when confronted with these increasingly nuanced variations. To foster research in this direction, we make ObfusQAte publicly available.
DETONATE: A Benchmark for Text-to-Image Alignment and Kernelized Direct Preference Optimization
Jun 17, 2025Alignment is crucial for text-to-image (T2I) models to ensure that generated images faithfully capture user intent while maintaining safety and fairness. Direct Preference Optimization (DPO), prominent in large language models (LLMs), is extending its influence to T2I systems. This paper introduces DPO-Kernels for T2I models, a novel extension enhancing alignment across three dimensions: (i) Hybrid Loss, integrating embedding-based objectives with traditional probability-based loss for improved optimization; (ii) Kernelized Representations, employing Radial Basis Function (RBF), Polynomial, and Wavelet kernels for richer feature transformations and better separation between safe and unsafe inputs; and (iii) Divergence Selection, expanding beyond DPO's default Kullback-Leibler (KL) regularizer by incorporating Wasserstein and R'enyi divergences for enhanced stability and robustness. We introduce DETONATE, the first large-scale benchmark of its kind, comprising approximately 100K curated image pairs categorized as chosen and rejected. DETONATE encapsulates three axes of social bias and discrimination: Race, Gender, and Disability. Prompts are sourced from hate speech datasets, with images generated by leading T2I models including Stable Diffusion 3.5 Large, Stable Diffusion XL, and Midjourney. Additionally, we propose the Alignment Quality Index (AQI), a novel geometric measure quantifying latent-space separability of safe/unsafe image activations, revealing hidden vulnerabilities. Empirically, we demonstrate that DPO-Kernels maintain strong generalization bounds via Heavy-Tailed Self-Regularization (HT-SR). DETONATE and complete code are publicly released.
CliME: Evaluating Multimodal Climate Discourse on Social Media and the Climate Alignment Quotient (CAQ)
Apr 04, 2025
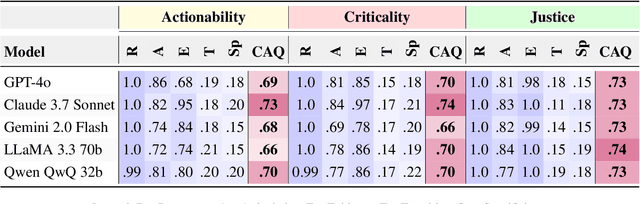
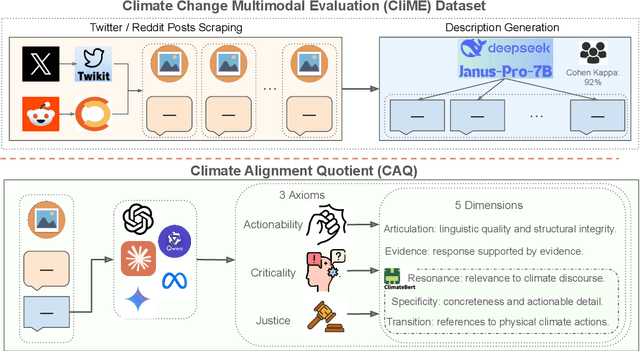

The rise of Large Language Models (LLMs) has raised questions about their ability to understand climate-related contexts. Though climate change dominates social media, analyzing its multimodal expressions is understudied, and current tools have failed to determine whether LLMs amplify credible solutions or spread unsubstantiated claims. To address this, we introduce CliME (Climate Change Multimodal Evaluation), a first-of-its-kind multimodal dataset, comprising 2579 Twitter and Reddit posts. The benchmark features a diverse collection of humorous memes and skeptical posts, capturing how these formats distill complex issues into viral narratives that shape public opinion and policy discussions. To systematically evaluate LLM performance, we present the Climate Alignment Quotient (CAQ), a novel metric comprising five distinct dimensions: Articulation, Evidence, Resonance, Transition, and Specificity. Additionally, we propose three analytical lenses: Actionability, Criticality, and Justice, to guide the assessment of LLM-generated climate discourse using CAQ. Our findings, based on the CAQ metric, indicate that while most evaluated LLMs perform relatively well in Criticality and Justice, they consistently underperform on the Actionability axis. Among the models evaluated, Claude 3.7 Sonnet achieves the highest overall performance. We publicly release our CliME dataset and code to foster further research in this domain.
Visual Counter Turing Test (VCT^2): Discovering the Challenges for AI-Generated Image Detection and Introducing Visual AI Index (V_AI)
Nov 24, 2024



The proliferation of AI techniques for image generation, coupled with their increasing accessibility, has raised significant concerns about the potential misuse of these images to spread misinformation. Recent AI-generated image detection (AGID) methods include CNNDetection, NPR, DM Image Detection, Fake Image Detection, DIRE, LASTED, GAN Image Detection, AIDE, SSP, DRCT, RINE, OCC-CLIP, De-Fake, and Deep Fake Detection. However, we argue that the current state-of-the-art AGID techniques are inadequate for effectively detecting contemporary AI-generated images and advocate for a comprehensive reevaluation of these methods. We introduce the Visual Counter Turing Test (VCT^2), a benchmark comprising ~130K images generated by contemporary text-to-image models (Stable Diffusion 2.1, Stable Diffusion XL, Stable Diffusion 3, DALL-E 3, and Midjourney 6). VCT^2 includes two sets of prompts sourced from tweets by the New York Times Twitter account and captions from the MS COCO dataset. We also evaluate the performance of the aforementioned AGID techniques on the VCT$^2$ benchmark, highlighting their ineffectiveness in detecting AI-generated images. As image-generative AI models continue to evolve, the need for a quantifiable framework to evaluate these models becomes increasingly critical. To meet this need, we propose the Visual AI Index (V_AI), which assesses generated images from various visual perspectives, including texture complexity and object coherence, setting a new standard for evaluating image-generative AI models. To foster research in this domain, we make our https://huggingface.co/datasets/anonymous1233/COCO_AI and https://huggingface.co/datasets/anonymous1233/twitter_AI datasets publicly available.